Parallel Computer Models CEG 4131 Computer Architecture III



 Instructions Data Main memory (M) IS Control Unit IS PE")






 • Non-Uniform Memory Access (NUMA) • Cache-only")
 • Suitable for")




![Interconnection Network [1] • Mode of Operation (Synchronous vs. Asynchronous) • Control Strategy (Centralized](https://slidetodoc.com/presentation_image_h2/035d8808771a71d843699469bd79ee4e/image-17.jpg "Interconnection Network [1] • Mode of Operation (Synchronous vs. Asynchronous) • Control Strategy (Centralized")
![Classification based on the kind of parallelism[3] Parallel architectures PAs Data-parallel architectures Function-parallel architectures](https://slidetodoc.com/presentation_image_h2/035d8808771a71d843699469bd79ee4e/image-18.jpg "Classification based on the kind of parallelism[3] Parallel architectures PAs Data-parallel architectures Function-parallel architectures")

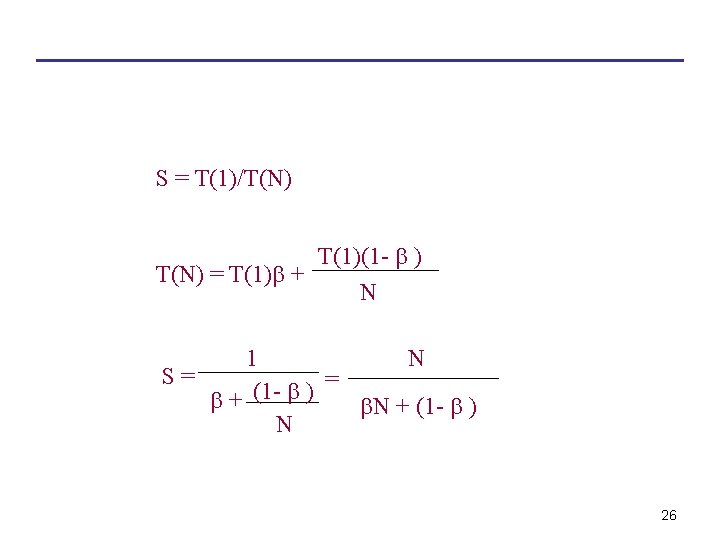
 / Speed(old) • S = Work/time(new) / Work/time(old) •")
: T(1) • Time (n CPUs): T(n) • Speedup: S")



 • : The fraction of the program that is naturally serial")

