Part 3 European Social Survey 2002 Variable names

Part 3: European Social Survey 2002

Variable names
 Data Editor as initialised:")
European Social Survey 2002 (GB only) Data Editor as initialised:

Making it easier to find your way round the file • Get a copy of the questionnaire! • Modify variable labels to put question number at beginning • Adjust columns to necessary basics • Change variable names to make them easier to find

You could rewrite all the variable labels from scratch, but for now it was easier to modify them inside the Data Editor

European Social Survey 2002 - GB only Data Editor after modifying variable labels
")
Change variable names rename variables (tvtot to pplhlp = a 1 to a 10) (dscrrce to dscroth = c 17_1 to c 17_10) (dscrdk to dscrna = c 17_dk, c 17_ref, c 17_nap, c 17_na) [The lines in red are for variables used in later examples]

Data Editor with new variable names

Adjust column widths to see more of variable and value labels and mask unneeded columns

Variable labels

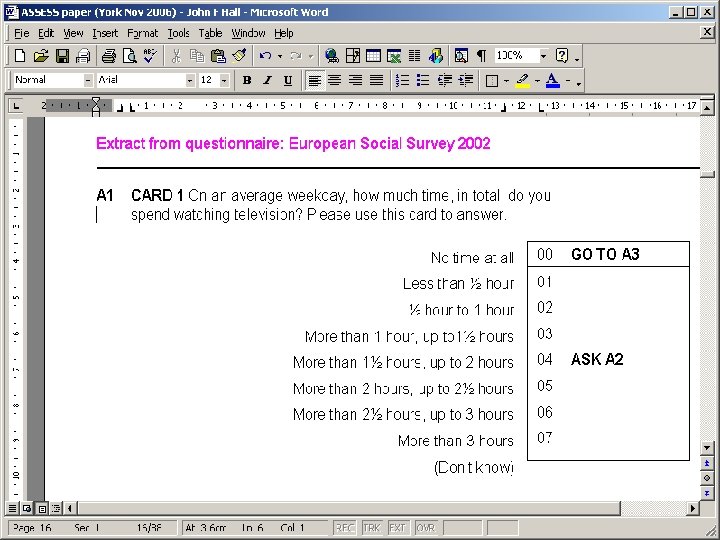
An example of awkward labelling European Social Survey 2002

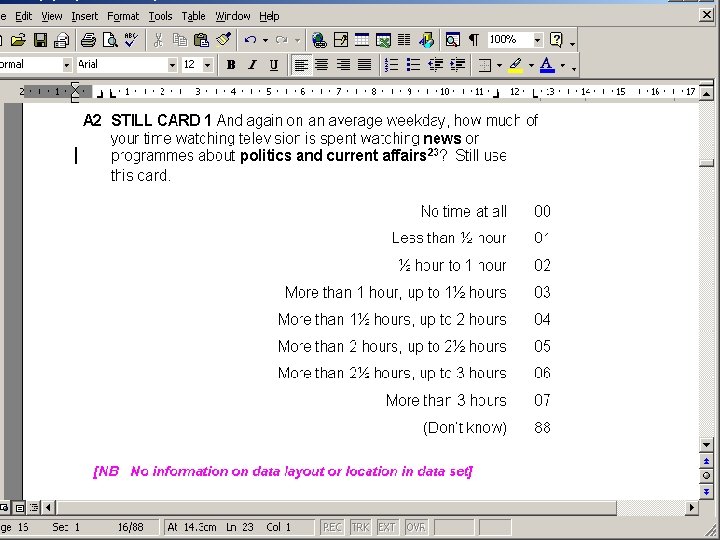
ASK ALL C 16 Would you describe yourself as being a member of a group that is discriminated against in this country? Yes No 2 GO TO C 18 (Don’t know) 1 8 C 17 On what grounds is your group discriminated against? PROBE: ‘What other grounds? ’ CODE ALL THAT APPLY Colour or race Nationality 02 Religion Language Ethnic group Age Gender Sexuality Disability Other (WRITE IN)______________ (Don’t know) 01 03 04 05 06 07 08 09 10 88 ASK C 17
")
This is an example of a multiple response question (with a preceding filter)

Problems for secondary researcher • • • no indication of data layout mnemonic variable names long variable labels with no question number redundant information at the beginning useful information at the end (and gets lost) binary value labels (0, 1)

Back to the Data Editor as initialised
 Could be these:")
Here’s what I mean (after scrolling around looking for likely candidates) Could be these: can’t make head or tail of them took a while to find them.

How do I find the right variables? • Adjust column widths as before • Make Label column even wider to reveal labels in full • Scroll down searching for candidates

Data Editor after widening the Label column to reveal variable labels in full This is a sign of lack of experience in SPSS!

