PHILOSOPHY OF SCIENCE NeymanPearson approach Jerzy Neyman Egon





: Probabilities are strictly long-run relative frequencies –")


 The probability of our hypothesis given the data")
 is the inverse of the conditional probability p(D|H) Inverting conditional probabilities makes a")






 Estimate the size of effect you think is plausible")
 Google “Gpower” 2) First site to come up is the one you want:")






 For a within-subject comparison we need to know the standard deviation of the")




 \"After")










 approaches do not depend on when you planned to stop")
 Have the authors determined what difference (or range of differences) would be")


")


- Slides: 55
PHILOSOPHY OF SCIENCE: Neyman-Pearson approach Jerzy Neyman Egon Pearson April 16, 1894 August 5, 1981 11 August 1895 12 June 1980 Zoltán Dienes
'The statistician cannot excuse himself from the duty of getting his head clear on the principles of scientific inference, but equally no other thinking person can avoid a like obligation' Fisher 1951
Prior to 1930 s: There were many statistical procedures But no coherent account of what they achieved or of how to choose the right test. Neyman and Pearson put the field of statistics on a firm logical footing It is now orthodoxy (but note: there are passionate attacks on just how firm their logical footing is!)
What is probability? Relative frequency interpretation Need to specify a collective of elements – like throws of a dice. In the long run – as number of observations goes to infinity – the proportion of throws of a dice showing a 3 is 1/6 The probability of a ‘ 3’ is 1/6 because that is the long run frequency of ‘ 3’s relative to all throws
One cannot talk about the probability of a hypothesis e. g. “this cancer drug is more effective than placebo” being true “genes are coded by DNA” is not true 2/3 of the time in the long run – it is just true. There is no relevant long run. A hypothesis is just true or false. When we say what the probability of a hypothesis is, we are referring to a subjective probability
Neyman-Pearson (defined the philosophy underlying standard statistics): Probabilities are strictly long-run relative frequencies – not subjective! Statistics do not tell us the probability of your theory or the null hypothesis being true. So what relative frequencies are we talking about?
If D = some data and H = a hypothesis For example, H = this drug is just a placebo cure for depression Some data: mean difference for 50 people in happiness between placebo and drug conditions (e. g. 2 units), t = 2. One can talk about p(D|H) The probability of the data given the hypothesis e. g. p(“ 50 people being on average happier with drug rather than placebo, with t > 2” |’drug is a placebo’)
A collective or reference class we can use: the elements are ‘measuring the happiness of each of 50 people in drug and placebo conditions’ given the drug operates just as a placebo. Consider a hypothetical collective of an infinite number of such experiments. In how many hypothetical experiments would the t value be above 2? That is a meaningful probability we can calculate.
One can NOT talk about p(H|D) The probability of our hypothesis given the data e. g. p(‘my drug is a placebo’| ‘t value > 2’) What is the reference class? ? The hypothesis is simply true or false.
