Ontology Alignment Semantic Web Spring 2007 Computer Engineering

Ontology Alignment Semantic Web - Spring 2007 Computer Engineering Department Sharif University of Technology

The Problem p p Like the Web, the Semantic Web by design will be distributed and heterogeneous. Ontology is used in it to support interoperability and common understanding between different parties. Ontologies themselves may have some heterogeneities. Ontology Alignment is needed to find semantic relationships among entities of ontologies. ? ? a ? b c ? ? ? d How should I use them? !!! ?

Need for Ontology Merging p There is significant overlap in existing ontologies n n Yahoo! and DMOZ Open Directory Product catalogs for similar domains

Terminology p Mapping: a formal expression that states the semantic relation between two entities belonging to different ontologies. n n n Given two ontologies O 1 and O 2, mapping one ontology onto another means that for each entity (concept C, relation R, or instance I) in ontology O 1, we try to find a corresponding entity, which has the same intended meaning, in ontology O 2. map(e 1 i) = e 2 j Complex mappings are not addressed: n: m, concept-relation, … p Ontology Alignment: a set of correspondences between two p Ontology Coordination: broadest term that applies whenever p Ontology Transformation: a general term for referring to or more (in case of multi-alignment) ontologies. These correspondences are expressed as mappings. knowledge from two or more ontologies must be used at the same time in a meaningful way (e. g. to achieve a single goal). any process which leads to a new ontology o 0 from an ontology o by using a transformation function t.
 Automobile : Ontology")
An Example of Alignment Car : Ontology A ( ? ) Automobile : Ontology B

Terminology cont. p Ontology Translation: an ontology transformation function t for translating an ontology o written in some language L into another ontology o’ written in a distinct language L’. p Ontology Merging: the creation of a new ontology from two (possibly overlapping) source ontologies. This concept is closely related to that of integration in the database community. p Ontology Reconciliation: a process that harmonizes the content of two (or more) ontologies, typically requiring changes on one of the two sides or even on both sides.

An Example of Ontology Merging Bus Sport Car Object Thing Vehicle Automobile Car Luxury Car Sport Car Family Car Porsche BMW

An Example of Ontology Merging Bus Sport Car Object Thing Vehicle Automobile Car Luxury Car Sport Car Family Car Porsche BMW

An Example of Ontology Merging Bus Sport Car Object Thing Vehicle Automobile Car Luxury Car Sport Car Family Car Porsche BMW

An Example of Ontology Merging Object, Thing Vehicle Bus Sport Car, Automobile Luxury Car Family Car BMW Porsche

Process Iterations Features Input Entity Pair Selection Similarity Aggregation Interpretation Output

Features Object Vehicle has. Owner Boat Owner Marc Car Porsche KA-123 has. Speed 250 km/h

Similarity Measure p String similarity p Object Similarity p Set similarity

Similarity Rules Concepts Feature Similarity Measure label String Similarity subclass. Of Set Similarity instances Set Similarity … Relations Instances

Combination p How are the individual similarity measures combined? p Linearly Weighted Special Function p p
 = e 2")
Interpretation p From similarities to mappings p Threshold map(e 1 j) = e 2 j ← sim(e 1 j , e 2 j)>t p

Forms of Heterogeneity in Ontologies p Syntactic: depend on the choice of the representation n p OWL, RDFS, DAML, N 3, DATALOG, PROLOG, … Terminological: all forms of mismatches that are related to the process of naming the entities (e. g. individuals, classes, properties, relations) that occur in an ontology. n Typical Examples: p p n different words are used to name the same entity (synonymy); the same word is used to name different entities (polysemy); words from different languages (English, French, etc. ) are used to name entities; syntactic variations of the same word (different acceptable spellings, abbreviations, use of optional prefixes or suffixes, etc. ). Mismatches at the terminological level are not as deep as those occurring at the conceptual level. However, Most real cases have to do with the terminological level (e. g. , with the way different people name the same entities), and therefore this level is at least as crucial as the other one.

Heterogeneity in Ontologies, cont. p Conceptual: we encounter mismatches which have to do with the content of an ontology. n Metaphysical differences: which have to do with how the world is “broken into pieces”. p Coverage: cover different portions – possibly overlapping– of the world. p p Granularity: One ontology provides a more (or less) detailed description of the same entities. Perspective: an ontology may provide a viewpoint, which is different from the viewpoint adopted in another ontology.

