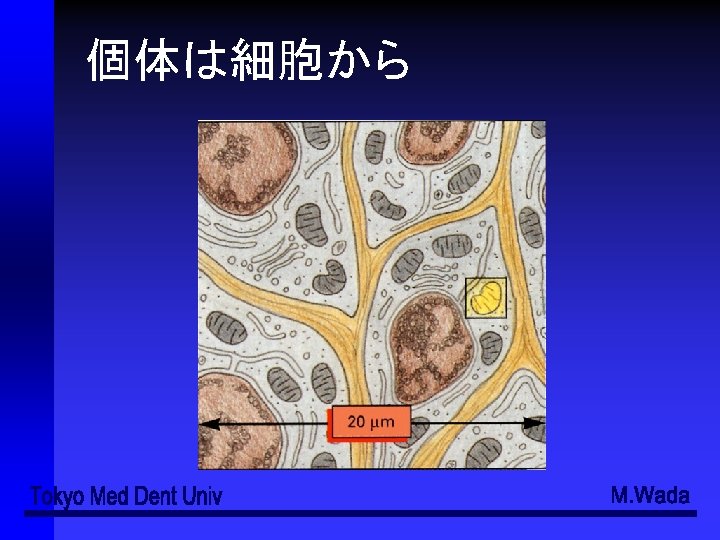
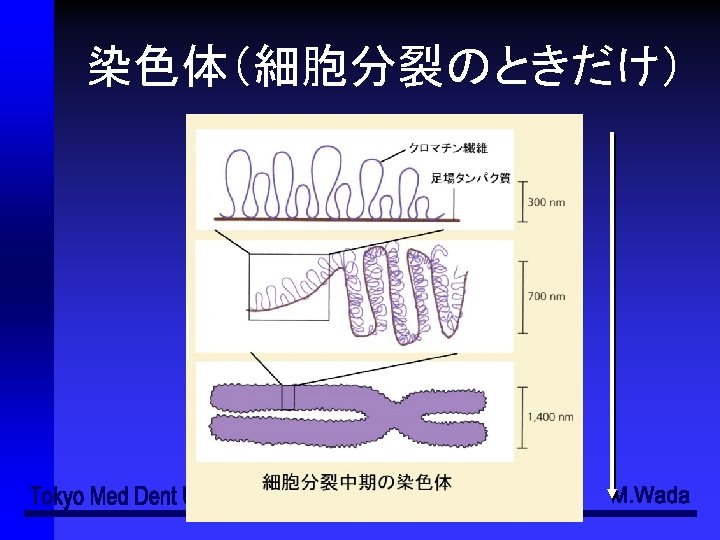
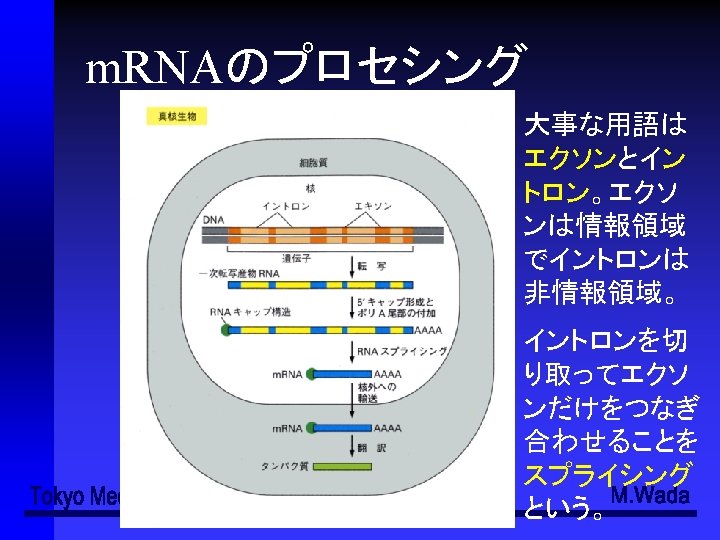
organism organ system organ tissue cell Integmentary system









 器官系 (organ system) 器官 (organ) 組織 (tissue) 細胞 (cell)")
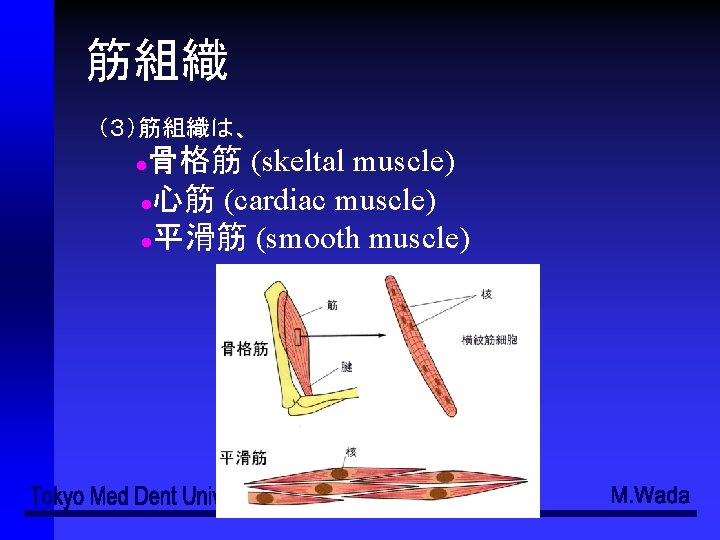
 ●骨格系 (Skeltal system) ●筋系 (Muscular system) ●消化器官系 (Digestive system) ●循環器官系")

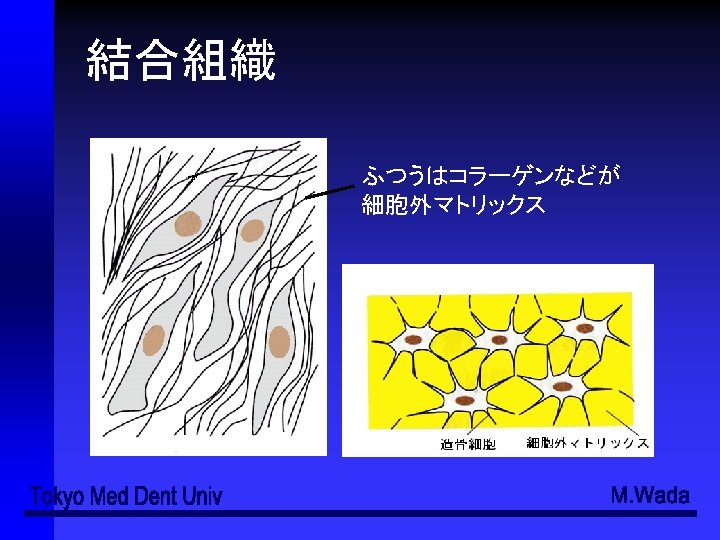
上皮組織は、 単層扁平上皮 (simple squamous ep. ) ●単層立方上皮 (simple cuboidal ep. ) ●単層円柱上皮 (simple")

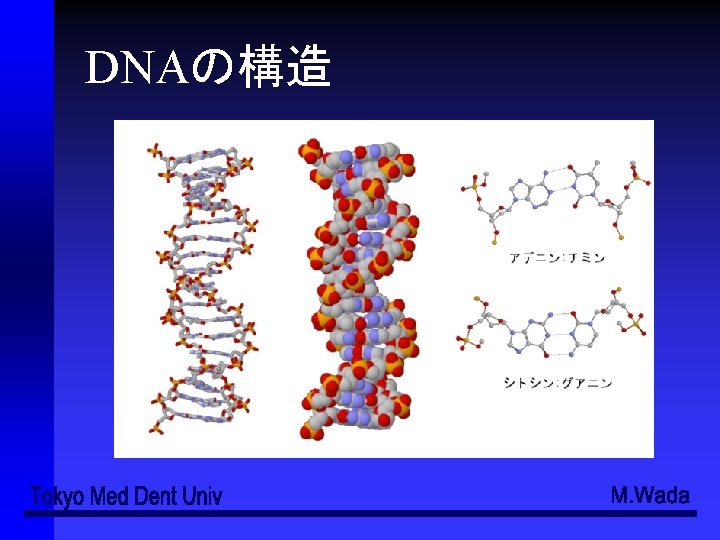
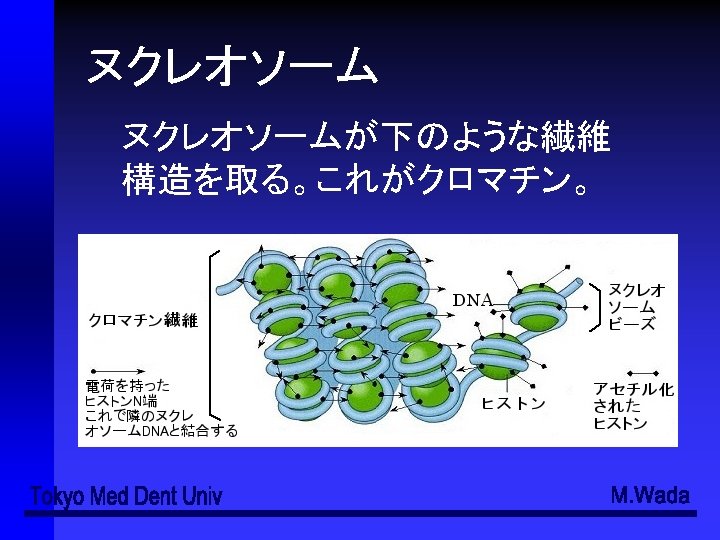
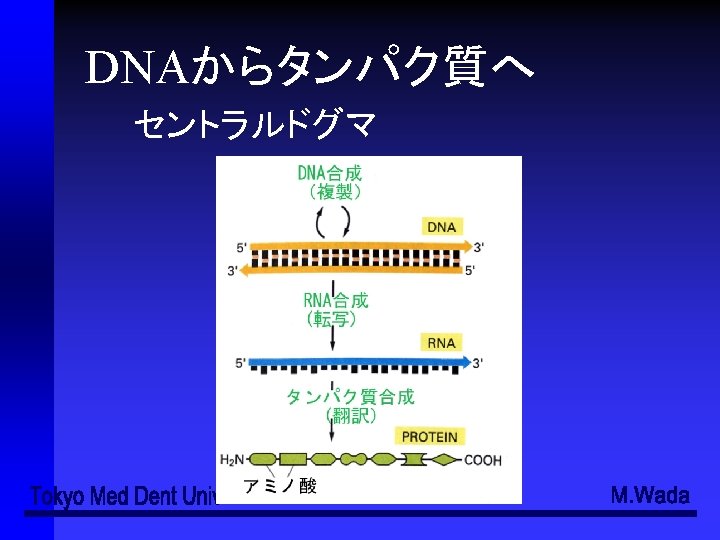


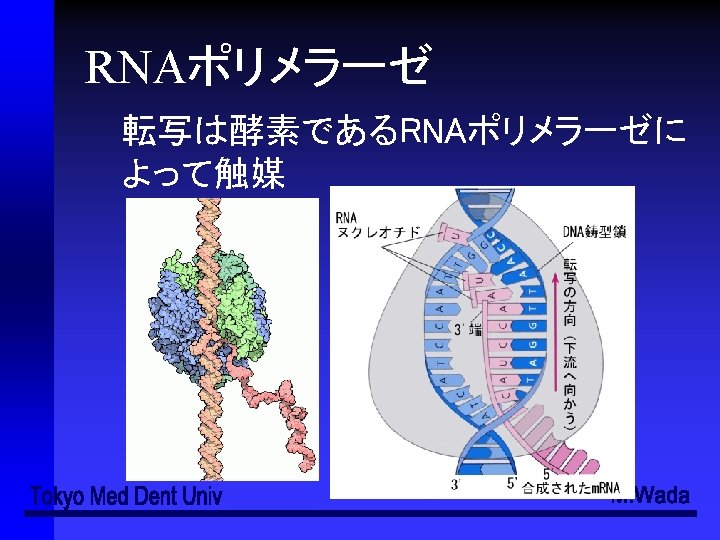
