Parallel Computing on Graphics Processors Importance Properties and



 originally is a co- processor beside CPU to perform")
")
 Why Parallel Computing? Recent GPUs has many simple cores that can")
 681 million transistors 128 single processors 1. 5 GHz processor clock")
 Geforce 200 series 1. 4 B transistors 583. 2 mm Less")

{. . . Y=sin(x); F=Y^2; . . . } Sin(2 ) Sin(1")
")
 Number of TPCs in GPUs are")
 Let us call them “cores” Each")

{. . . Y=sin(x); F=Y^2; . . . }")
 Model An instruction can")







{. . . Y=sin(x); F=Y^2; If (f>0. 5) else. .")
 Each Grid Contains many Blocks. Each “Thread")

 { // Kernel invocation vec. Add<<<1, N>>>(A, B,")













 freed using cuda. Free() The")


![Bitonic Sort on GPU using CUDA int main(int argc, char** argv) { int values[NUM];](https://slidetodoc.com/presentation_image_h2/be84b2d65d746edb8f59c73e6beab4de/image-47.jpg "Bitonic Sort on GPU using CUDA int main(int argc, char** argv) { int values[NUM];")







 Sub-list")


- Slides: 57
Parallel Computing on Graphics Processors Importance Properties and Features Inside Nvidia GPUs How do they operate? CUDA What is CUDA? Major concepts and extensions How a code can be written in CUDA for running on GPU? A sample code of Bitonic sort in CUDA A hybrid sorting algorithm on GPU
Graphics Processors
Introduction GPU (Graphics Processing Unit) originally is a co- processor beside CPU to perform graphics related jobs which have an output to display devices. Increasing market demand for real time, and high definition 3 D graphics has resulted in highly parallel, many-core programmable GPUs has multi-threaded hardware structure Tremendous computational power Very high memory bandwidth
Introduction (cont. )
Introduction (cont. ) Why Parallel Computing? Recent GPUs has many simple cores that can operate in parallel. They are able to perform different instructions like a general purpose processor. They operate as a SIMD (Simple Instruction, Multiple Data) architecture. It is not completely SIMD but SIMT (Simple Instruction, Multiple Threads). Parallel structure of GPUs can be used to perform different general purpose tasks beside CPUs.
Introduction (cont. ) 681 million transistors 128 single processors 1. 5 GHz processor clock 576 Gflop/s 768 Mbyte DDR 3 DRAM 1. 08 GHz DRAM clock 104 Gbyte/s bandwidth Geforce 8800 Ultra die layout
Introduction (cont. ) Geforce 200 series 1. 4 B transistors 583. 2 mm Less than 2 cm x 3 cm 192 -240 single processors 896 Mbyte RAM Thus, it is a nice parallel platform for scientific parallel computing.
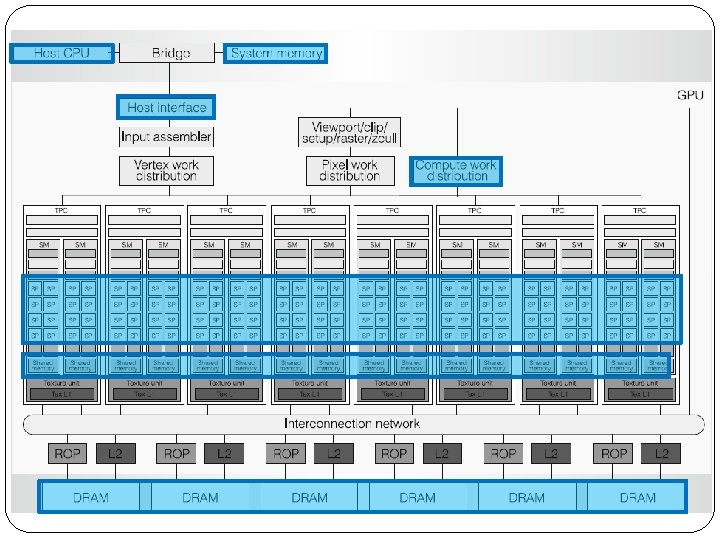
Inside GPU Many Single Processors Local Storages for Processors Private Shared Global Storages Communication between Processors and Memory Interconnection Network Interface for communication between GPU, CPU, and Main Memory Graphics Related Units
Inside GPU Main(){. . . Y=sin(x); F=Y^2; . . . } Sin(2 ) Sin(1 ) Sin(3 ) Sin(0 ) Sin(3 ) Sin(4 )
Layout of a TPC including 2 SM(Streaming Multiprocessor)
Inside GPU Each GPU contains many TPCs(Texture/Processor Cluster) Number of TPCs in GPUs are increasing. Geforce 8 series : 8 TPCs Geforce 200 series : 10 TPCs Each TPC contains: A Geometry Controller (Graphics Related) A SMC (Streaming Multiprocessor Controller) 2 or 3 SMs (Streaming Multiprocessor) A Texture Unit (Graphics Related)