P(H|D) is the inverse of the conditional probability p(D|H) Inverting conditional probabilities makes a big difference e. g. P(‘dying within two years’|’head bitten off by shark’) = 1 P(‘head was bitten off by shark’|’died in the last two years’) ~ 0 P(A|B) can have a very different value from P(B|A)
Statistics cannot tell us how much to believe a certain hypothesis. All we can do is set up decision rules for certain behaviours – accepting or rejecting hypotheses – such that in following those rules in the long run we will not often be wrong. E. g. Decision procedure: Run 40 subjects and reject null hypothesis if t-value larger than a critical value
Our procedure tells us our long term error rates BUT it does not tell us which particular hypotheses are true or false or assign any of the hypotheses a probability. All we know is our long run error rates.
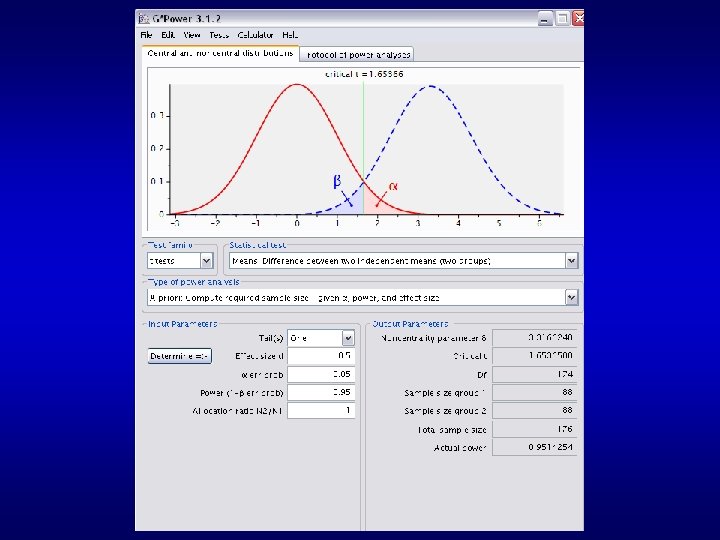
State of World: Decision: Ho true Accept Ho Reject Ho Ho false Type II error Type I error Need to control both types of error: α = p(rejecting Ho|Ho) β = p(accepting Ho|Ho false)
Consider a year in which of the null hypotheses we test, 4000 are actually true and 1000 actually false. State of World ______________ Decision H 0 true H 0 false __________________________ Accept H 0 3800 500 Reject H 0 200 500 ______________ 4000 α = ? β = ? 1000
State of World: Decision: Ho true Ho false Accept Ho Reject Ho Type II error Type I error Need to control both types of error: α = p(rejecting Ho/Ho) β = p(accepting Ho/Ho false) power: P(‘getting t as extreme or more extreme than critical’/Ho false) Probability of detecting an effect given an effect really exists in the population. ( = 1 – β)
Decide on allowable α and β BEFORE you run the experiment. e. g. set α =. 05 as per normal convention Ideally also set β =. 05. α is just the significance level you will be testing at. But how to control β?
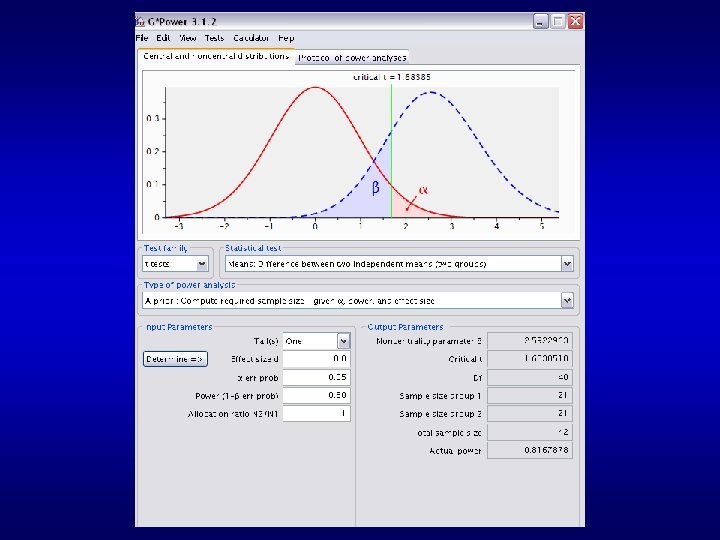
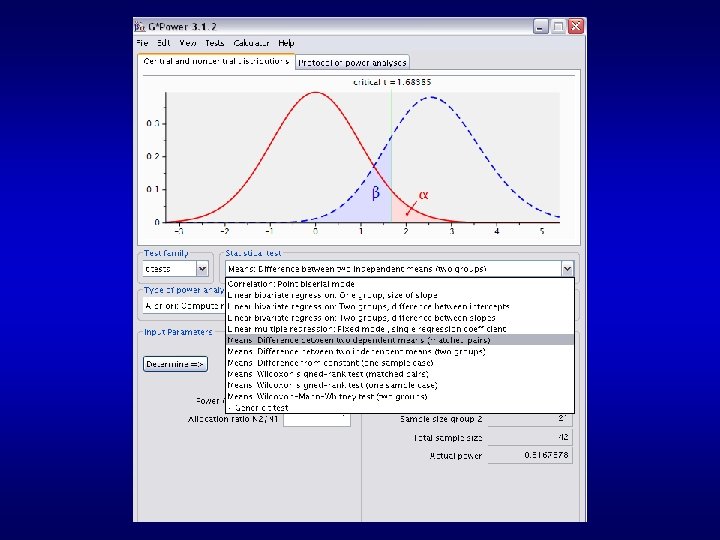
Controlling β: Need to 1) Estimate the size of effect you think is plausible or interesting given your theory is true 2) Power tables or online programs tell you how many subjects you need to run to keep β to. 05 (equivalently, to keep power at 0. 95) Good free software is Gpower
1) Google “Gpower” 2) First site to come up is the one you want: http: //www. psycho. uni-duesseldorf. de/aap/projects/gpower/ 3) Download and install on your PC
To calculate power must determine what minimal difference would be interesting or would confirm theory How can one tell what difference that should be? ?
To calculate power must determine what minimal difference would be interesting or would confirm theory How can one tell what difference that should be? ? Must know your literature. If the study is based on a theory which produced a certain size effect in another paper you can use that effect to give you an idea
Example: A theory predicts that prejudice between ethnic groups can be reduced by making both racial groups part of the same ingroup. A manipulation for reducing prejudice following this idea: imagining being members of the same sports team. A control group: imagining playing a sport with no mention of the ethnic group. You have a measure of prejudice (IAT, rating scale, questionnaire, etc), but what size effect could be expected?
In previous research, instead of imagining the scenario, participants actually engaged in a common activity. A reduction in prejudice on the same scale was obtained of x units on a rating scale. Rough expectation: A reduction in prejudice of 1/2 x to x units