- Slides: 27
Parallel Computer Models CEG 4131 Computer Architecture III Miodrag Bolic 1
Overview • • Flynn’s taxonomy Classification based on the memory arrangement Classification based on communication Classification based on the kind of parallelism – Data-parallel – Function-parallel 2
Flynn’s Taxonomy – The most universally excepted method of classifying computer systems – Published in the Proceedings of the IEEE in 1966 – Any computer can be placed in one of 4 broad categories » SISD: Single instruction stream, single data stream » SIMD: Single instruction stream, multiple data streams » MIMD: Multiple instruction streams, multiple data streams » MISD: Multiple instruction streams, single data stream 3
SISD Processing element (PE) Instructions Data Main memory (M) IS Control Unit IS PE DS Memory 4
SIMD Applications: • Image processing • Matrix manipulations • Sorting 5
SIMD Architectures • Fine-grained – – Image processing application Large number of PEs Minimum complexity PEs Programming language is a simple extension of a sequential language • Coarse-grained – Each PE is of higher complexity and it is usually built with commercial devices – Each PE has local memory 6
MIMD 7
MISD Applications: • Classification • Robot vision 8
Flynn taxonomy – Advantages of Flynn » Universally accepted » Compact Notation » Easy to classify a system (? ) – Disadvantages of Flynn » Very coarse-grain differentiation among machine systems » Comparison of different systems is limited » Interconnections, I/O, memory not considered in the scheme 9
Classification based on memory arrangement Shared memory I/O 1 Interconnection network PE 1 I/On PEn Processors Shared memory - multiprocessors Interconnection network PE 1 PEn M 1 Mn P 1 Pn Message passing - multicomputers 10
Shared-memory multiprocessors • Uniform Memory Access (UMA) • Non-Uniform Memory Access (NUMA) • Cache-only Memory Architecture (COMA) • Memory is common to all the processors. • Processors easily communicate by means of shared variables. 11
The UMA Model • Tightly-coupled systems (high degree of resource sharing) • Suitable for general-purpose and time-sharing applications by multiple users. P 1 Pn $ $ Interconnection network Mem 12
Symmetric and asymmetric multiprocessors • Symmetric: - all processors have equal access to all peripheral devices. - all processors are identical. • Asymmetric: - one processor (master) executes the operating system - other processors may be of different types and may be dedicated to special tasks. 13
The NUMA Model • The access time varies with the location of the memory word. • Shared memory is distributed to local memories. • All local memories form a global address space accessible by all processors Access time: Cache, Local memory, Remote memory COMA - Cache-only Memory Architecture Pn P 1 Mem $ Interconnection network Distributed Memory (NUMA) 14
Distributed memory multicomputers • Multiple computers- nodes • Message-passing network • Local memories are private with its own program and data • No memory contention so that the number of processors is very large • The processors are connected by communication lines, and the precise way in which the lines are connected is called the topology of the multicomputer. • A typical program consists of subtasks residing in all the memories. M M M PE PE PE Interconnection network PE PE PE M M M 15
Classification based on type of interconnections • Static networks • Dynamic networks 16
Interconnection Network [1] • Mode of Operation (Synchronous vs. Asynchronous) • Control Strategy (Centralized vs. Decentralized) • Switching Techniques (Packet switching vs. Circuit switching) • Topology (Static Vs. Dynamic) 17
Classification based on the kind of parallelism[3] Parallel architectures PAs Data-parallel architectures Function-parallel architectures Instruction-level Thread-level PAs Process-level PAs DPs ILPS MIMDs Pipelined VLIWs Superscalar Ditributed Shared Vector Associative SIMDs Systolic memory processors memory and neural architecture processors architecture MIMD (multi-computer) Processors) 18
References 1. Advanced Computer Architecture and Parallel Processing, by Hesham El-Rewini and Mostafa Abd-El. Barr, John Wiley and Sons, 2005. 2. Advanced Computer Architecture Parallelism, Scalability, Programmability, by K. Hwang, Mc. Graw-Hill 1993. 3. Advanced Computer Architectures – A Design Space Approach by Desco Sima, Terence Fountain and Peter Kascuk, Pearson, 1997. 19
Speedup • S = Speed(new) / Speed(old) • S = Work/time(new) / Work/time(old) • S = time(old) / time(new) • S = time(before improvement) / time(after improvement) 20
Speedup • Time (one CPU): T(1) • Time (n CPUs): T(n) • Speedup: S • S = T(1)/T(n) 21
Amdahl’s Law The performance improvement to be gained from using some faster mode of execution is limited by the fraction of the time the faster mode can be used 22
Example 20 hours B A must walk 200 miles Walk 4 miles /hour Bike 10 miles / hour Car-1 50 miles / hour Car-2 120 miles / hour Car-3 600 miles /hour 23
Example 20 hours B A must walk Walk 4 miles /hour Bike 10 miles / hour Car-1 50 miles / hour Car-2 120 miles / hour Car-3 600 miles /hour 200 miles 50 + 20 = 70 hours 20 + 20 = 40 hours 4 + 20 = 24 hours 1. 67 + 20 = 21. 67 hours 0. 33 + 20 = 20. 33 hours S=1 S = 1. 8 S = 2. 9 S = 3. 2 S = 3. 4 24
Amdahl’s Law (1967) • : The fraction of the program that is naturally serial • (1 - ): The fraction of the program that is naturally parallel 25
Amdahl’s Law 27