Inside GPU Each SM contains: 8 SP(Streaming Processors) Let us call them “cores” Each core has a MAD(Multiply-add) unit An Instruction Cache A MT unit (Multithreaded Instruction Fetch and Issue Unit) A Constant Cache 2 SFUs for transcendental functions (sin, root, etc. ) A 16 Kbyte Shared Memory Layout of a SM(Streaming Multiprocessor)
Inside GPU Each core has its own set of registers and register states. Shared Memory, Instruction Cache, and Constant Cache can only be accessed by cores and other units of a SM. NOT other SMs! Workload is distributed by SMC(Streaming Multiprocessor Controller) between SMs. MT unit of SM fetch instructions, issue, and distribute them between cores. Each core fetches the data it needs from shared memory or global memory and executes the instruction.
How does a GPU operate? Main(){. . . Y=sin(x); F=Y^2; . . . } SIMD Model An instruction is executed by many cores. Different data They all have to execute Y=sin(x);
How does a GPU operate? SIMT (Single Instruction Multiple Threads) Model An instruction can be executed by many threads. Each thread is mapped to one core. Each thread can be seen as a core, as a virtual simple processor. All properties of a core are true for a thread. Main(){. . . Y=sin(x); F=Y^2; . . . }
How does a GPU operate? Remember: Each core has its own registers and register states. Each core has its own IP(Instruction Pointer) register. Therefore, a thread has its own registers, register states, and instruction address. What does this mean? ! It means that each thread can: Run a different instruction independent of other threads. Have its own values resulted from the sequence of instructions it has executed so far.
How does a GPU operate? What is the result/advantage? GPU is not a SIMD architecture, but a SIMT. We have many threads/cores that can operate similar to many parallel independent processors. Thus, we have a Parallel Multi-threaded shared memory architecture. Main(){. . . Y=sin(x); F=Y^2; If (f>10) else. . . }
How does a GPU operate? Notes: Threads start together at the same instruction address. Threads can not go very far away from each other Because of the Instruction Cache which has a fixed capacity to fetch instructions. On conditional branching instructions: Threads which are further, have to wait for other threads. It is called “Thread Divergence”. Because according to the condition, some threads may want to go to some far set of instructions, While the other want to continue with the current IP and instructions. Each group of threads is serially executed while the other groups have to wait.
How does a GPU operate? Key idea is to create too many threads. Then, they start to execute instructions of your code starting at the same address. We have many SMs (streaming multiprocessors), each one contains 8 cores.
How does a GPU operate? As a result, we have to group threads and distribute them between SMs and eventually cores. These groups are called “Warps”. Each warp contains 32 threads. Each time, a warp is associated with a SM. When a SM executes a warp, it does not pay attention to other warps.
How does a GPU operate? Cores of a SM execute threads of a warp in parallel. All SMs operate in parallel. All 32 threads of a warp can access shared memory. Because each time a SM executes a warp, thread divergence only occurs within a warp.
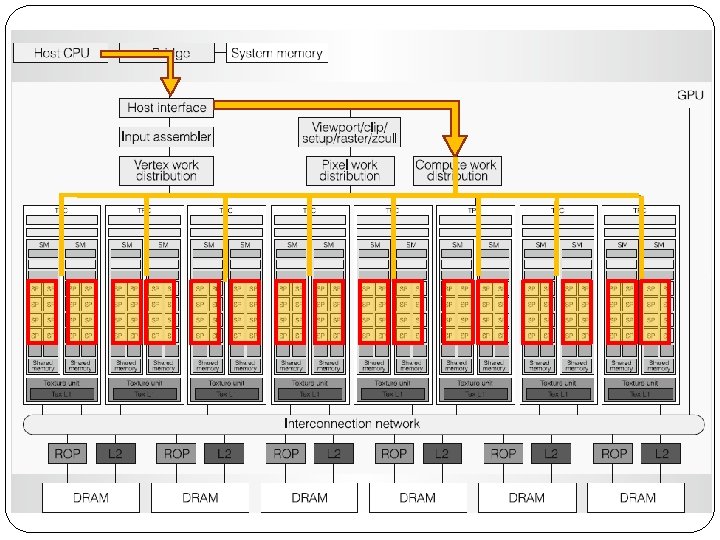