As well as the absolute difference between conditions, need to know the standard deviation of the scores: 1) For a between group comparison need to know the standard deviation within a group To get an estimate from a previous study, find the “pooled standard deviation” If SD 1 is standard deviation in group 1 and SD 2 in group 2: SDpooled = square root of the average of SD 1 squared and SD 2 squared
Cohen’s d = minimum interesting difference / SDpooled Cohen’s rough guide: 0. 2 small 0. 5 medium 0. 8 large
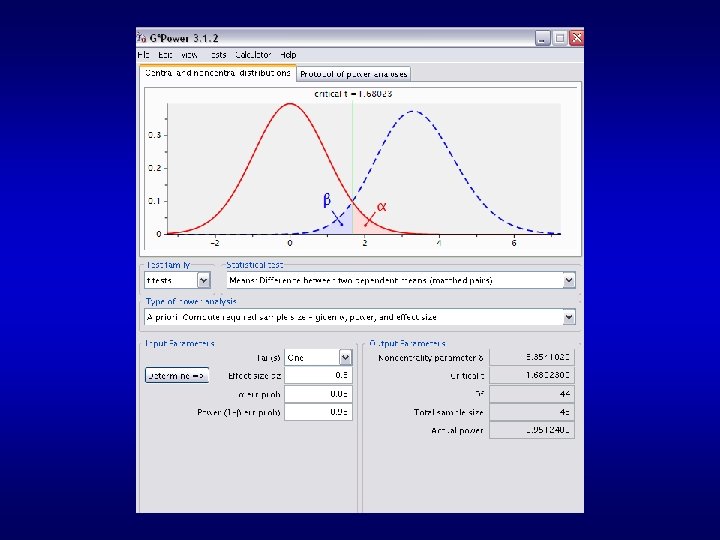
2) For a within-subject comparison we need to know the standard deviation of the difference scores, SDdiff How to get this? ? For within subjects, SEdiff = SDdiff/square root N Where N is number of subjects IN general, t = mean difference/SEdiff so SEdiff = mean difference/t For within subjects, SDdiff = SEdiff * squareroot N
Cohen’s dz = mean difference / SDdiff Cohen’s rough guide: 0. 1 small 0. 25 medium 0. 4 large
Most studies do not calculate power! But they should. Strict application of the Neyman-Pearson logic means setting the risks of both Type I and Type II errors in advance (α and β). Most researchers are extremely worried about Type I errors (false positives) i. e. whether p <. 05 but allow Type II errors (false negatives) to go uncontrolled. Leads to inappropriate judgments about what results mean and what research should be done next.
You read a review of studies looking at whether meditation reduces depression. 100 studies have been run and 50 are significant in the right direction and the remainder are non-significant. What should you conclude?
You read a review of studies looking at whether meditation reduces depression. 100 studies have been run and 50 are significant in the right direction and the remainder are non-significant. What should you conclude? If the null hypothesis were true, how many would be significant? How many significant in the right direction?
"The continued very extensive use of significance tests is alarming. " (Cox 1986) "After four decades of severe criticism, the ritual of null hypothesis significance testing---mechanical dichotomous decisions around a sacred. 05 criterion---still persist. “ “[significance testing] does not tell us what we want to know, and. . out of desperation, we nevertheless believe that it does!" (Cohen 1994)
“statistical significance testing retards the growth of scientific knowledge; it never makes a positive contribution” (Schmidt & Hunter, 1997, p. 37). “The almost universal reliance on merely refuting the null hypothesis is a terrible mistake, is basically unsound, poor scientific strategy, and one of the worst things that ever happened in the history of psychology” (Meehl, 1978, p. 817).
A lot of criticism arises because most researchers do not follow the Neyman and Pearson demands in a sensible way e. g. habitually ignoring power (and confidence intervals) BUT The (orthodox) logic of Neyman and Pearson is also controversial
To summarise: You are allowed to draw a back and white conclusion when the decision procedure has known low error rates Anything that affects the error rates of your decision procedure affects what decisions you can draw
In general: The more opportunities you give yourself to make an error the higher the probability of an error becomes. So you must correct for this. E. g. Multiple tests: If you perform two t-tests the overall probability of an error is increased
