PIPELINING 1 Outline n n n What is




 n")



 時間 時脈週期 1 2 3 4 F 1 D 1 E 1")






 n Key is to keep the ALU result around ØADD produces R 4")
")
 時間 時脈週期 1 2 F 1 E 1 3 4")


 n Branch delay slot ¨ Compiler has")


 n n Static branch prediction ¨ Fixed prediction for every")

 BNT LNT BT LT 沒有發生分支(BNT) (a) 2 -狀態演算法(1 bit history) BT LNT")
 ¨ we need to know both the branch condition outcome")









 Multiple-issue n Multiple pipeline n Wide bus to cache n Separate Integer’s")

 n In order issue ¨ n Out of order")
/R n Instruction throughput n ¨ Ps n = R/S =")


- Slides: 49
第七章 PIPELINING 1
Outline n n n What is pipelining? The basic pipeline for a RISC instruction set The major hurdle of pipelining – pipeline hazards Data hazards Control hazards Performance 2
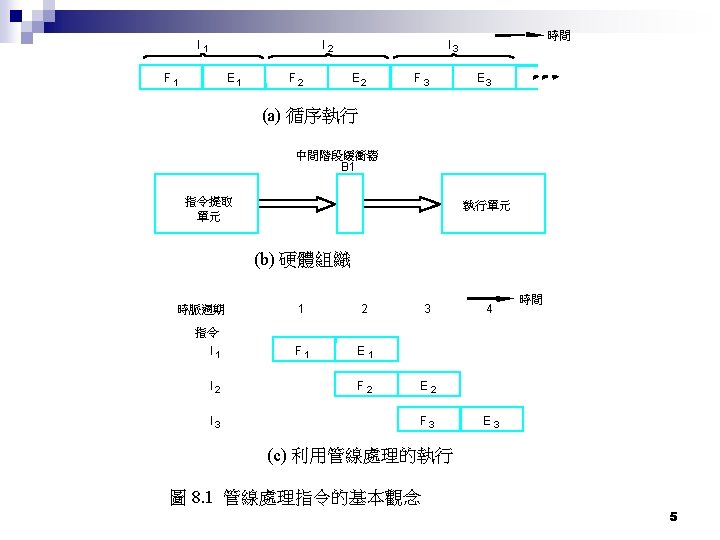
What is pipelining? n Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. ¨ Not n visible to the programmer Each step in the pipeline completes a part of an instruction. ¨ Each step is completing different parts of different instructions in parallel ¨ Each of these steps is called a pipe stage or a pipe segment. 3
What is pipelining? n n Like Assembly line in the factory The time required between moving an instruction one step down the pipeline is a machine cycle. ¨ All the stages must be ready to proceed at the same time ¨ Slowest pipe stage dominates ¨ Machine cycle is usually one clock cycle (sometimes two, rarely more) ¨ The pipeline designer’s goal is to balance the length of each pipeline stage. 4
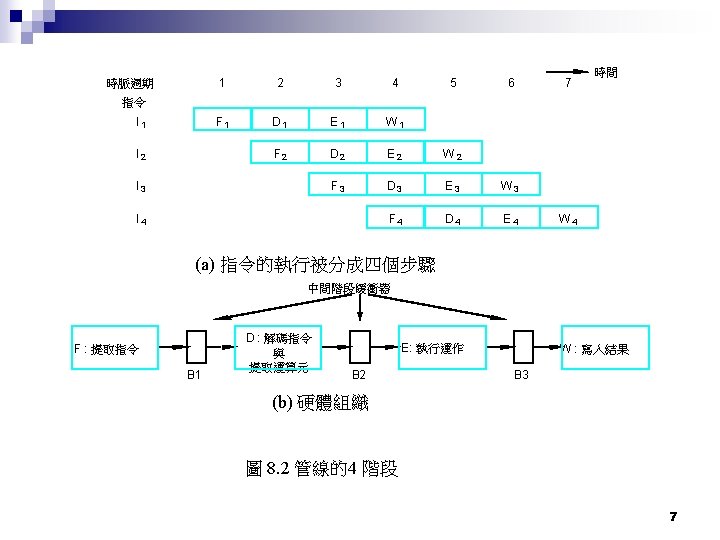
Pipeline Stages Every stage is completed within one cpu clock n F (Fetch) n D (Decode) n E (Execute) n W (Write) n 6
How about the clock of IF ¨ Because all the stages must be completed at the same time, we can not expect IF to access main memory ¨ Thus IF must access L 1 cache ¨ When cache is built in CPU, the access time of cache is almost the same as the time to execute other operations within CPU ¨ Slowest pipe stage dominates 8