Mapping Code to Processors How our code is mapped to threads which will be executed by cores? Main(){. . . Y=sin(x); F=Y^2; If (f>0. 5) else. . . } Code is divided into the parts that should be executed on CPU and parts that should be executed on GPU. We are interested in GPU related parts. All instructions run sequentially. When we reach an instruction from GPU related section, it is taken and is sent to GPU. We call these taken instructions, sent from CPU to GPU, “Kernels”.
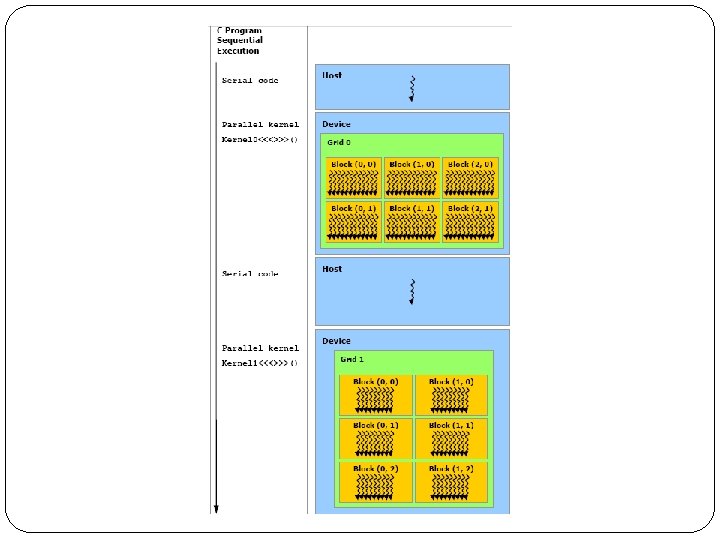
Mapping Code to Processors Main(){. . . Y=sin(x); F=Y^2; If (f>0. 5) else. . . } sin(1) CPU sin(3) sin(2) sin(4) Kernel sin(1) sin(5) Each kernel is mapped to a “Grid”. A grid contains too many threads. Each time a grid is executed on GPU
Mapping Code to Processors CPU Kernel Y=sin(x) Each Grid Contains many Blocks. Each “Thread Block” contains many threads. Each Block contains up to 512 threads. Threads of a block are grouped into warps. Each grid can have as many block as is needed.
Mapping Code to Processors Threads inside a block can be organized as a 3 D matrix and can be accessed by three indices (x, y, z). Blocks inside a grid are organized as a 2 D matrix. So, each thread and each block are accessible by programmer. They are accessible by two predefined variables: 1. Thread. Idx 2. Block. Idx
Mapping Code to Processors int main() { // Kernel invocation vec. Add<<<1, N>>>(A, B, C); } A B thread. Idx. 1 A(1) B(1) thread. Idx. 2 A(2) B(2) thread. Idx. 3 void vec. Add(float* A, float* B, float* C) { int i = thread. Idx. x; C[i] = A[i] + B[i]; } A(3) B(3) thread. Idx. 4 A(4) B(4) thread. Idx. 5 A(5) B(5) thread. Idx. 6 A(6) B(6)
Mapping Code to Processors A grid is executed on the whole GPU and its SMs. Each thread block is executed on only one SM. A SM does not switch to other blocks only if it completes current block. Threads of a block are not aware of other blocks, but they can communicate through global memory. Threads inside a block can see each other and communicate through the SM’s shared memory.
Another layout of GPU, SMs, cores, and memories
CUDA Compute Unified Device Architecture
CUDA Nvidia developed a programming environment which mixes CPU and GPU programming. It is an extension to C/C++. The extension contains new rules and instructions that are designated for running on GPU, and communication between GPU and CPU. You can write your code including everything that you like to be executed on either CPU or GPU in CUDA compiler (NVCC) parses the code and recognizes kernels and other parts. It compiles kernels to be sent to GPU and for CPU instructions: Just sends them to a C/C++ compiler
Programming in CUDA The extensions to the C programming language are four-fold: Function type qualifiers to specify whether a function executes on the host or on the device and whether it is callable from the host or from the device. Variable type qualifiers to specify the memory location on the device of a variable. How to run a kernel A new directive to specify how a kernel is executed on the device from the host. Built-in variables Four built-in variables that specify the grid and block dimensions and the block and thread indices.
Function Type Qualifiers __device__ The __device__ qualifier declares a function that is: Executed on the device Callable from the device only. __global__ The __global__ qualifier declares a function as being a kernel. Executed on the device, Callable from the host only. __host__ The __host__ qualifier declares a function that is: Executed on the host, Callable from the host only.