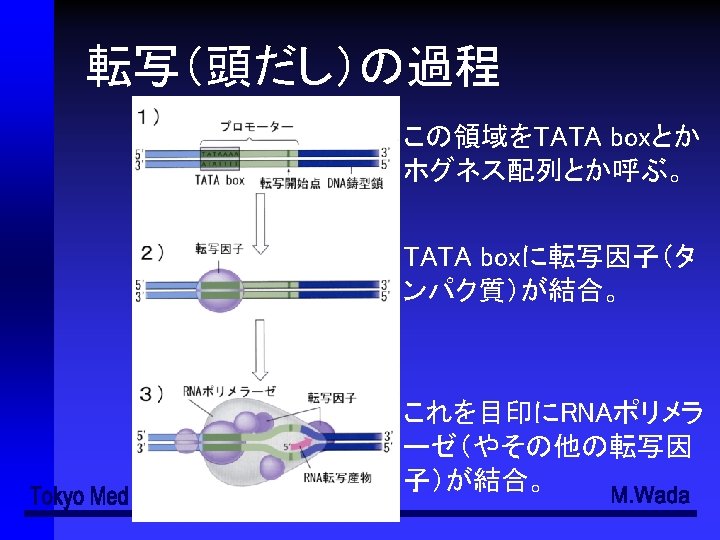
 ATGGAATTCTCGCTC(3')(コード鎖、sense strand) (3') TACCTTAAGAGCGAG(5')(鋳型鎖、antisense strand) (5‘) AUGGAAUUCUCGCUC(3’)(転写された一本鎖RNA) RNAの鎖の伸長は必ず5’→3’の方向")



 CCCTGTGGAGCCACACCCTAGGGTTGGCCAATCTACTCCCAGGAGCAGGGA GGGCAGGAGCCAGGGCTGGGCATAAAAGTCAGGGCAGAGCCATCTATTGCT TACATTTGCTTCTGACACAACTGTGTTCACTAGCAACCTCAAACAGACACC ATGGTGCACCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGC AAGGTGAACGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGTTGGTATCA AGGTTACAAGACAGGTTTAAGGAGACCAATAGAAACTGGGCATGTGGAGAC AGAGAAGACTCTTGGGTTTCTGATAGGCACTGACTCTGCCTATTGGT CTATTTTCCCACCCTTAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTT CTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCC TAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCT GGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGCTGCA CTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGGTGAGTCTATGGGA CCCTTGATGTTTTCCCCTTCTTTTCTATGGTTAAGTTCATGTCATAG")
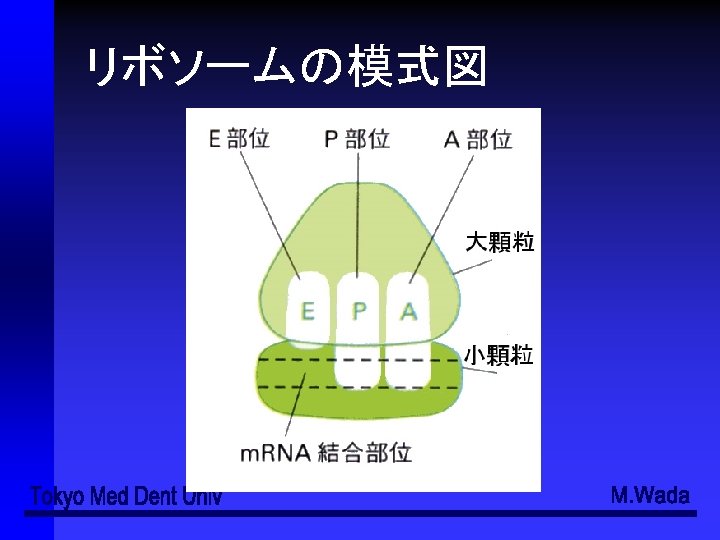
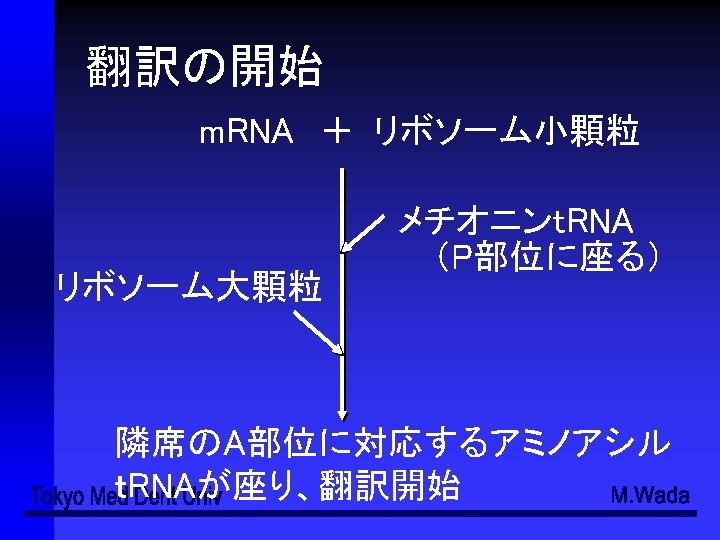
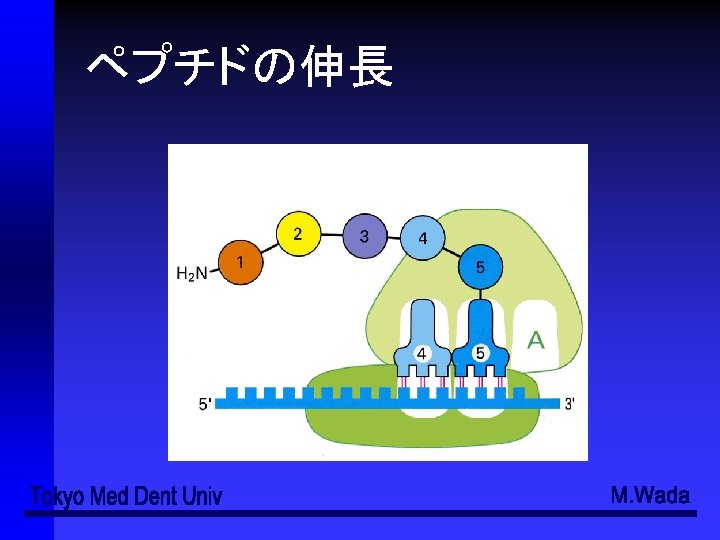
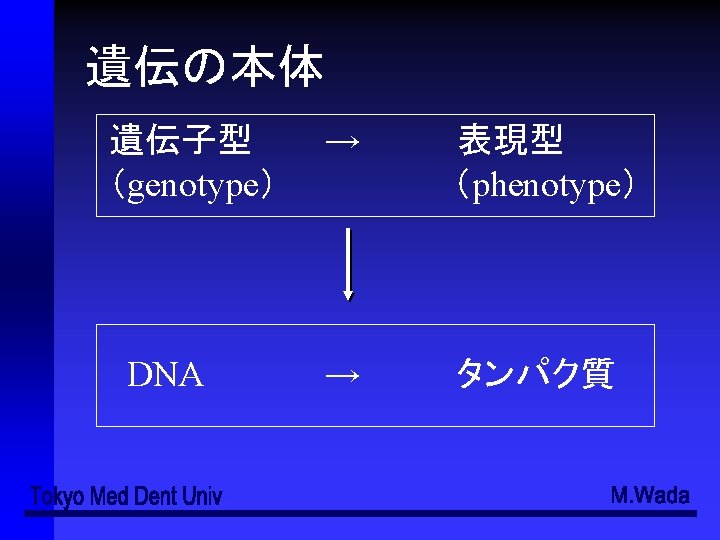


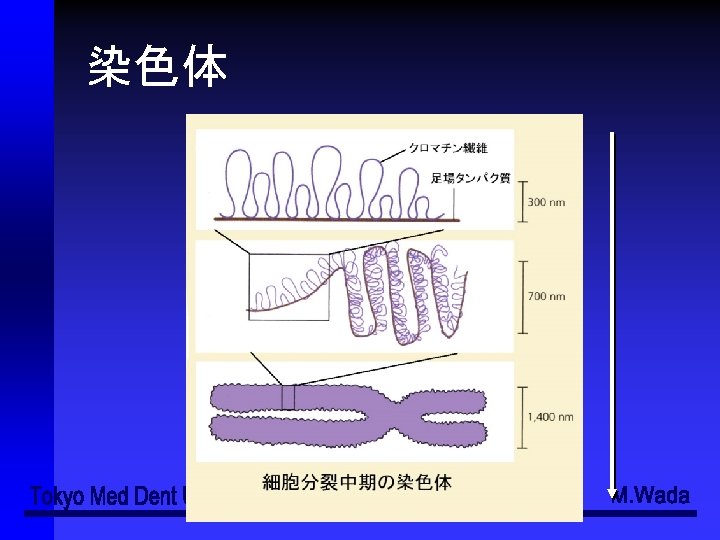
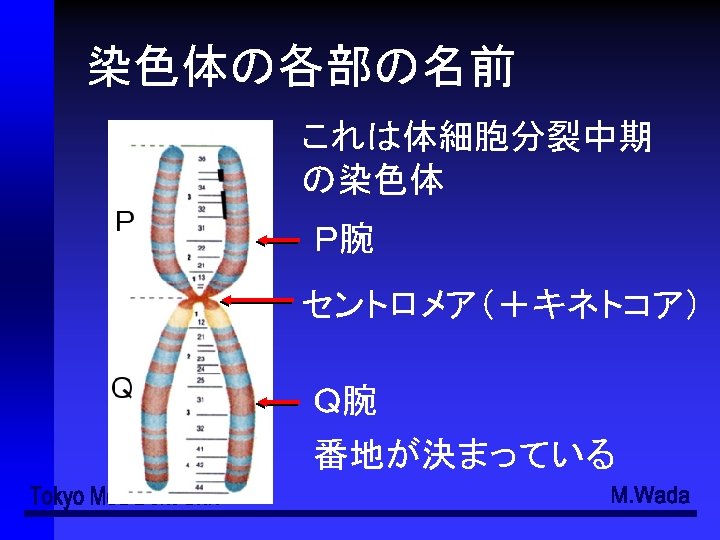

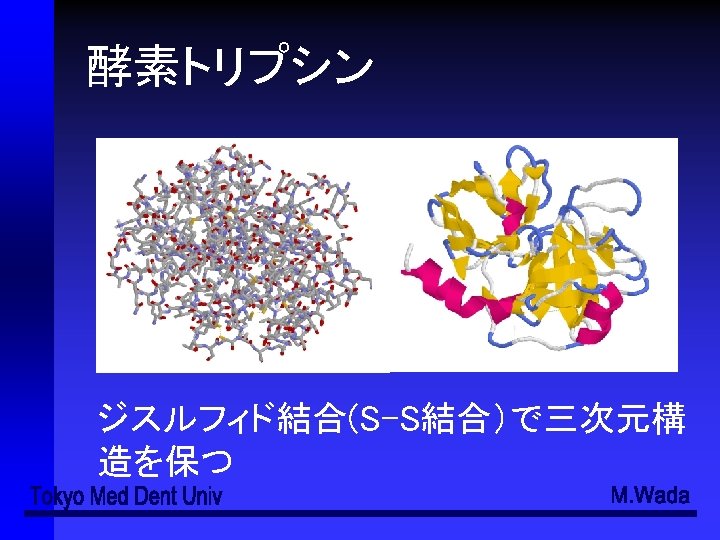
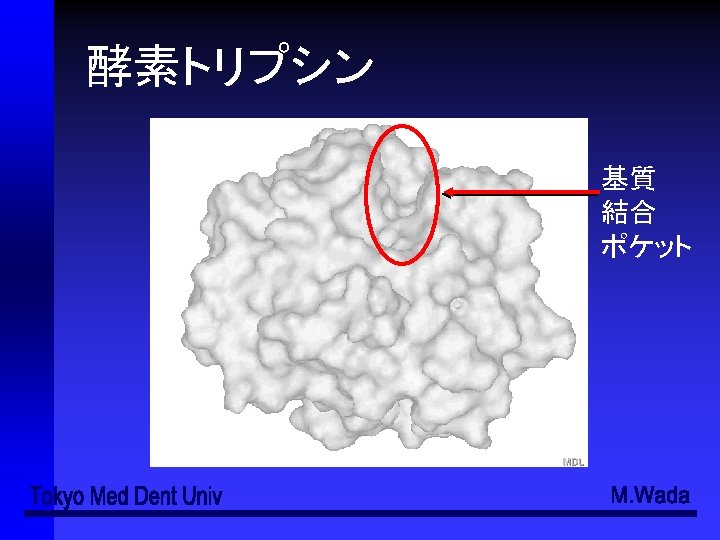
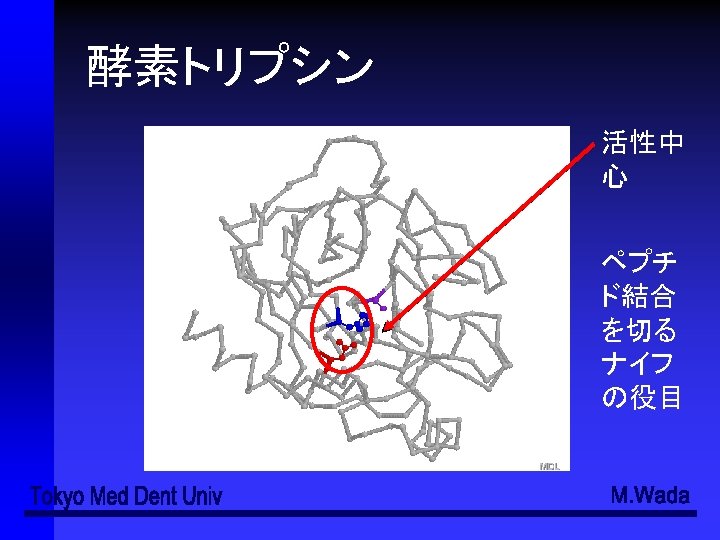