Performance of Pipeline n If the stages are perfectly balanced, then the time per instruction on the pipelined machine – assuming ideal conditions--is equal to 9
Pipeline Hazards n Structural hazards ¨ Caused by resource conflict ¨ Possible to avoid by adding resources too costly n – but may be Data hazards ¨ Instruction depends on the results of a previous instruction in a way that is exposed by the overlapping of instructions in the pipeline ¨ Can be mitigated somewhat by a smart compiler n Control hazards ¨ When the PC does not get just incremented ¨ Branches and jumps - not too bad 10
管線可能遇到的問題(data hazard) 時間 時脈週期 1 2 3 4 F 1 D 1 E 1 W 1 5 6 7 8 9 指令 I 1 Stall (拖延) 除法 I 2 I 3 I 4 I 5 F 2 D 2 F 3 E 2 W 2 D 3 E 3 W 3 F 4 D 4 E 4 W 4 F 5 D 5 E 5 圖 8. 3 執行作業耗費一個以上的時序週期所造成的影響 I 3 waits I 2’s result to do ALU 11
Pipeline can not accelerate the execution time of instructions, actually it will prolong the instruction execution time due to the latch added between stages n But pipeline will promote productivity n ¨ Shorten the completion time of one instruction 14
Data Hazard Add R 2, R 3, R 4 n Sub R 5, R 4, R 6 n One instruction’s source registers is the destination register of previous one n 15
Data Hazard 時間 時脈週期 1 2 3 4 F 1 D 1 E 1 W 1 F 2 D 2 5 6 7 8 D 2 A E 2 W 2 D 3 E 3 W 3 F 4 D 4 E 4 9 指令 I 1 (Add) I 2 (Sub) I 3 I 4 F 3 W 4 圖 8. 6 由於 D 2 與 W 1 之間的資料相關性所造成的管線間隔 16
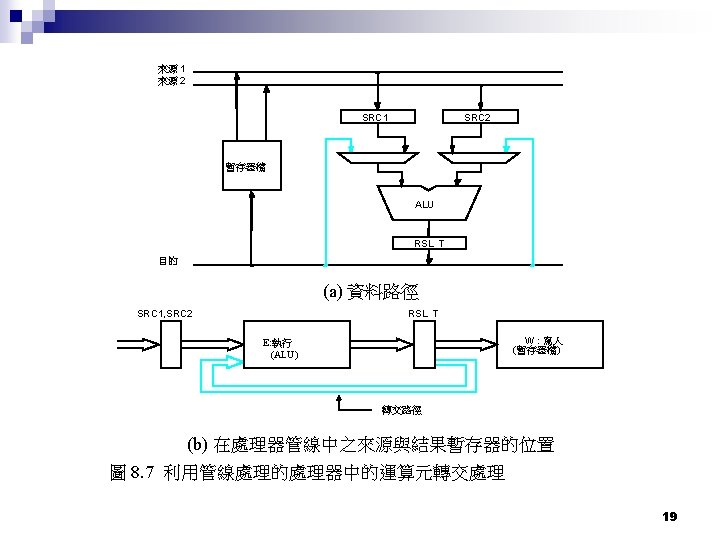
Forwarding also called bypassing, short-circuiting 時間 時脈週期 1 2 3 4 5 F 1 D 1 E 1 W 1 F 2 D 2 E 6 7 8 9 指令 I 1 (Add) I 2 (Sub) I 3 I 4 F 3 D 2 W 2 E 3 3 F 4 D 4 W 3 E 4 W 4 D 2 與 W 1 之間的資料相關性利用forwarding解除間隔(stall) 17
Forwarding(轉交) n Key is to keep the ALU result around ØADD produces R 4 value at ALU output Add R 2, R 3, R 4 ØSUB needs it again at the ALU input Sub R 5, R 4, R 6 n How do we handle this in general? n n ¨ Forwarded value can be at ALU output or Mem stage output 18
Instruction side effect An implicit data hazard n Auto inc/dec addressing mode (push, pop) n Carry flag n Add R 1, R 3 n Addwith. Carry R 2, R 4 n ¨ R 4 [R 2] + [R 4] + carry 20
