On the Relationship between Self Attention and Convolutional

On the Relationship between Self. Attention and Convolutional Layers Jean-Baptiste Cordonnier, Andreas Loukas & Martin Jaggi Blog - http: //jbcordonnier. com/posts/attention-cnn/ Demo - https: //epfml. github. io/attention-cnn/ Github - https: //github. com/epfml/attention-cnn

Abstract Do learned attention layers operate similarly to convolutional layers?

Contributions • In this work, we put forth theoretical and empirical evidence that self-attention layers can (and do) learn to behave similar to convolutional layers: 1. From a theoretical perspective, we provide a constructive proof showing that selfattention layers can express any convolutional layers. Specifically, we show that a single multi-head self-attention layer using relative positional encoding can be re-parametrized to express any convolutional layer 2. Our experiments show that the first few layers of attention-only architectures do learn to attend on grid-like pattern around each query pixel, similar to our theoretical construction. https: //epfml. github. io/attention-cnn/
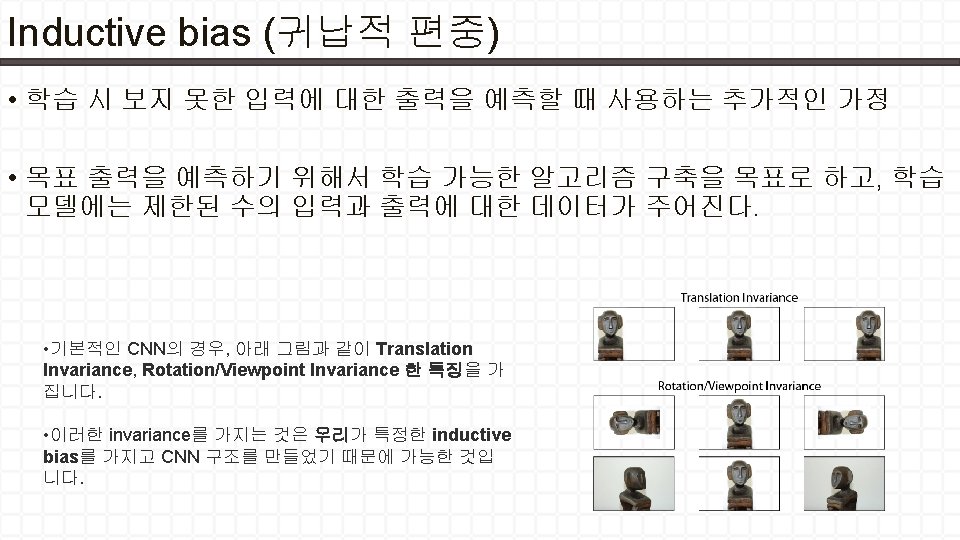

Attention Mechanisms •

Attention Mechanisms •

Attention For Images •

Attention For Images •

Positional Encoding for Images •

Positional Encoding for Images •
 between word")
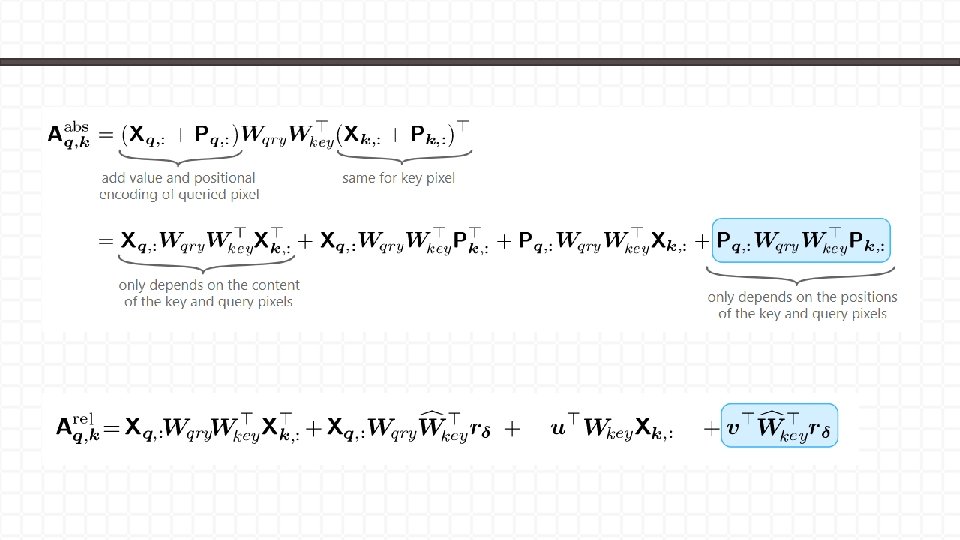
Self-Attention as a Convolutional Layer They represent the distance (number of words) between word i and j, hence the name Relative Position Representation (RPR).