- Slides: 49
階層性 個体 (organism) 器官系 (organ system) 器官 (organ) 組織 (tissue) 細胞 (cell)
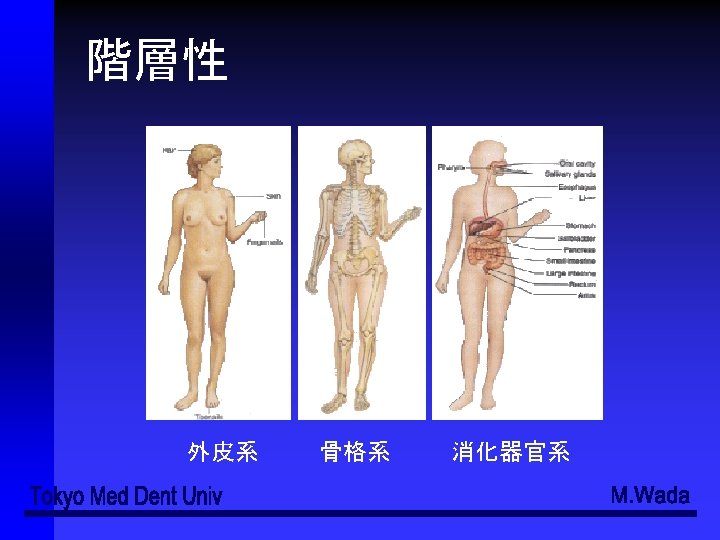
器官系 外皮系 (Integmentary system) ●骨格系 (Skeltal system) ●筋系 (Muscular system) ●消化器官系 (Digestive system) ●循環器官系 (Circulatory system) ●呼吸器官系 (Respiratory system) ●泌尿器官系 (Urinary system) ●神経系 (Nervous system) ●内分泌系 (Endocrine system) ●生殖器官系 (Reproductive system) ●
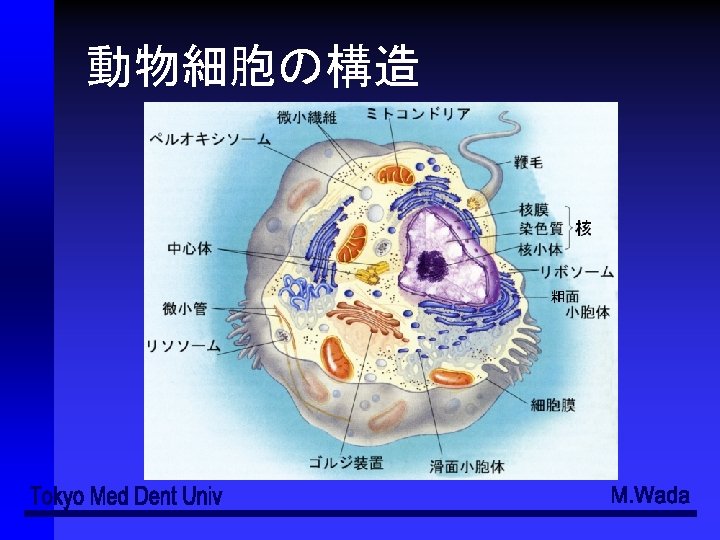
上皮組織 (1)上皮組織は、 単層扁平上皮 (simple squamous ep. ) ●単層立方上皮 (simple cuboidal ep. ) ●単層円柱上皮 (simple columner ep. ) ●重層扁平上皮 (stratified squamous ep. ) ●多列上皮 (pseudostratified ep. ) ●