Control hazards (instruction hazard) 時間 時脈週期 1 2 F 1 E 1 3 4 5 6 指令 I 1 I 2 (分支) I 3 Ik I k+1 F 2 執行單元閒置 E 2 F 3 Branch penalty X Fk Ek Fk+1 Ek+1 圖 8. 8 分支指令所造成的閒置週期 21
時脈週期 1 2 3 4 I 1 F 1 D 1 E 1 W 1 F 2 D 2 E 2 F 3 D 3 X F 4 X I 2 (分支) I 3 I 4 Fk Ik I k+ 5 6 7 8 Dk Ek W F k+ 1 1 D k+ 1 E k+ 時間 k 1 (a) 在 Execute 階段中計算分支位址 時脈週期 1 2 3 4 I 1 F 1 D 1 E 1 W 1 F 2 D 2 I 2 (分支) F 3 I k+ 6 7 Dk Ek W 時間 X Fk Ik 5 F k+ 1 1 D k+ 1 E k+ k 1 (b) 在 Decode 階段中計算分支位址(減少branch penalty) 圖 8. 9 分支時序 22
Branch Instructions 20% of Dynamic execution is branch instructions, that is, every 5 instructions been executed has one branch n Branch has huge impact on pipeline, thus modern CPU has various strategies to handle this control hazard such as delay branch, branch prediction, branch folding n 24
Delayed branch (make the stall cycle useful) n Branch delay slot ¨ Compiler has to find instructions to fill in the slot(85% complex compiler technique can handle one delay slot) ¨ Maybe more than one slot, but it is hard for compiler to locate suitable instructions to fill in. n Compiler need to find an instruction which is always executed to fill in the slot whether the branch is taken or not 25
LOOP NEXT Shift_left Decrement Branch=0 Add R 1 R 2 LOOP R 1, R 3 (a) 原來的程式迴圈 LOOP NEXT Decrement Branch=0 Shift_left Add R 2 LOOP R 1, R 3 Branch delay slot (b) 重新排序過的指令 圖 8. 12 為延遲分支重新排序的指令 26
Branch prediction (Speculative execution) n n Static branch prediction ¨ Fixed prediction for every branch ¨ Branch taken ¨ Branch not taken Dynamic branch prediction ¨ branch-prediction buffer ¨ Branch target buffer (BTB) 28
Branch-prediction buffer ¨ this buffer contains a bit as to whether the branch was last taken or not (1 time history) ¨ upon fetching the instruction, we also fetch the prediction bit (from a special cache) ¨ if the bit is set, we predict that the branch is taken ¨ if the bit is not set, we predict that the branch is not taken 29
發生分支 (BT) BNT LNT BT LT 沒有發生分支(BNT) (a) 2 -狀態演算法(1 bit history) BT LNT SNT BNT BT ST: strongly taken LT: likely taken LNT: likely not taken SNT: strongly not taken BT LT ST BT BNT (b) 4 -狀態演算法 (2 bit history) Better Approach 圖 8. 15 分支預測演算法的狀態機表示法 30