Multiple tests: Testing the elderly vs the middle aged AND the middle aged vs the young That’s two t-tests so for the overall Type I rate to be controlled at. 05 could conduct each test at the. 025 level. If one test is. 04, would reject the null if just doing that one test but accept the null if doing two tests.
Cannot test your data once at. 05 level Then run some more subjects And test again at. 05 level Type I error rate is no longer. 05 because you gave yourself two chances at declaring significance. Each test must be conducted at a lower p-value for the overall error rate to be kept at. 05. Does that make sense? Should our inferences depend on what else we might have done or just on what the data actually are?
If when they stopped collecting data depends on who has the better kung fu Then the mathematically correct result depends on whose kung fu is better!
The mathematically correct answer depends on whose unconscious wish to please the other is strongest!!
The Bayesian (and likelihood) approaches do not depend on when you planned to stop running subjects, whether you conduct other tests, or whether the test is planned or post hoc!
Assignment: 6) Have the authors determined what difference (or range of differences) would be expected if theory were true? 7) If not, do you know any results or other papers that could allow you to state an expected size of difference? Provide an expected difference and state your reasons. 8) Have the authors established their sensitivity to pick up such a difference, through power or confidence intervals? If not, provide a calculation yourself.
The Neyman-Pearson approach is not just about null hypothesis testing. One can also calculate confidence intervals: Find the set of all values of the DV non-significantly different from your sample value.
confidence intervals: Find the set of all values of the DV non-significantly different from your sample value. E. g. I measure blood pressure difference before and after taking a drug. Sample mean difference is 4 units That may be just significantly different (at 5% level) from – 1 units and also from +9 units. So the “ 95% confidence interval” is: . . . -3 – 2 – 1 0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +10 +11. . . Mean diff + tcrit * SEdiff Mean diff - tcrit * SEdiff All these points are nonsignificantly different from the sample mean
These points, out to infinity either way, are significantly different (at the 5% level) from the sample mean, so can be rejected as possible population values. . . -3 – 2 – 1 0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +10 +11. . . As all these points are nonsignificantly different from the sample mean, they cannot be ruled out as population values
If the paper obtained a null result, does the confidence interval include the minimal interesting effect size you identified? If so, the study is insensitive and the null result is not evidence against theory If the interval excludes interesting effect sizes, the null result is evidence against theory
Good stopping rule for running a study: If x is the minimally interesting effect size Run subjects until confidence interval has width a smidgen less than x Then if interval includes 0 it excludes x and vice versa So you can definitely draw a firm conclusion It turns out that for this procedure, for a 95% confidence interval, Alpha = 5% Beta = 5%