OPe NDAP in the Cloud Optimizing the Use


















- Slides: 22
OPe. NDAP in the Cloud Optimizing the Use of Storage Systems Provided by Cloud Computing Environments OPe. NDAP James Gallagher, Nathan Potter and NOAA/NODC Deirdre Byrne, Jefferson Ogata, John Relph Originally presented at the Fall 2013 AGU Meeting in San Francisco
Cloud Systems Now* • Providers: IBM, Microsoft, Amazon, Google, Rackspace, … • Microsoft: Azure “… handles 100 petabytes of data a day” • Amazon: “…hundreds of thousands of users” • Netflix: “. . stopped building it’s own data centers in 2008; ” all in Amazon by 2012 • Snapchat: 4000 pictures per second; “…never owned a computer server. ” (Google cloud) *Quentin Hardy, “Google Joins a Heavyweight Competition in Cloud Computing, ” NY Times, 3 December 2013
Why use OPe. NDAP? Full dataset OPe. NDAP request 100% Download • • 4% Download The. OPe. NDAP request smaller and is just the data the person wants In cloud systems cost is a function of data transfer, in addition to to data stored, so smaller targeted requests reduce costs
NOAA Environmental Data Management Conceptual Cloud Architecture* *Aadapted from NOAA Environmental Data Management Framework Draft v 0. 3 Appendix C - Dr. Jeff de La Beaujardière, NOAA Data Management Architect Potential locations of cloud-enabled OPe. NDAP instances
Constraints • No vendor lock-in! • No Stovepipes! - flexible storage method • What will be the client of 2020? • Hierarchical/human browsable dataset file
Data stores: S 3 and Glacier • S 3 • Spinning disk with a flat file system • Designed to make web-scale computing easier • Glacier • Near-line device with 4 -hour (or >) access times • Secure and durable storage • EC 2 was used to run the OPe. NDAP data server • Linux
Using S 3 as a Data Store HTTP GET & HEAD requests S 3 Catalog Data
Web requests Catalog, or data request S 3 XML or data file
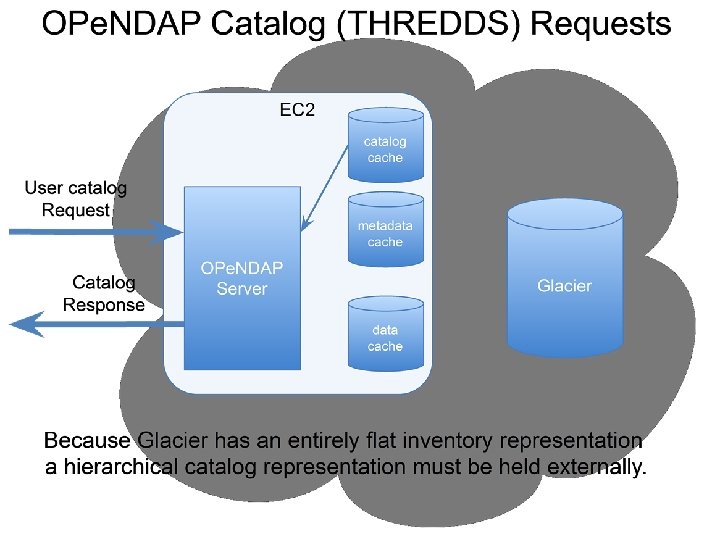
OPe. NDAP Catalog requests User catalog Request EC 2 OPe. NDAP Server THREDDS catalog or HTML catalog cache Catalog Access S 3 data cache XML File To enhance performance, data were accessed from S 3 only when not already cached.
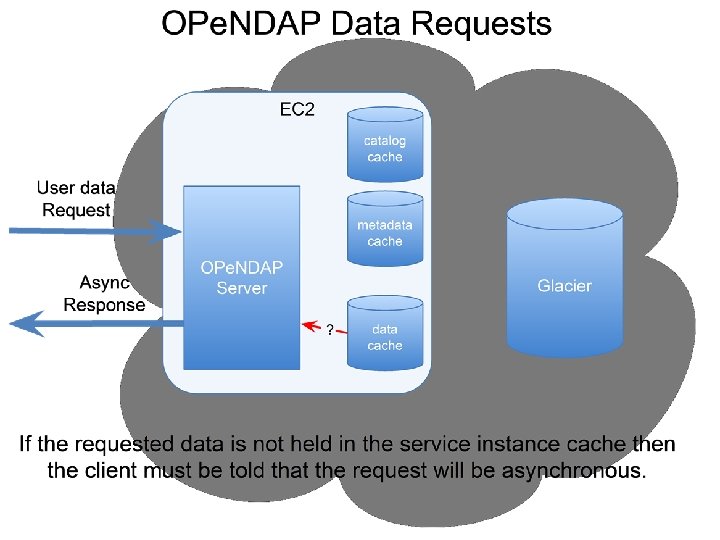
OPe. NDAP Data requests User data Request EC 2 OPe. NDAP Server Data Slice catalog cache Data Access S 3 data cache Data File To enhance performance, data were accessed from S 3 only when not already cached.