Branch target buffer (BTB) ¨ we need to know both the branch condition outcome and the branch address by the end of the IF stage n we need to know where we are branching to before we have even decode the instruction as a branch! ¨ doesn’t seem possible, but we will use a prediction buffer like before but enhanced: ¨ We will use a branch-target buffer n This will store for a given branch prediction of the branch outcome ¨ and if the branch is taken, the predicted branch target ¨ 31
The Target Buffer Send PC of current instruction to target buffer in IF stage If we get a hit (PC is in the table) then look up the predicted PC and branch prediction If predict taken, then update the PC with the predicted PC in the buffer otherwise increment PC as usual On a branch miss or misprediction, update the buffer by moving missing PC into buffer, or updating predicted PC/branch prediction bit Thus, we predict the branch location before we have even decoded the current instruction to see if it is a branch! 32
Branch Folding n Notice that by using the branch target buffer ¨ we are fetching the new PC value (or the offset for the PC) from the buffer ¨ and then updating the PC ¨ and then fetching the branch target location instruction n n Instead, why not just fetch the next instruction? In Branch folding, the buffer stores the instruction at the predicted location ¨ If we use this scheme for unconditional branches, we wind up with a penalty of – 1 (we are in essence removing the unconditional branch) ¨ Note: for this to work, we must also update the PC, so we must store both the target location and the target instruction 33 n this approach won’t work well for conditional branches
Power. PC 601 architecture 34
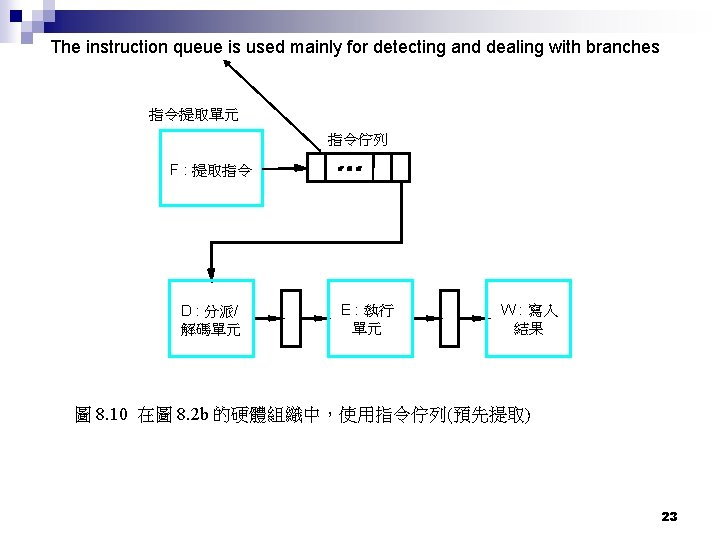