Heterogeneity in Ontologies, cont. Metaphysical differences:

Overcoming Heterogeneity p One common approach to the problems of heterogeneity is the definition of relations across the heterogeneous representations. p These relations can be used for transforming expression of one ontology into a form compatible with that of the other. p This may happen at any level: n syntactic: through semantic-preserving transducers; n terminological: information; n through functions mapping lexical conceptual: through general transformation of the representations (sometimes requiring a complete prover for some languages);

Structure of Mapping p p Alignment: a process that starts from two representations o and o’ and produces a set of mappings between pairs of (simple or complex) entities <e, e’> belonging to O and O’ respectively. Intuitively, we will assume that in general a mapping can be described as a quadruple: <e, e’, n , R> n e and e’ are the entities between which a relation is asserted by the mapping. n n is a degree of trust (confidence) in that mapping. n R is the relation associated to a mapping, where R identifies the relation holding between e and e’. p simple set-theoretic relation p a fuzzy relation p a probabilistic distribution over a complete set of relations p a similarity measure

Similarity p p There are many ways to assess the similarity between two entities. The most common way amounts to defining a measure of this similarity. The characteristics which can be asked from these measures:

Overcoming Heterogeneity Using Similarity p Local Methods n Terminological Methods p p p n Structural Methods p p n String Based Methods Token Based Methods Language Based Methods Internal Structure Extensional (based on instances) Methods p When the classes share the same instances p When they do not

Terminological Methods p Terminological methods compare strings. p Can be applied to: n n name, label comments concerning entities URI p Take advantage of the structure of the string (as a sequence of letter). p The main idea in using such measures is the fact that usually similar entities have similar names and descriptions in different ontologies.
 p There a number of normalization procedures that help")
Terminological M. , cont. (Normalization) p There a number of normalization procedures that help improving the results of subsequent comparison: n Case normalization: consists of converting each alphabetic character in the strings in their down case counterpart; n Diacritics suppression: replacing characters with diacritic signs with their most frequent replacement (replacing Montréal with Montreal); n n n Blank normalization: Normalizing all blank characters (blank, tabulation, carriage return) into a single blank character; Link stripping: normalizing some links between words (like replacing apostrophes and blank underline into dashes; Stopword elimination: eliminates words that can be found in a list (usually like, “to”, “a". . . ).
 p p p Substring Similarity Hamming Distance N-Gram")
Terminological M. , cont. (String Based) p p p Substring Similarity Hamming Distance N-Gram Distance Edit Distance Jaro Similarity Token Based Distances n Term Frequency Inverse Document Frequency (TF/IDF) n Path Distance : not only the labels of objects but the sequence of labels of entities to which those bearing the label are related.
 p In string edit distance, the operations usually")
Terminological M. , cont (String Methods) p In string edit distance, the operations usually considered are insertion of a character, replacement of a character by another and deletion of a character. p Levenstein Distance is an Edit Distance with all costs to 1.
 p p p Rely on using NLP techniques")
Terminological M. , cont. (Language Based) p p p Rely on using NLP techniques to find associations between instances of concepts or classes. Intrinsic methods: perform the terminological matching with the help of morphological and syntactic analysis to perform term normalization. (Stemming) : going go Extrinsic methods: make use of external resources such as dictionaries and lexicons (Wordnet). n Resnik Semantic Similarity

Structural Methods p The structure of entities that can be found in ontology can be compared, instead of comparing their names or identifiers. p Internal Structure: use criteria such as the range of their properties (attributes and relations), their cardinality, and the transitivity and/or symmetry of their properties to calculate the similarity between them. p External Structure: The similarity comparison between two entities from two ontologies can be based on the position of entities within their hierarchies.
 p If two entities from two ontologies are similar, their neighbors")
Structural Methods (External) p If two entities from two ontologies are similar, their neighbors might also be somehow similar. p Criteria for deciding that the two entities are similar include: n n n n Their direct super-entities are already similar. Their sibling-entities are already similar. Their direct sub-entities are already similar. All (or most) of their descendant-entities (entities in the sub tree rooted at the entity in question) are already similar. All (or most) of their leaf-entities are already similar. All (or most) of entities in the paths from the root to the entities in question are already similar.
, cont. p Existing Approaches: n n Structural topological dissimilarity on hierarchies")
Structural Methods (External), cont. p Existing Approaches: n n Structural topological dissimilarity on hierarchies Upward Cotopic Distance
 Methods p Compares the extension of classes, i. e. ,")
Extensional (based on instances) Methods p Compares the extension of classes, i. e. , their set of instances rather than their interpretation. p Conditions in which such techniques can be used: n When the classes share the same instances n When they do not