遺伝の暗号 T 1 番 目 の 塩 基 C A G T Phe 2番目の塩基 C A Ser Tyr G Cys Phe Ser Tyr Cys Leu Ser Stop Leu Pro His Trp Arg Leu Pro His Arg Leu Pro Gln Arg Ile Thr Asn Ser Ile Thr Lys Arg Met Val Thr Lys Arg Ala Asp Gly Val Ala Glu Gly T C A G 3 番 目 の 塩 基
転写の過程 (5') ATGGAATTCTCGCTC(3')(コード鎖、sense strand) (3') TACCTTAAGAGCGAG(5')(鋳型鎖、antisense strand) (5‘) AUGGAAUUCUCGCUC(3’)(転写された一本鎖RNA) RNAの鎖の伸長は必ず5’→3’の方向
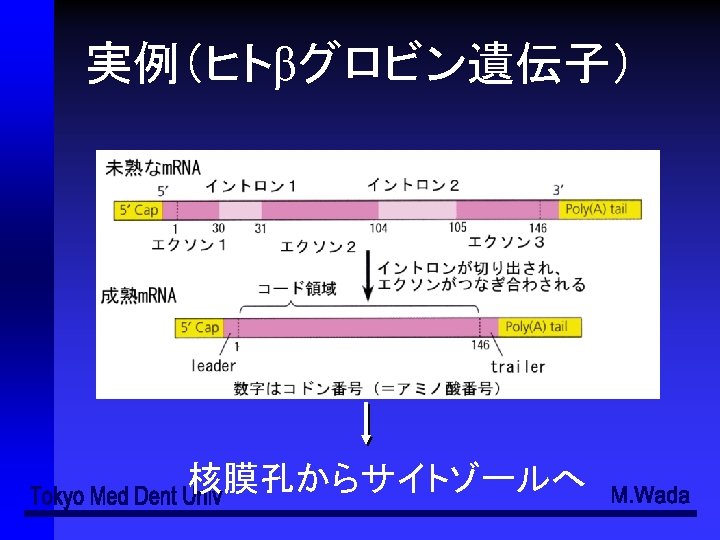
実例(ヒトβグロビン遺伝子) CCCTGTGGAGCCACACCCTAGGGTTGGCCAATCTACTCCCAGGAGCAGGGA GGGCAGGAGCCAGGGCTGGGCATAAAAGTCAGGGCAGAGCCATCTATTGCT TACATTTGCTTCTGACACAACTGTGTTCACTAGCAACCTCAAACAGACACC ATGGTGCACCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGC AAGGTGAACGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGTTGGTATCA AGGTTACAAGACAGGTTTAAGGAGACCAATAGAAACTGGGCATGTGGAGAC AGAGAAGACTCTTGGGTTTCTGATAGGCACTGACTCTGCCTATTGGT CTATTTTCCCACCCTTAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTT CTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCC TAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCT GGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGCTGCA CTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGGTGAGTCTATGGGA CCCTTGATGTTTTCCCCTTCTTTTCTATGGTTAAGTTCATGTCATAG GAAGGGGAGAAGTAACAGGGTACAGTTTAGAATGGGAAACAGACGAATGAT TGCATCAGTGTGGAAGTCTCAGGATCGTTTTAGTTTCTTTTATTTGCTGTT CATAACAATTGTTTTCTTTTGTTTAATTCTTGCTTTTTTTTTCTTCT CCGCAATTTTTACTATTATACTTAATGCCTTAACATTGTGTATAACAAAAG GAAATATCTCTGAGATACATTAAGTAACTTAAAAACTTTACACAGTC TGCCTAGTACATTACTATTTGGAATATATGTGTGCTTATTTGCATATTCAT AATCTCCCTACTTTATTTTCTTTTATTTTTAATTGATACATAATCATTATA CATATTTATGGGTTAAAGTGTAATGTTTTAATATGTGTACACATATTGACC AAATCAGGGTAATTTTGCATTTGTAATTTTAAAAAATGCTTTCTTCTTTTA ATATACTTTTTTGTTTATCTTATTTCTAATACTTTCCCTAATCTCTT TCAGGGCAATAATGATACAATGTATCATGCCTCTTTGCACCATTCTAAAGA ATAACAGTGATAATTTCTGGGTTAAGGCAATATTTCTGCATATAAATTGTAACTGATGTAAGAGGTTTCATATTGCTAAT AGCAGCTACAATCCAGCTACCATTCTGCTTTTATGGTTGGGATAAG GCTGGATTATTCTGAGTCCAAGCTAGGCCCTTTTGCTAATCATGTTCATAC CTCTTATCTTCCTCCCACAGCTCCTGGGCAACGTGCTGGTCTGTGTGCTGG CCCATCACTTTGGCAAAGAATTCACCCCACCAGTGCAGGCTGCCTATCAGA