How to solve the problem? • Step 1: Add question number and response code to beginning of variable labels • Step 2: Change variable names • Step 3: Get rid of redundant information at beginning of variable labels

Step 1: add question number and response code to beginning of variable label but still with mnemonic variable names

Step 2: change variable names

but there’s far too much redundant information at the beginning of the variable labels and the value labels are binary (0, 1) not 0 -10, 88 as on questionnaire

Step 3: lose redundant info in labels

How do we analyse this question? You could run separate frequency counts for each variable, and then add them all up, but it’s far better to use the SPSS command MULT RESPONSE
 from several")
Mult response • Creates a temporary group variable (which cannot be saved) from several variables • In binary mode it uses a single value across all variables in the group and prints tables with variable labels • In general mode it uses a range of values across all variables in the group and prints tables with value labels

To run SPSS multiple response in binary mode on the original data mult response groups = discrim 'Reasons for perceived discrimination' (dscrrce to dscrna (1)) /freq discrim.
 Dichotomy")
… which produces: Group DISCRIM Reasons for perceived discrimination (Value tabulated = 1) Dichotomy label Discrimination Discrimination Discrimination Discrimination Name of of of of respondent's respondent's respondent's respondent's group: group: group: group: co na re la et ag ge se di ot do re no DSCRRCE DSCRNTN DSCRRLG DSCRLNG DSCRETN DSCRAGE DSCRGND DSCRSEX DSCRDSB DSCROTH DSCRDK DSCRREF DSCRNAP Total responses 0 missing cases; 2, 052 valid cases Count 82 28 44 5 21 50 37 18 18 74 1 1 1771 ------2150 Pct of Responses Cases 3. 8 1. 3 2. 0. 2 1. 0 2. 3 1. 7. 8. 8 3. 4. 0. 0 82. 4 ----100. 0 4. 0 1. 4 2. 1. 2 1. 0 2. 4 1. 8. 9. 9 3. 6. 0. 0 86. 3 ----104. 8

To run SPSS multiple response in binary mode on the modified data mult response groups = discrim 'Reasons for perceived discrimination' (c 17_1 to c 17_nap (1)) /freq discrim.
 Dichotomy")
…not much clearer! Group DISCRIM Reasons for perceived discrimination (Value tabulated = 1) Dichotomy label Name C 17 -1: Discrimination of respondent's gr C 17 -2: Discrimination of respondent's gr C 17 -3: Discrimination of respondent's gr C 17 -4: Discrimination of respondent's gr C 17 -5: Discrimination of respondent's gr C 17 -6: Discrimination of respondent's gr C 17 -7: Discrimination of respondent's gr C 17 -8: Discrimination of respondent's gr C 17 -9: Discrimination of respondent's gr C 17 -10: Discrimination of respondent's g C 17 -DK: Discrimination of Respondent's g C 17 -ref: Discrimination of respondent's C 17 -nap: Discrimination of respondent's DSCRRCE DSCRNTN DSCRRLG DSCRLNG DSCRETN DSCRAGE DSCRGND DSCRSEX DSCRDSB DSCROTH DSCRDK DSCRREF DSCRNAP Total responses 0 missing cases; 2, 052 valid cases Count 82 28 44 5 21 50 37 18 18 74 1 1 1771 ------2150 Pct of Responses Cases 3. 8 1. 3 2. 0. 2 1. 0 2. 3 1. 7. 8. 8 3. 4. 0. 0 82. 4 ----100. 0 4. 0 1. 4 2. 1. 2 1. 0 2. 4 1. 8. 9. 9 3. 6. 0. 0 86. 3 ----104. 8

…shortening the labels helps, but now the variable name is in twice! Group DISCRIM Reasons for perceived discrimination (Value tabulated = 1) Dichotomy label Name C 17 -1: Discrimination: colour or race C 17 -2: Discrimination: nationality C 17 -3: Discrimination: religion C 17 -4: Discrimination: language C 17 -5: Discrimination: ethnic group C 17 -6: Discrimination: age C 17 -7: Discrimination: gender C 17 -8: Discrimination: sexuality C 17 -9: Discrimination: disability C 17 -10: Discrimination: other grounds C 17 -DK: Discrimination: don't know C 17 -ref: Discrimination: refusal C 17 -nap: Discrimination: not applicable C 17_1 C 17_2 C 17_3 C 17_4 C 17_5 C 17_6 C 17_7 C 17_8 C 17_9 C 17_10 C 17_DK C 17_REF DSCRNAP Total responses 0 missing cases; 2, 052 valid cases Count 82 28 44 5 21 50 37 18 18 74 1 1 1771 ------2150 Pct of Responses Cases 3. 8 1. 3 2. 0. 2 1. 0 2. 3 1. 7. 8. 8 3. 4. 0. 0 82. 4 ----100. 0 4. 0 1. 4 2. 1. 2 1. 0 2. 4 1. 8. 9. 9 3. 6. 0. 0 86. 3 ----104. 8