Function Type Qualifiers __device__ and __global__ functions do not support recursion. __global__ functions must have void return type. __global__ void vec. Add(float* A, float* B, float* C) { int i = thread. Idx. x; C[i] = A[i] + B[i]; }
Variable Type Qualifiers __device__ The __device__ qualifier declares a variable that resides on the device. Default is Global memory. __constant__ The __constant__ qualifier, optionally used together with __device__, declares a variable that: Resides in constant memory space. Has the lifetime of an application. Is accessible from all the threads within the grid. __shared__ The __shared__ qualifier, optionally used together with __device__, declares a variable that: Resides in the shared memory space of a SM. Has the lifetime of the block. Is only accessible from all the threads within the block.
Variable Type Qualifiers If none of them is present, the variable: Resides in global memory space, Has the lifetime of an application, Is accessible from all the threads within the grid. __shared__ int values[];
Execution Configuration Any call to a __global__ function must specify the execution configuration for that call. int main() { // Kernel invocation vec. Add<<<1, N>>>(A, B, C); } void vec. Add(float* A, float* B, float* C) { int i = thread. Idx. x; C[i] = A[i] + B[i]; }
Execution Configuration Expression of the form <<< Dg, Db, Ns, S >>> between the function name and the parenthesized argument list, where: Dg is specifies the dimension and size of the grid, i. e. number of blocks being launched; Db specifies the dimension and size of each block, i. e. the number of threads per block; Ns specifies the number of bytes in shared memory that is dynamically allocated per block for this call in addition to the statically allocated memory; S is of type cuda. Stream and specifies the associated stream.
Built-in Variables grid. Dim block. Idx block. Dim thread. Idx warp. Size
Device Memory Device memory can be allocated either as linear memory or as CUDA arrays. Arrays can be defined like C array definition and using variable qualifiers. Linear memory exists on the device in a 32 -bit address space. Accessible via pointers. Both linear memory and CUDA arrays are readable and writable by the host through the memory copy functions.
Memory Management Linear memory is allocated using cuda. Malloc() freed using cuda. Free() The following code sample allocates an array of 256 floating-point elements in linear memory: float* dev. Ptr; cuda. Malloc((void**)&dev. Ptr, 256 * sizeof(float));
Memory Management The following code sample copies some host memory array to device memory: float data[256]; int size = sizeof(data); float* dev. Ptr; cuda. Malloc((void**)&dev. Ptr, size); cuda. Memcpy(dev. Ptr, data, size, cuda. Memcpy. Host. To. Device);
Thread Synchronization in CUDA In some situations, it is necessary that all threads reach at a point together before continuing the execution. Because in the next part, we need the results of execution up to that point. Without synchronization, some threads may go further and access incomplete results produced by slow threads that have not reached the point yet. __syncthreads(); synchronizes all threads in a block. Once all threads have reached this point, execution resumes normally. cuda. Thread. Synchronize() Synchronizes all threads in a grid.
