Parallel Molecular Dynamics Application Oriented Computer Science Research





![Molecular Dynamics • Collection of [charged] atoms, with bonds • Newtonian mechanics • At](https://slidetodoc.com/presentation_image_h2/618b257d4f04ce9a6f9c879a3d7f0146/image-7.jpg "Molecular Dynamics • Collection of [charged] atoms, with bonds • Newtonian mechanics • At")











, Angles(3), Dihedrals (4), . .")
















 decomposition provides necessary flexibility –")



- Slides: 40
Parallel Molecular Dynamics Application Oriented Computer Science Research Laxmikant Kale http: //charm. cs. uiuc. edu
Outline • What is needed for HPC to succeed? • Parallelization of Molecular Dynamics – Aggressive Parallel decomposition – Load Balancing and performance – Multiparadigm programming • Collaborative Interdisciplinary Research – Comments and lessons
Contributors • PI s : – Laxmikant Kale, Klaus Schulten, Robert Skeel • NAMD 1: – Robert Brunner, Andrew Dalke, Attila Gursoy, Bill Humphrey, Mark Nelson • NAMD 2: – M. Bhandarkar, R. Brunner, A. Gursoy, J. Philips, N. Krawetz, A. Shinozaki, K. Varadarajan,
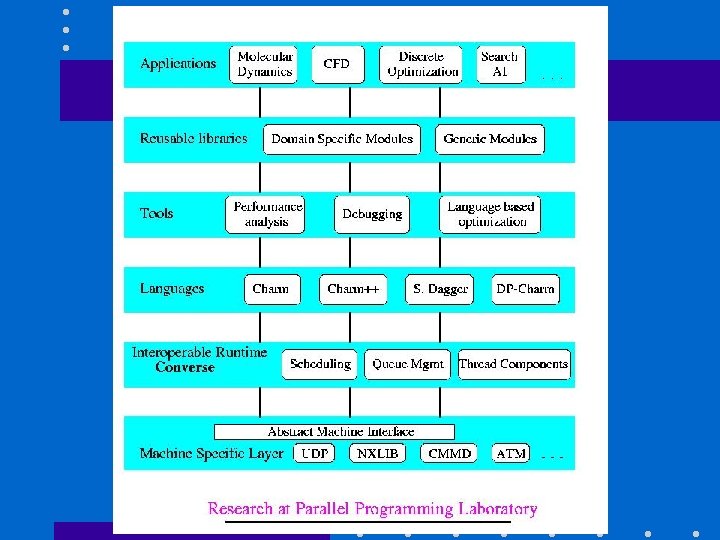
Parallel Computing Research • Trends: – application centered CS research – Isolated CS research • Drawback of both • Needed: – Computer Science centered, yet application oriented research
Middle layers Applications “Middle Layers”: Languages, Tools, Libraries Parallel Machines
Molecular Dynamics • Collection of [charged] atoms, with bonds • Newtonian mechanics • At each time-step – Calculate forces on each atom • bonds: • non-bonded: electrostatic and van der Waal’s – Calculate velocities and Advance positions • 1 femtosecond time-step, millions needed! • Thousands of atoms (1, 000 - 100, 000)
Further MD • Use of cut-off radius to reduce work – 8 - 14 Å – Faraway charges ignored! • 80 -95 % work is non-bonded force computations • Some simulations need faraway contributions
Scalability • The Program should scale up to use a large number of processors. – But what does that mean? • An individual simulation isn’t truly scalable • Better definition of scalability: – If I double the number of processors, I should be able to retain parallel efficiency by increasing the problem size
Isoefficiency • Quantify scalability • How much increase in problem size is needed to retain the same efficiency on a larger machine? • Efficiency : Seq. Time/ (P · Parallel Time) – parallel time = • computation + communication + idle
Traditional Approaches • Replicated Data: – All atom coordinates stored on each processor – Non-bonded Forces distributed evenly – Analysis: Assume N atoms, P processors • • Computation: O(N/P) Communication: O(N log P) Communication/Computation ratio: P log P Fraction of communication increases with number of processors, independent of problem size!
Atom decomposition • Partition the Atoms array across processors – Nearby atoms may not be on the same processor – Communication: O(N) per processor – Communication/Computation: O(P)
Force Decomposition • Distribute force matrix to processors – Matrix is sparse, non uniform – Each processor has one block – Communication: N/sqrt(P) – Ratio: sqrt(P) • Better scalability (can use 100+ processors) – Hwang, Saltz, et al: – 6% on 32 Pes 36% on 128 processor
Spatial Decomposition • Allocate close-by atoms to the same processor • Three variations possible: – Partitioning into P boxes, 1 per processor • Good scalability, but hard to implement – Partitioning into fixed size boxes, each a little larger than the cutoff disctance – Partitioning into smaller boxes • Communication: O(N/P)
Spatial Decomposition in NAMD • NAMD 1 used spatial decomposition • Good theoretical isoefficiency, but for a fixed size system, load balancing problems • For midsize systems, got good speedups up to 16 processors…. • Use the symmetry of Newton’s 3 rd law to facilitate load balancing