There’s another way of doing it which is much better • Temporarily change the codes from binary to sequential • Disable missing values • Add value labels (first variable only) • Use MULT RESPONSE in general mode
 you can")
As a check on initial values (and not just for this example) you can use list var c 17_1 to c 17_10 / cases 5.
 C")
List C 17_1 to C 17 -10 before recoding (first 5 cases only) C 17_1 C 17_2 C 17_3 C 17_4 C 17_5 C 17_6 C 17_7 C 17_8 C 17_9 C 17_10 1 1 0 0 0 0 1 0 0 0 Number of cases read: 0 1 0 0 0 5 0 0 0 1 0 0 0 0 Number of cases listed: 0 0 1 5

Step 1: Temporarily change values from binary to sequential temp. recode c 17_1 to c 17_10 /c 17_2 /c 17_3 /c 17_4 /c 17_5 /c 17_6 /c 17_7 /c 17_8 /c 17_9 /c 17_10 /c 17_dk /c 17_ref /c 17_nap /c 17_na (6 thru hi = sysmis) (1=2) (1=3) (1=4) (1=5) (1=6) (1=7) (1=8) (1=9) (1=10) (1=11) (1=12) (1=13) (1=14).
 C")
List C 17_1 to C 17 -10 after recoding (first 5 cases only) C 17_1 C 17_2 C 17_3 C 17_4 C 17_5 C 17_6 C 17_7 C 17_8 C 17_9 C 17_10 1 1 0 0 2 0 0 3 0 0 4 0 0 0 Number of cases read: 0 5 0 0 0 0 0 7 0 0 0 0 Number of cases listed: 0 0 * 5 (NB: the * = 10: it would print with format F 2. 0)
.")
Step 2: Disable missing values c 17_1 to c 17_na ( ).
 value labels c 17_1")
Step 3: Specify new value labels (1 st variable only) value labels c 17_1 (1) 'Colour or race' (2) 'Nationality' (3) 'Religion' (4) 'Language' (5) 'Ethnic group' (6) 'Age' (7) 'Gender' (8) 'Sexuality' (9) 'Disability' (10) 'Other' (11) "Don't know" (12) 'Refusal' (13) 'Not applicable' (14) 'No answer'.

Step 4: Specify group variable and get frequency count mult response groups = discrim 'Q 17: Perceived reasons for discrimination' (c 17_1 to c 17_nap (1, 14)) /freq discrim.
 Group")
Perceived reasons for discrimination This is much clearer (if you can read it!) Group DISCRIM Q 17 Perceived reasons for discrimination Category label Code Count Colour or race Nationality Religion Language Ethnic group Age Gender Sexuality Disability Other Don't know Refusal Not applicable 1 2 3 4 5 6 7 8 9 10 11 12 13 82 28 44 5 21 50 37 18 18 74 1 1 1771 ------2150 Total responses 0 missing cases; 2, 052 valid cases Pct of Responses Cases 3. 8 1. 3 2. 0. 2 1. 0 2. 3 1. 7. 8. 8 3. 4. 0. 0 82. 4 ----100. 0 4. 0 1. 4 2. 1. 2 1. 0 2. 4 1. 8. 9. 9 3. 6. 0. 0 86. 3 ----104. 8

To produce the table only for those who actually answered the question, we simply change the mult response command to: mult response groups = discrim 'Q 17: Perceived reasons for discrimination' (c 17_1 to c 17_10 (1, 10)) /freq discrim.
 Group DISCRIM C 17 Perceived reasons for")
Perceived reasons for discrimination (valid cases only) Group DISCRIM C 17 Perceived reasons for discrimination Category label Code Count Colour or race Nationality Religion Language Ethnic group Age Gender Sexuality Disability Other 1 2 3 4 5 6 7 8 9 10 82 28 44 5 21 50 37 18 18 74 ------377 Total responses 1, 773 missing cases; 279 valid cases Pct of Responses Cases 21. 8 7. 4 11. 7 1. 3 5. 6 13. 3 9. 8 4. 8 19. 6 ----100. 0 29. 4 10. 0 15. 8 1. 8 7. 5 17. 9 13. 3 6. 5 26. 5 ----135. 1

Here endeth the third lesson
- Slides: 44