Parallel Programming Open MP Scan Work Complexity and



 • The prefix sum or scan operation is useful for computing")

 • Example: Given the following array, compute the prefix")
 • Example: Given the following array, compute the prefix")
![Naïve Prefix Sum (Exclusive Scan) Algorithm int arr[N] = {7, 2, 3, 1, 9,](https://slidetodoc.com/presentation_image_h/74c0ad266727010b09bac1adb7ac9a40/image-8.jpg "Naïve Prefix Sum (Exclusive Scan) Algorithm int arr[N] = {7, 2, 3, 1, 9,")

; int")
 { two_i_1 = 1")
 { two_i_1 =")
 additions")
 • Goal – build a scan algorithm that")
 { two_i_p")

![Blelloch Algorithm – Down Sweep scan. Sum[N-1] = 0; for(i = log_of_N_1; i >=](https://slidetodoc.com/presentation_image_h/74c0ad266727010b09bac1adb7ac9a40/image-19.jpg "Blelloch Algorithm – Down Sweep scan. Sum[N-1] = 0; for(i = log_of_N_1; i >=")
 operations, giving the appearance")
- Slides: 20
Parallel Programming – Open. MP, Scan, Work Complexity, and Step Complexity David Monismith CS 599 Based upon notes from GPU Gems 3, Chapter 39 http: //http. developer. nvidia. com/GPUGems 3/gpugem s 3_ch 39. html
Work Complexity • In terms of data how many or what order of operations (Big-Oh) are required to perform a particular algorithm • Example – summation • Given an array of n elements, it takes O(n) operations to find the sum of those elements on a single core processor. • We want parallel algorithms to be work efficient – to take the same amount of work (operations) as the serial version. • This means that a parallelized version of sum should take O(n) operations (additions) to finish.
Reduction Work Complexity • Recall – we have studied reduction • In class we have seen that a sum reduction takes O(n) work to run to completion. • The sum reduction takes the same order of work (operations) to complete as the serial version. • Therefore, we say a sum reduction is workefficient.
Prefix Sum (Scan) • The prefix sum or scan operation is useful for computing cumulative sums. • Example: Given the following array, compute the prefix sum. +---+---+---+ |7|2|3|1|9|2| +---+---+---+ 0 1 2 3 4 5
Uses for Scan • • • Sorting Lexical Analysis String Comparison Polynomial Evaluation Stream Compaction Building Histograms and Data Structures
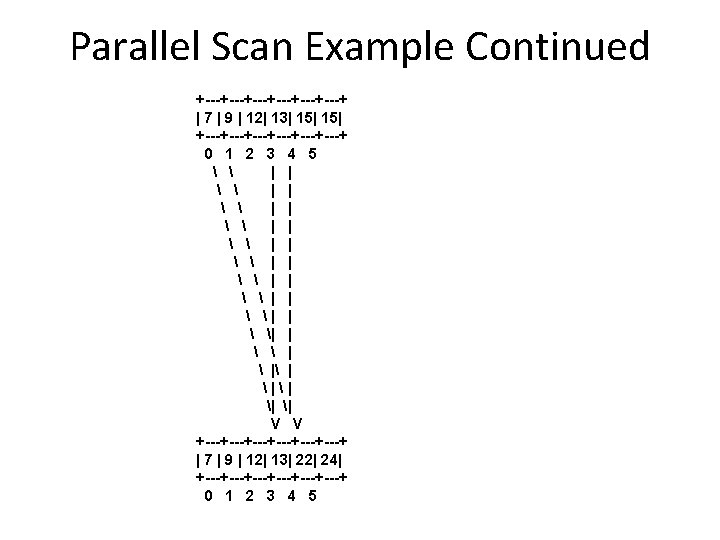
Exclusive Prefix Sum (Exclusive Scan) • Example: Given the following array, compute the prefix sum. +---+---+---+ |7|2|3|1|9|2| +---+---+---+ 0 1 2 3 4 5 +---+---+---+ | 0 | 7 | 9 | 12| 13| 22| +---+---+---+ 0 1 2 3 4 5
Inclusive Prefix Sum (Inclusive Scan) • Example: Given the following array, compute the prefix sum. +---+---+---+ |7|2|3|1|9|2| +---+---+---+ 0 1 2 3 4 5 +---+---+---+ | 7 | 9 | 12| 13| 22| 24| +---+---+---+ 0 1 2 3 4 5