AAGTGGTGGCTGGTGTGGCTAATGCCCTGGCCCACAAGTATCACTAAGCTC GCTTTCTTGCTGTCCAATTTCTATTAAAGGTTCCTTTGTTCCCTAAGTCCA ACTACTAAACTGGGGGATATTATGAAGGGCCTTGAGCATCTGGATTCTGCC TAATAAAAAACATTTTCATTGCAATGATGTATTTAAATTATTTCTGA ATATTTTACTAAAAAGGGAATGTGGGAGGTCAGTGCATTTAAAACATAAAG AAATGAAGAGCTAGTTCAAACCTTGGGAAAATACACTATATCTTAAACTCC ATGAAAGAAGGTGAGGCTGCAAACAGCTAATGCACATTGGCAACAGCCCTG ATGCCTTATTCATCCCTCAGAAAAGGATTCAAGTAGAGGCTTGAT TTGGAGGTTAAAGTTTTGCTATGCTGTATTTTACATTACTTATTGTTTTAG CTGTCCTCATGAATGTCTTTTCACTACCCATTTGCTTATCCTGCATCTCTC AGCCTTGACTCCACTCAGTTCTCTTGCTTAGAGATACCACCTTTCCCCTGA AGTGTTCCATGTTTTACGGCGAGATGGTTTCTCCTCGCCTGGCCACT CAGCCTTAGTTGTCTCTGTTGTCTTATAGAGGTCTACTTGAAGAAGGAAAA ACAGGG GGCATGGTTTGACT……