Global Methods p After calculation of local similarity, it is remain to compute the alignment. This involve some kind of more global treatments, including: p p p aggregating the results of these base methods in order to compute the similarity between compound entities developing a strategy for computing these similarities in spite of cycles and non linearity in the constraints governing similarities organizing the combination of various similarity / alignment algorithms involving the user in the loop finally extracting the alignments from the resulting (dis)similarity

Compound similarity

Global similarity computation p p p The computation of compound similarity is still local because it only provides similarity considering the neighborhood of a node. Similarity may involve the ontologies as a whole and the final similarity values may ultimately depend on all the ontologies. The distance defined by local methods can be defined in a circular way. (for instance if the distance between two classes depends on the distances between their instances which themselves depends on the distance between their classes or if there are circles in the ontology). p Strategies must be defined in order to compute this global similarity. n n Similarity Flooding Similarity equation fix point
 p Two ontologies are first translated into directed labeled graphs.")
Global similarity (Similarity Flooding) p Two ontologies are first translated into directed labeled graphs. p Creates another graph G whose nodes are pairs of nodes of the initial graphs and there is an edge between (o 1, o’ 1) and (o 2, o’ 2) labeled by p whenever there are edges (o 1, p, o 2) in the first graph and (o’ 1, p, o’ 2) in the second one. p computes initial similarity values between nodes (based on their labels for instance) and then iterates steps of re-computing the similarities between nodes in function of the similarity between their adjacent nodes at the previous step. p It stops when no similarity changes more than a particular threshold or after a predetermined number of steps. p Use a weighted linear aggregation in which the weight of an edge is the inverse of the number of other edges with the same label reaching the same couple of entities.

Learning Methods p p Like in many other fields, learning methods developed in machine learning reveals useful in ontology alignment. Two particular areas: n supervised learning in which the ontology alignment algorithm learns how to work through the presentation of many good alignment (positive examples) and bad alignments (negative examples). p it is difficult to know which techniques works well for which ontology features. p An ontology alignment algorithm learnt with several ontology pairs, might not necessarily work well for a new ontology pair. n Learning from data in which a population of instances is communicated to the algorithm together with theirs relations and the classes they belong to.

Users Feed Back p The support of effective interaction of the user with the system components is one concern of ontology alignment. p User input can take place in many areas of alignment: n Assessing initial similarity between some terms; n Invoking and composing alignment methods; n Accepting or refusing similarity or alignment provided by the various methods.

Alignment Extraction p p p The ultimate alignment goal is a satisfactory set of correspondences between ontologies. Manual Extraction: Display the entity pairs with their similarity scores and/or ranks and leaving the choice of the appropriate pairs up to the user of the alignment tool. Automatic Extraction: n Using Thresholds p Hard threshold retains all the correspondence above threshold n; p Delta method consists in using as a threshold the highest similarity value to which a particular constant value d is subtracted; p Proportional method: consists in using as a threshold the a percentage of the highest similarity value; p Percentage: retains the n% correspondences above the others.

Alignment Extraction, cont. p Automatic Extraction n Using Optimization of the result p if an injective mapping is required then some choices need to be made in order to maximize the “quality” of the alignment. p that is typically measured on the total similarity of the aligned entity pairs. p A greedy alignment algorithm could construct the correspondences step-wise, at each step selecting the most similar pair and deleting its members from the table. The algorithm will then stop whenever no pair remains whose similarity is above threshold. (Not Optimal) p Optimal Solution: Stable Marriage

Existing Works Features Automatic Structure Project Leader Instance Organization Semantic Year String Method Aggregation Lexical Onto. Morph 1997 S. California Chalupsky Semi T U. S. Army 1999 DARPA Semi T Smart 1999 Sanford Fridman, Noy Semi T T Chimaera 1999 Stanford Mc. Guinness Semi T T T Prompt 2001 Stanford Noy, Musen Semi T T Info. Slueth 2001 Amsterdam Ding Semi T T A. Prompt 2002 Stanford Noy, Musen Semi T T T Glue 2002 Illinois Doan Automatic T T IF Map 2003 Southampton Kafoglou Automatic T T NOM 2003 Karlsruhe Ehric Automatic T T T QOM 2004 Karlsruhe Ehric Automatic T T CROSI 2005 Southampton Kafoglou Automatic T T T