Observations • • • S 3 FS & Amazon's APIs: vendor lock-in XML catalogs were flexible: • • Support both direct web and… Subsetting server access Likely adaptable to other use-cases Easily support hierarchical structure Catalogs didn't need to be stored in S 3
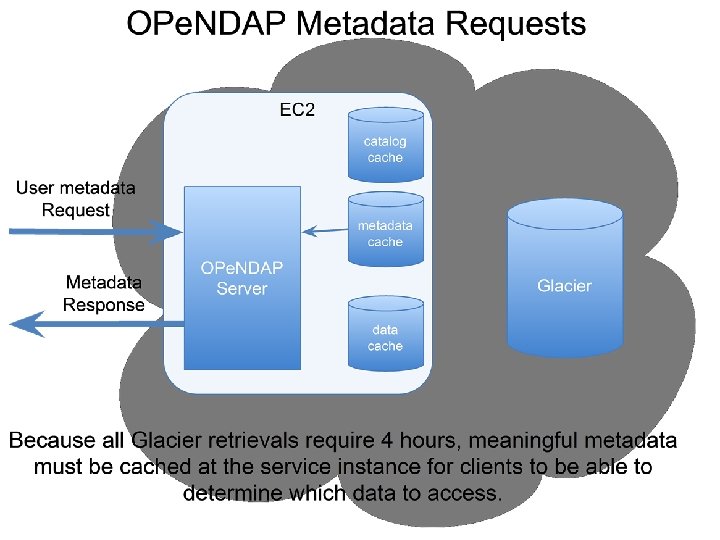
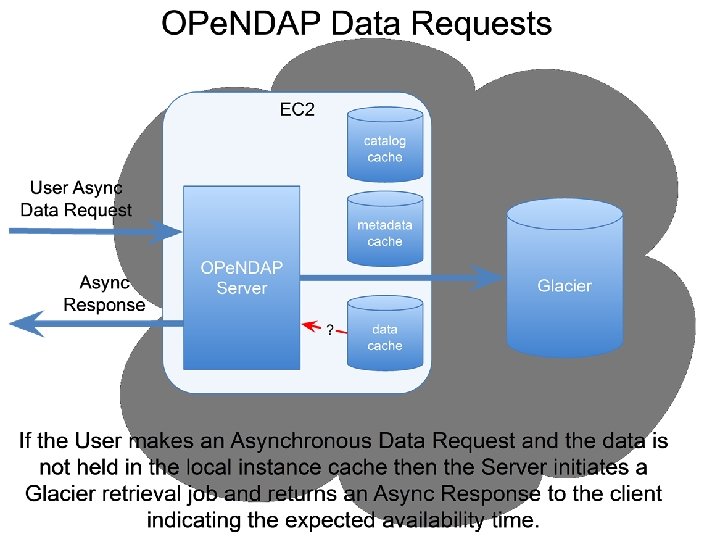
Glacier and Asynchronous Responses • To use Glacier, a web service protocol must • support asynchronous access! Glacier is a near-line device; not a spinning disk. Support via protocol is not enough: typical use cases cannot be met without caching ‘metadata’ o To support web interfaces/clients DAP metadata objects should be cached o To support smart clients, may need Range data in cache
Glacier Implementation • Caching o Catalog o DAP metadata • Support for programmatic and web clients o Web clients are the primary user of the DAP metadata because of their ‘click and browse’ behavior • XML with an embedded XSL style sheet o Single response (XML) o Multiple target clients – smart and browser
Comparison: S 3 and Glacier* • Glacier provides “secure and durable storage” • S 3 is “designed to make web-scale computing easier” • These graphs: A tiny part of complex cost model. They do not include the cost to move data out of the Amazon cloud, EC 2 instances, etc. *http: //calculator. s 3. amazonaws. com/calc 5. html
Summary • OPe. NDAP server with minimal changes • Data stored in S 3 and Glacier • Solution widely applicable: Web + Smart clients • Complexity of the cost model combination of both S 3 and Glacier likely • Modeling & Monitoring use required