Naïve Prefix Sum (Exclusive Scan) Algorithm int arr[N] = {7, 2, 3, 1, 9, 2}; int prefix. Sum[N]; int i, j; prefix. Sum[0] = 0; for(i = 1; i < N; i++) prefix. Sum[i]=prefix. Sum[i-1]+arr[j-1];
Naïve Parallel Scan const int N = 6; int log_of_N = log 2(8); int arr[N] = {7, 2, 3, 1, 9, 2}; int scan. Sum[2][N]; int i, j; int in = 1, out = 0; memcpy(scan. Sum[out], arr, N*sizeof(int)); memset(scan. Sum[in], 0, N*sizeof(int)); int two_i = 0, two_i_1 = 0;
Naïve Parallel Scan for(i = 1; i <= log_of_N; i++) { two_i_1 = 1 << (i-1); two_i = 1 << i; out = 1 - out; in = 1 - out; for(j = 0; j < N; j++) { if(j >= two_i_1) scan. Sum[out][j] = scan. Sum[in][j] + scan. Sum[in][j - two_i_1]; else scan. Sum[out][j] = scan. Sum[in][j]; } }
Adding Open. MP Parallelism for(i = 1; i <= log_of_N; i++) { two_i_1 = 1 << (i-1); two_i = 1 << i; out = 1 - out; in = 1 - out; #pragma omp parallel for private(j) shared(scan. Sum, in, out) for(j = 0; j < N; j++) { if(j >= two_i_1) scan. Sum[out][j] = scan. Sum[in][j] + scan. Sum[in][j - two_i_1]; else scan. Sum[out][j] = scan. Sum[in][j]; } }
Naïve Parallel Scan Analysis • Not work efficient • Performs O(n lg n) additions • Note that the serial version performs O(n) additions • Requires O(lg n) steps • This means we can complete a scan in O(lg n) time if we have O(n lg n) processors
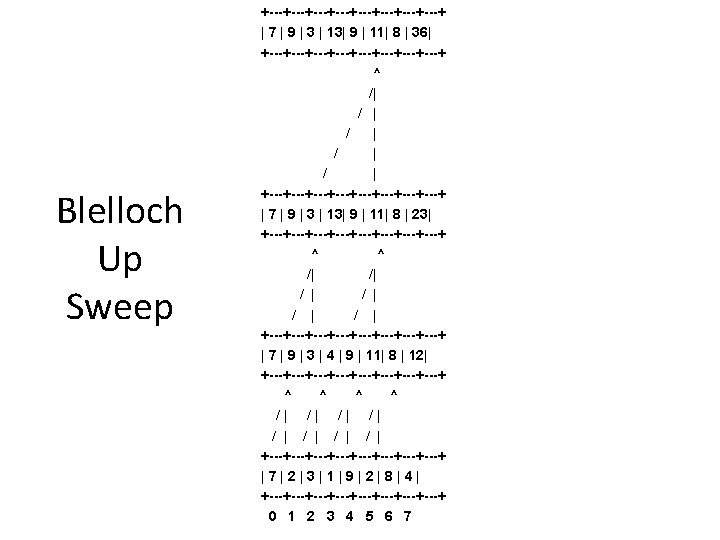
Work Efficient Parallel Scan (Blelloch 1990) • Goal – build a scan algorithm that avoids the extra O(lg n) work • Solution – make use of balanced binary trees – Build a balanced binary tree on the input data and sweep the tree to compute the prefix sum • Consists of two parts • Up Sweep – Traverse tree from leaves to root computing partial sums during the traversal – The root node (last element in the array) will hold the sum of all elements • Down Sweep – Traverse from root to leaves using the partial sums to compute the cumulative sums in place. – For the exclusive prefix sum, we replace the root with zero
Blelloch Algorithm – Up Sweep for(i = 0; i <= log_of_N_1; i++) { two_i_p 1 = 1 << (i+1); two_i = 1 << i; for(j = 0; j < N; j+=two_i_p 1) scan. Sum[j + two_i_p 1 - 1] = scan. Sum[j + two_i - 1] + scan. Sum[j + two_i_p 1 - 1]; }
Blelloch Algorithm – Down Sweep scan. Sum[N-1] = 0; for(i = log_of_N_1; i >= 0; i--) { two_i_p 1 = 1 << (i+1); two_i = 1 << i; for(j = 0; j < N; j+=two_i_p 1) { long t = scan. Sum[j + two_i - 1]; scan. Sum[j + two_i - 1] = scan. Sum[j + two_i_p 1 - 1]; scan. Sum[j + two_i_p 1 - 1] = t + scan. Sum[j + two_i_p 1 - 1]; } }
Analysis • This algorithm does complete the summation in O(n) operations, giving the appearance of efficiency. • Actually, the algorithm requires 2*(n-1) additions and n-1 swaps to run to completion. • For large arrays, this algorithm will indeed outperform the Hillis and Steele Algorithm.