Spatial Decomposition
Spatial Decomposition
FD + SD • Now, we have many more objects to load balance: – Each diamond can be assigned to any processor – Number of diamonds (3 D): – 14·Number of Patches
Bond Forces • Multiple types of forces: – Bonds(2), Angles(3), Dihedrals (4), . . – Luckily, each involves atoms in neighboring patches only • Straightforward implementation: – Send message to all neighbors, – receive forces from them – 26*2 messages per patch!
Bonded Forces: • Assume one patch per processor A C B
Implementation • Multiple Objects per processor – Different types: patches, pairwise forces, bonded forces, – Each may have its data ready at different times – Need ability to map and remap them – Need prioritized scheduling • Charm++ supports all of these
Charm++ • Data Driven Objects • Object Groups: – global object with a “representative” on each PE • • Asynchronous method invocation Prioritized scheduling Mature, robust, portable http: //charm. cs. uiuc. edu
Data driven execution Scheduler Message Q
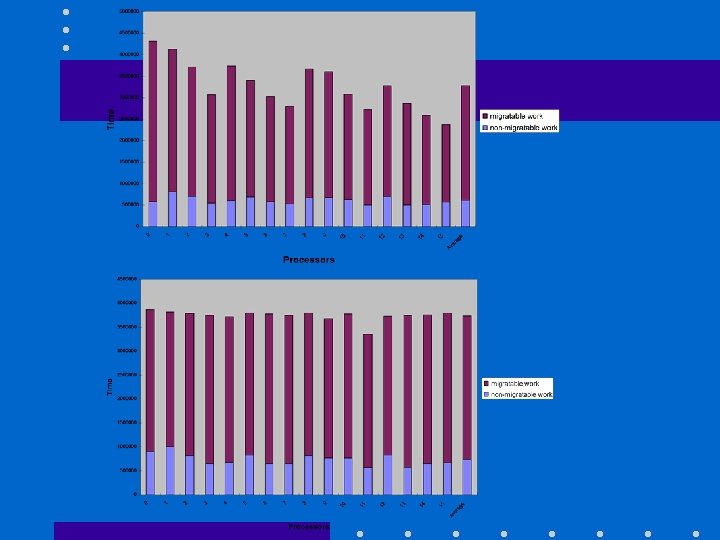
Load Balancing • Is a major challenge for this application – especially for a large number of processors • Unpredictable workloads – Each diamond (force object) and patch encapsulate variable amount of work – Static estimates are inaccurate • Measurement based Load Balancing – Very slow variations across timesteps
Bipartite graph balancing • Background load: – Patches and angle forces • Migratable load: – Non-bonded forces • Bipartite communication graph – between migratable and non-migratable objects • Challenge: – Balance Load while minimizing communication
Load balancing • Collect timing data for several cycles • Run heuristic load balancer – Several alternative ones • Re-map and migrate objects accordingly – Registration mechanisms facilitate migration • Needs a separate talk!
Before and After
Before and After
Performance: size of system
Performance: various machines
Speedup
Multi-paradigm programming • Long-range electrostatic interactions – Some simulations require this – Contributions of faraway atoms can be calculated infrequently – PVM based library, DPMTA • developed at Duke by John Board et al • Patch life cycle • Better expressed as a thread
Converse • Supports multi-paradigm programming • Provides portability • Makes it easy to implement RTS for new paradigms • Several languages/libraries: – Charm++, threaded MPI, PVM, Java, md-perl, pc++, Nexus, Path, Cid, CC++, DP, Agents, . .
Namd 2 with Converse
NAMD 2 • In production use – Internally for about a year – Several simulations completed/published • Fastest MD program? We think so • Modifiable/extensible – Steered MD – Free energy calculations
Lessons for CSE • Technical lessons – Multiple-domain (patch) decomposition provides necessary flexibility – Data driven objects and threads is a great combo – Measurement based load balancing is better – Multi-paradigm parallel programming works! • Integrate independently developed libraries • Use appropriate paradigm for each component
Real Application? • Drawbacks – Need to spend effort on mundane details not germane to CS research – Production program: complicates structure
Real Application for CS research? • Benefits – Subtle and complex research problems uncovered only with real application – Satisfaction of “real” concrete contribution – With careful planning, you can truly enrich the “middle layers” – Bring back a rich variety of relevant CS problems – Apply to other domains: Rockets? Casting?
Collaboration lessons • Use conservative methods. . – C++: fashionable vs. conservative – Aggressive methods where they matter • Account for differing priorities and objectives