One Tool Many Industries Text Mining with Oracle





")























- Slides: 32
One Tool, Many Industries Text Mining with Oracle Omar Alonso Chuck Adams Oracle Corp. Text Mining Summit, Boston, 2005
Agenda Ÿ Introduction Ÿ Text mining Ÿ Define problems Ÿ Present solutions Ÿ A look at Oracle’s technology stack Ÿ Oracle’s roadmap Ÿ A case study Ÿ Conclusions
Data mining and Text mining DM TM OLAP BK OLTP Keyword search Structured Data Unstructured Data • Classification • Clustering • Ontologies • NLP • Inexact match
An analogy Ÿ RFID and robot vision – Put tags on everything instead having the robot do the vision Ÿ Similar approach for text mining – – – Language is very social, not technical Instead, start with a unified storage model Then do mining
What about text mining? Ÿ Text mining is one of many features in text technology Ÿ Real future of text technology is business intelligence (BI) Ÿ What is BI? – Ability to make better decisions Ÿ What are the obstacles today? – – Structured data is well understood Unstructured data is different
Text and XML Traditional Content Mgmt Plain Old File System on Steroids (Win. FS) Records Mgmt, ECM XML Content Mgmt. Dynamic Doc Generation Increased exploitation of structure
First problem: access Ÿ No uniform access over all sources Ÿ Each source has separate storage and algebra Ÿ Examples – – Email Databases Applications Web
Second problem: management Ÿ Management of unstructured of data very poor compared with structure data Ÿ Cleaning Ÿ Noise is larger than in structure data Ÿ Security Ÿ Multilingual
Third problem – user needs Ÿ Perception with current search engines Ÿ Large data -> 80/20 rule Ÿ Doesn't provide uniform information Ÿ Two users type same query and get the same results – Cricket the game or cricket the bug?
Foundations Ÿ XML as the common model Ÿ XML allows: – – – Manipulation data with standards Mining becomes more data mining RDF emerging as a complementary model Ÿ The more structure you can explore the better you can do mining Ÿ Integration use cases
Foundations - II Ÿ Unstructured data is too AI Ÿ Too easy to get fooled by the complexity Ÿ Hybrid solution Ÿ Domain knowledge – – – You know your domain You own the content You can do better
Remember?
Personalization problem Ÿ Lack of personalization Ÿ You own the content, you own the user Ÿ Two users type the same query: “financials” – – Sales rep looks for customers and other deals Tech guy looks for bugs, architecture, etc. Ÿ LDAP shows who they are Ÿ Combination with query logs shows patterns in the same peer group Ÿ Recommendation systems
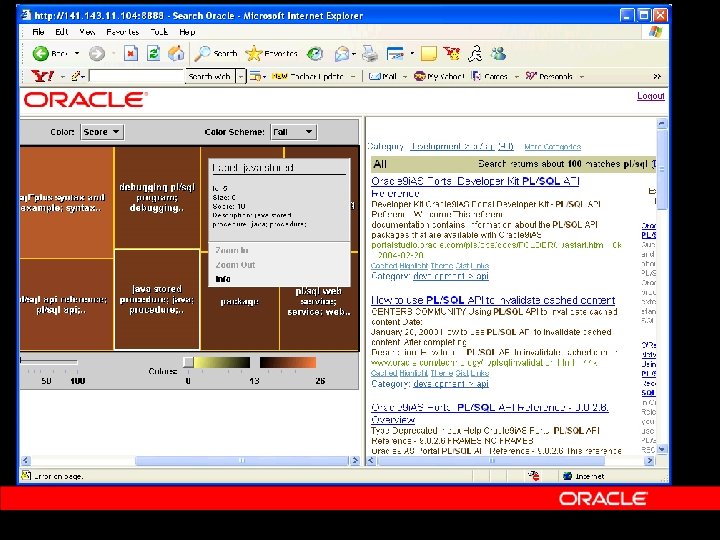
Better Answers: Beyond Keywords Ÿ Noise theory – As you cast your nets ever wider, you catch disproportionately more junk Ÿ Must develop new models of Quality in the face of comprehensiveness – – Combine Link-Analysis with Context-sensitive relevance Personalization Ÿ Must summarize information – Theme Maps, Gists Ÿ Show patterns in information vs. many pages of hit-lists – Tree Maps, Stretch Viewer Ÿ Ability to post-process and refine search hit lists – – Dynamic categories for navigation Reorder by date Ÿ Progressive query relaxation – Nearest inexact match
Technology Stack Better Answers Relevance Toward BI Keyword Ranking Multi-Criterion Support Link Analysis Progressive Relaxation Query Log Analysis Classification Metadata Extraction Visualization Intelligent Match Personalization Duplicate Elimination Direct Answers
Oracle’s position Ÿ Text mining is one of many tools for information retrieval and discovery in many assets Ÿ Text mining is best used in the context of other techniques – – – Personalization Search query logs Visualization Ÿ Product: one integrated platform
Oracle platform Ÿ Integrated platform vs. niche technology Full-text searching Google, FAST XML Tamino Classification Autonomy Clustering Vivisimo Visualization Inxight Application search SAP/TREX One platform, low cost, low complexity Several products, different APIs, performance, maintenance cost, etc.
Oracle platform Ÿ “If I can see further than anyone else, it is only because I am standing on the shoulders of giants” – Isaac Newton Ÿ Oracle provides you all the functionality – Plus you get backup, recovery, scalability, and other benefits Ÿ You build the mining application
Case study Ÿ Federal customer Ÿ High Performance Text Information Mining and Entity Extraction
Business Need Ÿ Enterprise Search Capability Ÿ Information Fusion Ÿ Profiles and alerting Ÿ Security – user need to know Ÿ Entity identification and extraction Ÿ High Performance ingestion, search, and indexing Ÿ Scalability
Challenges Ÿ Search quality Ÿ Performance Ÿ Scalability Ÿ Document formats Ÿ Integration Ÿ Operations and maintenance
Solutions Architecture Ÿ Oracle 10 g Integrated Framework Ÿ 10 g release 2 – – Oracle Real Application Clusters Oracle Text ŸFull text and rule based indexing ŸExtensible thesauri ŸDocument classification ŸDocument filters – – – Oracle Partitioning Oracle Virtual Private database Oracle Advanced Security
Technical Architecture
Scalable load and indexing
Real world results Ÿ Single search for user Ÿ Profiles and alerts Ÿ Couple second query response Ÿ 80, 000 + documents indexed Ÿ 1. 2 TB raw text and growing Ÿ 700 Gig index size Ÿ Incremental index 1 -2 Gig / day
Next Steps • Entity Extraction and Relationship Awareness
Oracle database 10 g release 2 Ÿ Enterprise Search Capability Ÿ Information Fusion Ÿ Profiles and alerting Ÿ Security – user need to know Ÿ Entity identification and extraction Ÿ High Performance ingestion, search, and indexing Ÿ Scalability
Conclusions Ÿ Text mining is one of many features needed for BI on unstructured data – Not a silver bullet in itself Ÿ Must exploit other approaches – metadata (XML, RDF), personalization, classification, entity extraction, full-text search, … – Hybrid solution Ÿ Focus on an integrated platform that gives you all the functionality Ÿ Drive the platform for your information need