Bitonic Sort on GPU using CUDA int main(int argc, char** argv) { int values[NUM]; for(int i = 0; i < NUM; i++) values[i] = rand(); int * dvalues; CUDA_SAFE_CALL(cuda. Malloc((void**)&dvalues, sizeof(int) * NUM)); CUDA_SAFE_CALL(cuda. Memcpy(dvalues, sizeof(int) * NUM, cuda. Memcpy. Host. To. Device)); bitonic. Sort<<<1, NUM, sizeof(int) * NUM>>>(dvalues); CUDA_SAFE_CALL(cuda. Memcpy(values, dvalues, sizeof(int) * NUM, cuda. Memcpy. Device. To. Host)); CUDA_SAFE_CALL(cuda. Free(dvalues)); CUT_EXIT(argc, argv); }
Bitonic Sort on GPU using CUDA #define NUM 256 ___global__ static void bitonic. Sort(int * values) { extern __shared__ int shared[]; const unsigned int tid = thread. Idx. x; shared[tid] = values[tid]; __syncthreads(); FOR LOOP at right of this page // Write result. values[tid] = shared[tid]; } for (unsigned int k = 2; k <= NUM; k *= 2){ for (unsigned int j = k / 2; j>0; j /= 2){ unsigned int ixj = tid ^ j; if (ixj > tid){ if ((tid & k) == 0) if (shared[tid] > shared[ixj]) swap(shared[tid], shared[ixj]); else if (shared[tid] < shared[ixj]) swap(shared[tid], shared[ixj]); } __syncthreads(); } }
A hybrid sorting algorithm on GPU Erik Sintorn, Ulf Assarsson, “Fast Parallel GPU-Sorting Using a Hybrid Algorithm”, Journal of Parallel and Distributed Computing, Vol. 68, Issue 10(October 2008), Pages: 1381 -1388, 2008.
Fast Parallel GPU-Sorting Using a Hybrid Algorithm The algorithm is a combination of two well-known sorting algorithms: Merge Sort Bucket Sort Two levels of sorting: External Sort: Using Bucket Sort Internal sort: Using Merge Sort
Fast Parallel GPU-Sorting Using a Hybrid Algorithm Two main steps Dividing list of items into L sublists with equal sizes For 1<i<L : Items of list i+1 are larger than items of list i This is done using Bucket Sort defined in T. H. Cormen, Section 9. 4: Bucket sort, in “Introduction to Algorithms”, Second Edition, MIT Press and Mc. Graw-Hill, 2001, pp. 174 -177. Internally sorting each sublist using Merge sort. This is done using a vector-based merge sort. In vector-based merge sort, vectors of length 4 are compared instead of comparing individual items.
Fast Parallel GPU-Sorting Using a Hybrid Algorithm Dividing list of items into L sublists with equal sizes At First, Find the maximum and minimum elements of the list. Then execute the following psuedo-code: { Element=input(thread. Id); Index(thread. Id)=((element-min)/(max-min)*L); } 23 7 1<. . <6. 5 12 18 9 6. 5<. . . <12 2 1 12<. . <17. 5 15 10 8 17. 5<. . <23 Min=1 Max=23 L=4
Fast Parallel GPU-Sorting Using a Hybrid Algorithm A refining process is run over all sublists to change their upper and lower bounds. Finally, we have L sublists with equal sizes. To have all items sorted, it is enough to sort each sublist internally. Each sublist is given to a thread block in order to be sorted by a SM. This can be done using a vector merge sort.
Fast Parallel GPU-Sorting Using a Hybrid Algorithm Geforce 8800 contains some vector-based operations. Length of a vecor in Geforce 8800 is 4. These vectors are called 4 -float vectors. 4 -float Vector Comparison 4 -float Vector Sort Items of each list are grouped into vectors of length 4. 4 -float vectors of each list are sorted using merge sort by a SM.
Vectore-Based Merge Sort i(th) Sub-list
Comparison to other GPU-based Sorting Algorithms
General Purpose Programming on GPU Any Question?