Anchor-prompt
")
An Example: Anchor Prompt Method p p p The Anchor-PROMPT (an extension of PROMPT) is an ontology merging and alignment tool for possible matching terms. Implemented in Protégé http: //protege. stanford. edu Incremental algorithm n n n Takes as input two ontologies and a set of anchors-pairs of related terms. Anchors are identified with the help of string-based techniques, or defined by a user. Then it refines them based on the ontology structures and users feedback.

The PROMPT Algorithm Make initial suggestions Select the next operation Perform automatic updates Find conflicts Make suggestions

Example: merge-classes Agency employee subclass of Agent Agency employee Employee subclass of Agent has client agent for Customer Traveler
 Agency employee Employee subclass of Agency employee Customer subclass of Agent")
Example: merge-classes (II) Agency employee Employee subclass of Agency employee Customer subclass of Agent agent for Employee has client Traveler agent for Customer Traveler

Analyzing Global Properties Locally p Global properties n n n p classes that have the same sets of slots classes that refer to the same set of classes slots that are attached to the same classes Local context n n incremental analysis consider only the concepts that were affected by the last operation

The PROMPT Operation Set p Extends the OKBC operation set with ontology-merging operations n n merge classes merge slots merge instances copy of a class p p p n … deep or shallow with or without subclasses with or without instances

After a User Performs an Operation p For each operation n n perform the operation consider possible conflicts p p n n n identify conflicts propose solutions analyze local context create new suggestions reinforce or downgrade existing suggestions

Conflicts p Conflicts that PROMPT identifies n n name conflicts dangling references redundancy in a class hierarchy slot-value restrictions that violate class inheritance

Example: merge-classes Agent

Operation Steps: merge-classes p Own slot and their values for the new class ask the user in case of conflicts or use preferences p Template slots for the new class union of template slots of the original classes p p p Subclasses and superclasses for the new class Conflicts Suggestions

Template Slots Copy template slots that don’t exist in the merged ontology Agent agent for

Template Slots Attach the slots that have already been mapped Agent has client Agent client
 exists, re-establish the links Agency employee superclass")
Subclasses And Superclasses If a superclass (subclass) exists, re-establish the links Agency employee superclass Agent Employee superclass Agent

Dangling References For example, allowed class Customer facet value Agent agent for dummy frame Customer _temp Agent facet value agent for

Additional Suggestions: Merge Slots If slot names at the merged class are similar, suggest to merge the slots Agent client has client

Additional Suggestions: Merge Classes If the set of classes referenced by the merged class is the same as the set of classes referenced by another class, suggest a merge Agency employee Agent has clients Client handles reservations Reservation
 of the merged class are")
Additional Suggestions: Merge Classes If names of superclasses (subclasses) of the merged class are similar, suggest to merge the classes Employee superclass Agent Agency employee superclass

To Summarize p p Perform the actual operation For the concepts (classes, slots, and instances) directly attached to the operation arguments n n perform global analysis for new suggestions Perform global analysis for new conflicts

Context Non-local context Classes directly referenced by C Slots in C C

Anchor-PROMPT: Using Non-Local Contexts Ontology 1 Ontology 2 p Input: n p Output: n p A set of anchor pairs A set of related terms with similarity scores Where do anchors come from? n n n Lexical matching Interactive tools User-specified

Generating Paths in the Graph
")
Similarity Score n n Generate a set of all paths (of length < L) Generate a set of all possible pairs of paths of equal length For each pair of paths and for each pair of nodes in the identical positions in the paths, increment the similarity score Combine the similarity score for all the paths

Equivalence Groups

Anchor-PROMPT: Initial Results TRIAL Trial PERSON CROSSOVER Person Crossover PROTOCOL Design TRIAL-SUBJECTPerson INVESTIGATORS Person POPULATION Action_Spec PERSON Character TREATMENT-POPULATION Crossover_arm

Knowledge Model Assumptions The only assumption: An OKBC-compliant knowledge model

Protégé-2000 p An environment for n n p p Ontology development Knowledge acquisition Intuitive direct-manipulation interface Extensibility n Ability to plug in new components

