Outline Overview MSRA Submissions System Description Experiments Training


Outline • Overview – MSRA Submissions – System Description • Experiments – Training Data & Toolkits – Chinese-English Machine Translation – Chinese-English System Combination • Conclusion
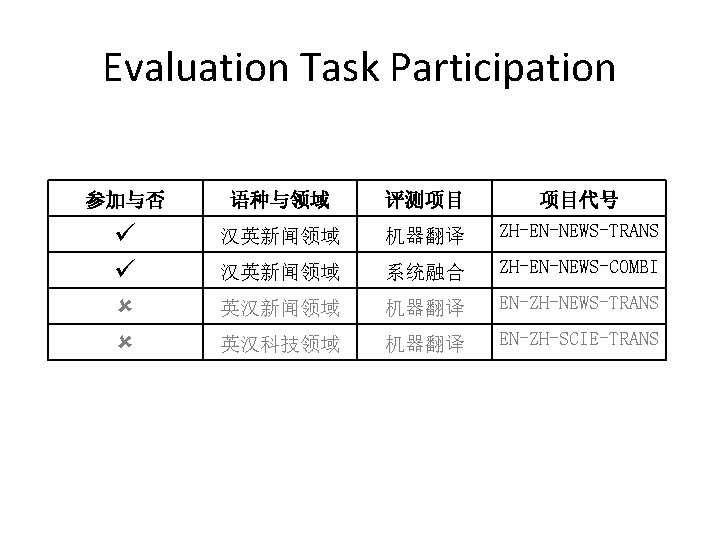

MSRA Submission • Machine translation task – Primary submission • Unlimited training corpus • Combining: Sys. A + Sys. B + Sys. C + Sys. D – Contrast submission • Limited training corpus • Combining: Sys. A + Sys. B + Sys. C • System combination task – Limited training corpus – Combining: 10 systems

Sys. A • Phrase-based model • CYK decoding algorithm • BTG grammar • Features: – Similar with (Koehn, 2004) • Maximum Entropy reordering model – (Zhang et. al 2007, Xiong et. Al, 2006)
 • Motivations •")
Sys. B • Syntactic pre-reordering model – (Li et. al, 2007) • Motivations • Isolating reordering model from decoder • Making use of syntactic information
 – Hiero re-implementation •")
Sys. C • Hierarchical phase-based model – (David Chiang, 2005) – Hiero re-implementation • Weighted synchronous CFG
 – Integrating target dependent")
Sys. D • String-to-dependency MT – (Shen et. al, 2008) – Integrating target dependent language model • Motivations – Target dependent structures integrate linguistic knowledge – Directly targeted on lexical items, simpler than CFG – Capture long distance relations by local dependency trees
")
System Combination • Analogous with BBN’s work (Rosti et. al 2007)
 • Adaptations in MSRA system – Single confusion network •")
System Combination (Cont. ) • Adaptations in MSRA system – Single confusion network • Candidate skeletons come from top-1 translations of each system • The best skeleton has the most similarity with others based on BLEU – Word alignment between skeleton and other candidate translations performed by GIZA++ – Parameters are tuned to maximize BLEU on Dev. data

Outline • Overview – MSRA Submissions – System Description • Experiments – Training Data & Toolkits – Chinese-English Machine Translation – Chinese-English System Combination • Conclusion

Training Data 非受限训练语料 短语翻译模型 LDC Parallel data, 4. 99 M sentence pairs 主办方提供 734. 8 K sentence pairs 语言模型 Gizaword+LDC Parallel (English part) 323 M English words 主办方提供的英语部分 9. 21 M English words 调序模型 FBIS + others, 197 K sentence pairs CLDC-LAC-2003 -004(ICT) 开发数据集 2005 -863 -001(489 pairs) 2005 -863 -001( 489 pairs) Primary MT Submission Contrast MT Submission

Pre-/Post-processing • Pre-processing – Tokenization for Chinese and English sentences • Before word alignment and language model training • Special tokens recognized and normalized (date, time and number) for training data – Special tokens are pre-translated with rules for test data before decoding • Post-processing – English case restoration after translation – OOVs are removed from final translation

Tools • MSR-SEG – MSRA word segmentation tool used to segment Chinese sentences in parallel data • Berkeley parser – Parse sentences for both training and test data for syntactic prereordering model based system • GIZA++ – Used for bilingual word alignment • Max. Ent Toolkit – Reordering Model (Le Zhang, 2004) • MSRA internal tools – – Language modeling Decoders Case-restoration for English words System combination

Experiments for MT Task 系统名称 受限训练语料 非受限训练语料 Sys. A Sys. B Sys. C CWMT 2008 SSMT 2007 (BLEU 4,考 (BLEU 4,忽略 虑英文大小写) 写) 0. 2366 0. 2148 0. 2505 0. 2303 0. 2436 0. 2255 Contrast Submission 0. 2473 0. 2306 Sys. A Sys. B Sys. C Sys. D 0. 3157 0. 3208 0. 3196 0. 3276 0. 2727 0. 2782 0. 2762 0. 2787 Primary Submission 0. 3389 0. 2809

Experiments for System Comb. 各参评系 SSMT 2007, BLEU 4, 采用与否 统编号 忽略大小写 S 1 -1 0. 2799 S 1 -2 0. 2802 S 3 -1 0. 2446 S 3 -2 0. 2818 S 4 -1 0. 2823 S 7 -1 0. 1647 S 8 -1 0. 2037 S 10 -1 0. 2133 S 10 -2 0. 2297 S 10 -3 0. 2234 S 11 -1 0. 1835 S 12 -1 0. 3389 S 12 -2 0. 2473 S 14 -1 0. 2118 S 14 -2 0. 2179 S 14 -3 0. 2165 S 15 -1 0. 2642 非受限 LM 系统融合 受限LM 非受限LM 0. 3274 0. 3476

Conclusions • Syntax information improves SMT – Syntactic pre-reordering model – Target dependency model • Limited LM affects the system combination – Perform worse over unlimited output when using limited LM

Thanks!



 • Motivations –")
Sys. B • Syntactic pre-reordering model – (Li et. al, 2007) • Motivations – Isolating reordering model from decoder – Making use of syntactic parse information
- Slides: 22