Main Theorem •
 q k relative k =")
Positional Encoding for Images absolute k = (2, 3) q k relative k = (1, 2)

Main Theorem

Figure 1
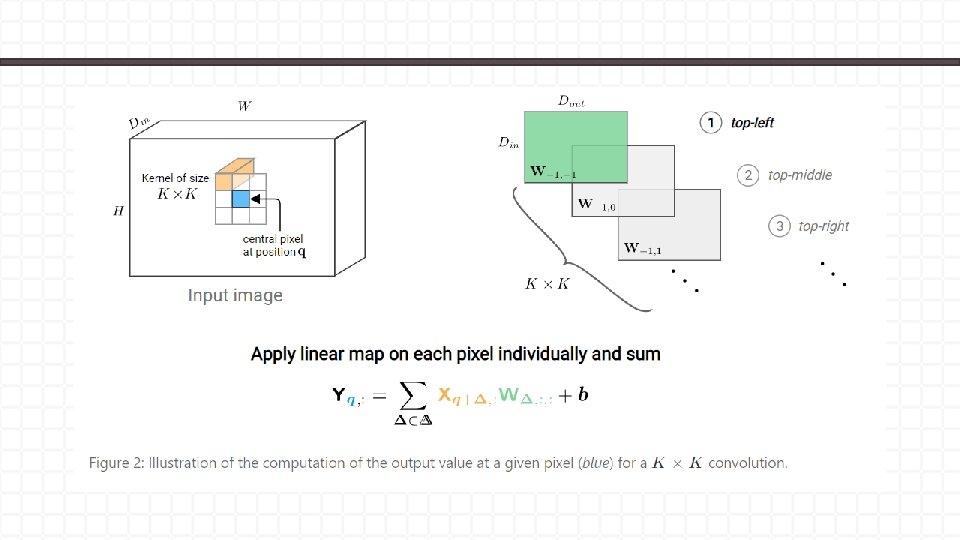

Lemma 1. local한 영역?

Lemma 1.


Lemma 2 : The aforementioned condition is satisfied for the relative positional encoding that we refer to as the quadratic encoding.

Lemma 2.

Lemma 2.

Lemma 2.

Experiments • In all experiments, we use a 2 × 2 invertible downsampling (Jacobsen et al. , 2018) on the input to reduce the size of the image. • As the size of the attention coefficient tensors (stored during forward) scales quadratically with the size of the input image, full attention cannot be applied to bigger images.

Quadratic Encoding

Quadratic Encoding

Quadratic Encoding

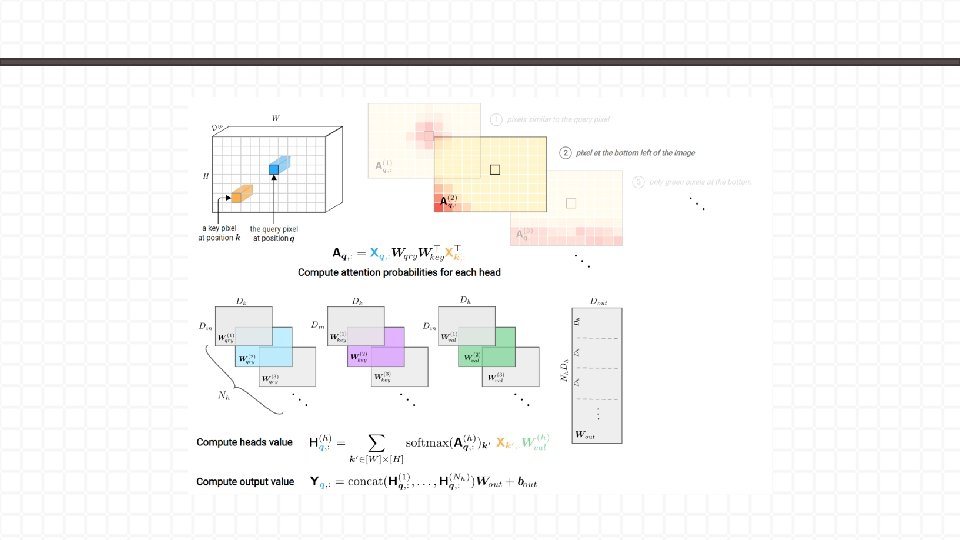
Learned Relative Positional Encoding •

Learned Relative Positional Encoding The attention probabilities displayed on Figure 5 show that, indeed, self-attention behaves similarly to convolution. Each head learns to focus on different parts of the images, important attention probabilities are in general very localized. We can also observe that the first layers (13) concentrate on very close and specific pixels while deeper layers (4 -6) are attending on more global patches of pixels over whole regions of the image. In the paper, we further experimented with more heads and obserded more complex (learned) patterns than a grid of pixels.

Learned Relative Positional Encoding
- Slides: 32