Branch folding n n The instruction queue is used mainly for detecting and dealing with branches. The 601's branch unit scans the bottom four entries of the queue, identifying branch instructions and determining what type they are (conditional, unconditional, etc. ). In cases where the branch unit has enough information to resolve the branch right then and there (e. g. in the case of an unconditional branch, or a conditional branch whose condition is dependent on information that's already in the condition register) then the branch instruction is simply deleted from the instruction queue and replaced with the instruction located at the branch target. This branch-elimination technique, called branch folding, speeds performance in two ways. First, it eliminates an instruction (the branch) from the code stream, which frees up dispatch bandwidth for other instructions. Second, it eliminates the single-cycle pipeline bubble that usually occurs immediately after a branch. 35
Pipeline and addressing mode Complex addressing mode doesn’t save any clock cycle than simple addressing mode n Load (X(R 1)), R 2 complex addressing mode n n Add #X, R 1, R 2 Load (R 2), R 2 simple addressing mode 36
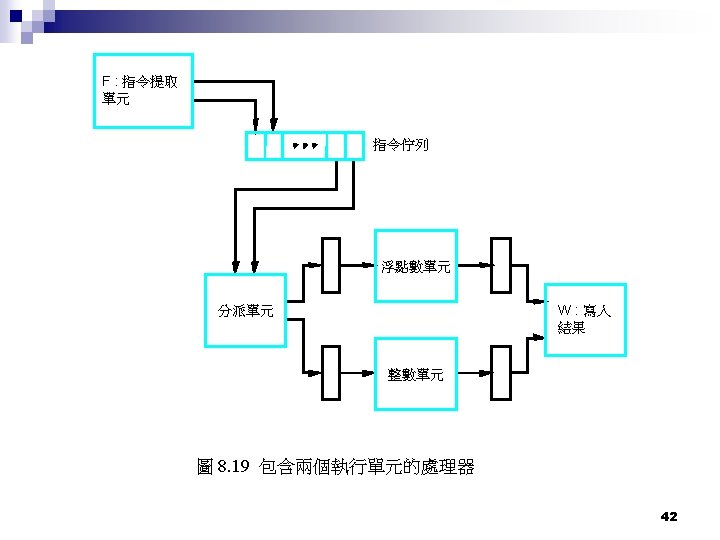
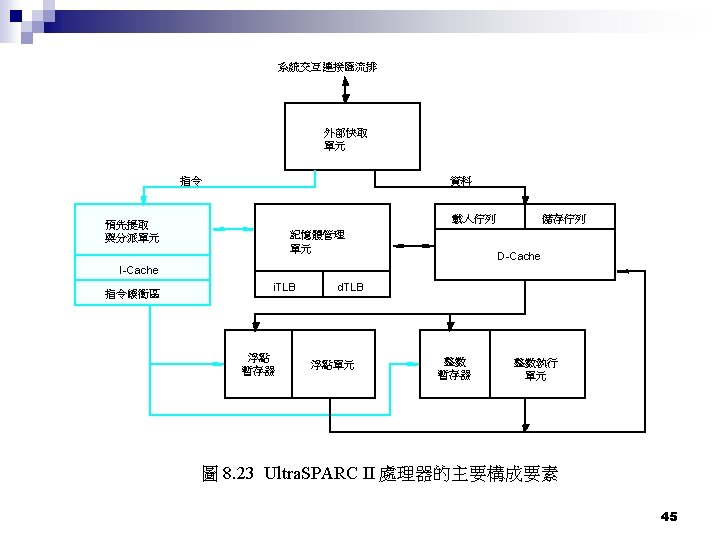
超純量作業 (superscalar) Multiple-issue n Multiple pipeline n Wide bus to cache n Separate Integer’s Execute Unit and Floating’s Execute Unit n Usually multiple IEUs, FEUs n 41
Out of order execution (脫序的執行) n In order issue ¨ n Out of order execution ¨ n To avoid dead lock Reorder buffer In order retire Register renaming ¨ Temporary registers for commitment ¨ n Imprecise exception ¨ n Allow instructions completion after exception instruction Precise exception ¨ instructions completion after exception instruction are aborted 44
效能考量 T=(N x S)/R n Instruction throughput n ¨ Ps n = R/S = N/T 一秒所能執行的指令數 Only one L 1 cache ¨ Dmiss = ((1 -hi) + d(1 -hd)) x Mp n Dmiss = (0. 05 + 0. 03) x 17 = 1. 36 cycles n L 1, L 2 cache ¨ Dmiss = ((1 -hi) + d(1 -hd)) x (hs x Ms + (1 -hs) x Mp) = 0. 46 cycles 47
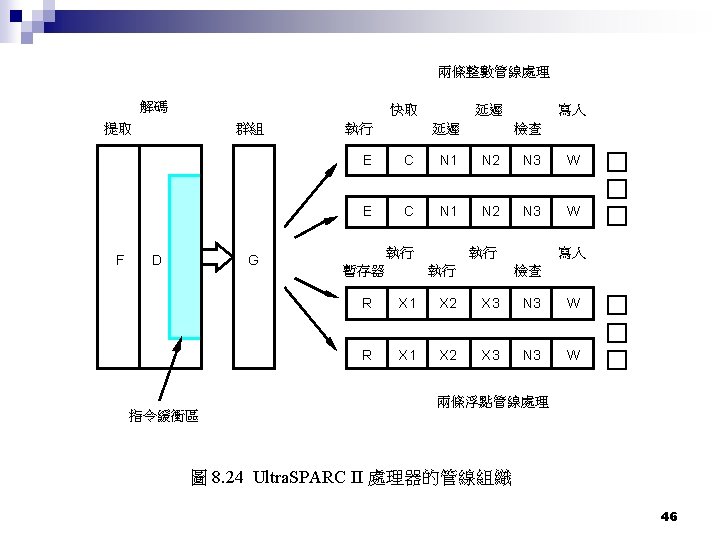
管線階段的數目 較遠的指令在管線中形成相關性 n 管線變長, 分支的損失更嚴重 n 成本增加 n Ultra. SPARC II 9 stages n Intel Pentium pro 12 stages n Pentium 4 12 stages n 48