Ontologies in Protégé-2000

Protégé-200 plugins p p Domain-specific user-interface plugins Alternative back ends for archival storage Utility programs for knowledge-acquisition tasks End-user applications

Protégé-based PROMPT tool p Protégé-2000 n n has an OKBC-compatible knowledge model allows building extensions through a plug-in mechanism p can work as a knowledge-base server for the plug-ins

The PROMPT tool
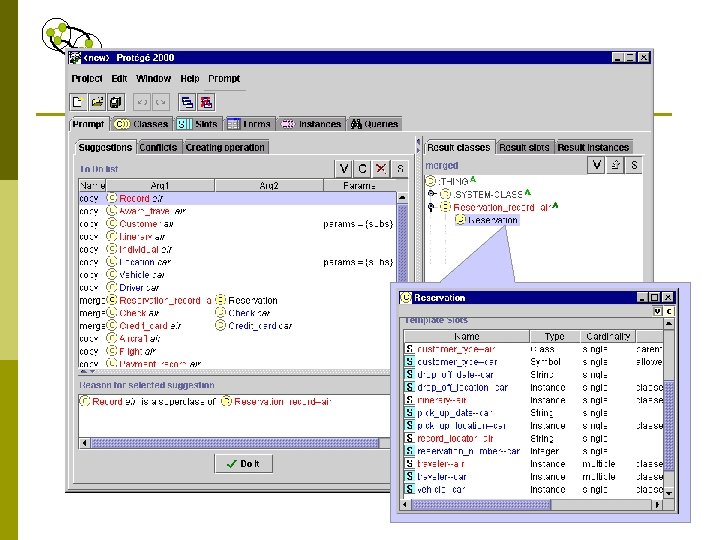

The PROMPT tool features p p p Setting a preferred ontology Maintaining the user’s focus Providing feedback to the user Preserving original relations n subclass-superclass relations n slot attachment n facet values Linking to the direct-manipulation ontology editor Logging operations

Coincidence based refinement

Introduction: Framework p The final steps of each phase

Coincidence or Being the same? • Geometrically Equivalent • Perfectly the same! • Not the same however! • Perfectly coinciding Less the same because they coincide less! More the same because they coincide more!

Background – Metric Space p p p Our interpretation from the output of phase#1 d(p, q) > 0 iff p ≠ q; d(p, p) = 0 d(p, q) = d(q, p) d(p, q) ≤ d(p, r) + d(r, q) S d? q p d is a metric, and X is a metric space.
 Set of Vertices Set of Edges •")
Background – Typed Graphs G(V, E, T) Set of Vertices Set of Edges • Set of Types • Types of Edges • such as t 0, , t 1, and t 2 above

Refinement of Ontology Alignment: Problem Specification • How much each possible matching is good • O 1 or G 1: First Ontology • Interpreted as the first Typed Graph • O 2 or G 2: Second Ontology • Interpreted as the second Typed Graph Coincidence Examiner (for Refinement) • Based on how much matching each pair of nodes can improve the amount to which the two ontologies seem coinciding. d: a metric showing the distance between each pair of node from O 1 and O 2.

Desired Properties for the Coincidence Examiner Big Benefit Modes t Benefit Low Penalt y Modes t Penalt y Low Benefit Big Penalt y

Our Proposed Formula • f and g: normalisation factors • Both restrictively increasing • Range outside certain neighbourhoods around origin

Commentary p No symmetry Quasi Metric Spaces p No way to guarantee triangular inequality but rational No tractable solution for the typed graph isomorphism problem Heuristics for dealing with it in a P time OWL-related heuristics p p p
 Discard and Contraction: • IS-A: contraction/expansion • Disjoint: distance-based removal •")
OWL-based Heuristics (1#2) Discard and Contraction: • IS-A: contraction/expansion • Disjoint: distance-based removal • Equivalent: accumulation • owl: functional. Property: mapped only to a functional property
 p No Cross!")
OWL-based Heuristics (2#2) p No Cross!
 1. 2. 3. 4. 5. 6. Input O and O’ Apply")
Altogether (Our Algorithm) 1. 2. 3. 4. 5. 6. Input O and O’ Apply a threshold-based refinement on O and O’ Apply recipes for Discard and Contraction on the resulting. Weight all the remained possible mapping. Expand back the contracted parts. Output mappings along with their weights

Example Before Contraction After Contraction Final Mapping

The End
- Slides: 88