Office Hours My office hours are now officially

















, four different “letters” (bases: A, G, U/T, C)")

 v Leucine (Leu) v Isoleucine (Ile) v Methionine (Met)")
 is also the initiation codon v AUG UAG, UGA are stop")
 that Affect Transcription and Subsequent Translation Nonsense: alteration that results")
 that Affect Transcription and Subsequent Translation Frameshift: insertion or deletion")










 of the point where")
 sequences that 1. Appear in different genes of the")





 is the “raw” RNA transcribed off DNA. This")

 compared to exons (200 -300 NT)")


 attached to 5’")

- Slides: 52
Office Hours My office hours are now officially Tuesday and Thursday, 9: 30 -10: 45 AM, Shantz 225 You can request an appointment outside of office hours Chad’s office hours are Tuesday and Thursday, 3: 304: 30 PM, Shantz 213
Rules about Falling Asleep v You pay for this class, so you can sleep through it if you want. v If you decide to sleep in class, I can decide to wake you up however I want, whenever I want.
Genetics in the News
Bold New World for Bald Mice By Kristen Philipkoski http: //www. wired. com/news/medtech/0, 1286, 64833, 00. html? tw=wn_7 techhead
Hairless mice of the world, rejoice. Scientists have found a way to grow new hair follicles on your bald bodies using stem cells. The study could be good news not just for furless mice. The Howard Hughes Medical Institute researchers who performed the study are also hoping the stem cells will grow hair, as well as skin and sebaceous glands, in humans. The study, which was published in the Sept. 3 issue of Cell, showed that stem cells taken from the hair follicles of mice could self-renew in a dish, and when grafted onto mice could grow into new follicles and hair. "We are now looking at whether we can isolate human cells with the same procedure, " said Dr. Cedric Blanpain, a postdoctoral fellow at Rockefeller University who is an author of the paper. "If that is the case, it's promising for humans. "
Besides replacing hair, the discovery could lead to better skin grafts for burn victims, since grafts now can't grow hair or sebaceous glands. The next step is to try implanting human stem cells, taken from hair follicles, into the hairless mice. If the stem cells grow hair and skin like the mouse cells did, then the researchers will try implanting the cells into humans, Blanpain said…… The stem cells used in this study, however, were taken from the skin of mice. Human adult skin, as well as bone marrow, blood, placenta and brain tissue, is also a source of so-called adult stem cells. The same groups that oppose embryonic stem cell research believe adult stem cells should be studied for therapies instead. The goal in both types of stem cell research is to coax the cells into becoming replacements for a damaged liver, spinal cord, pancreas or other organs.
Potency of stem-type cells v Totipotent: can differentiate along all pathways; can become any kind of cell (early embryonic only) v Pluripotent: can differentiate along several different pathways (late embryonic cells and adult stem cells)
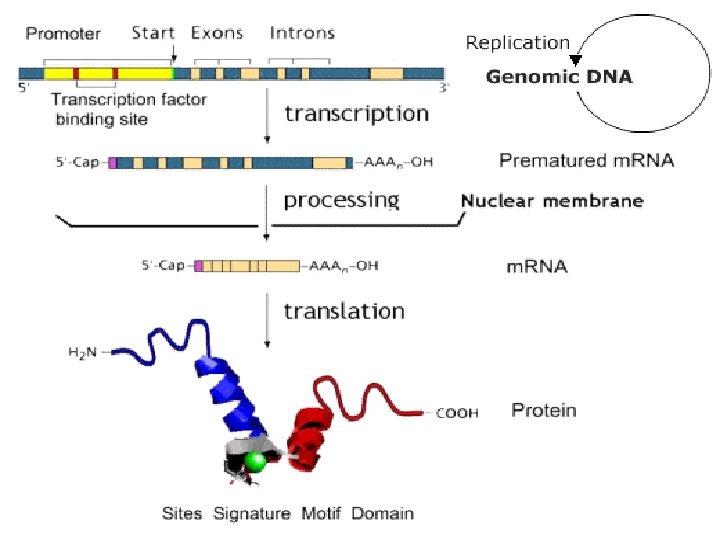
Review v DNA is a double helix of two strands, in opposite orientations v DNA is a polymer of nucleotides v A nucleotide is composed of phosphate group(s), asugar (deoxyribose) and a base (adenine, guanine, thymine and cytosine) v RNA is composed of phosphate group(s), a sugar (ribose) and a base (adenine, guanine, uracil and cytosine
Phosphate Group Nitrogenous Base 5 -Carbon Sugar A Typical Nucleotide
The Central Dogma
DNA RNA PROTEIN
DNA Transcription RNA PROTEIN
DNA Transcription RNA Translation PROTEIN
Information v Information in DNA and RNA is encoded by the nucleotide sequence v The nucleotide sequence confers contextual information (e. g. sequence-specific protein binding controls transcription of DNA) v The nucleotide sequence confers processing information (e. g. specifying splice junctions, 5’cap and 3’ polyadenylation)
Information v The nucleotide sequence specifies amino acid sequence of proteins translated from RNA v Generally, proteins are polymers whose building blocks are 20 amino acids
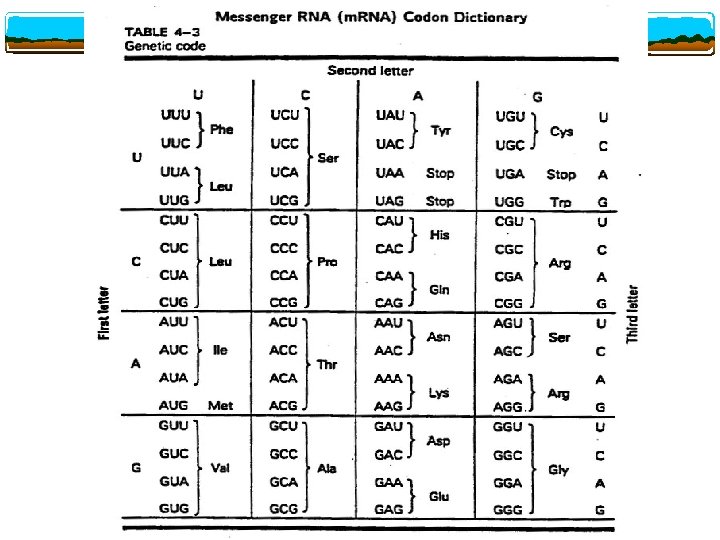
The Genetic Code
The Codon Nucleotides in groups of three specify amino acids
Codon Three letters per “word” (codon), four different “letters” (bases: A, G, U/T, C) 43=64 possible codons More than enough to specify 20 amino acids
The Code is Degenerate v For 18 of the 20 amino acids, there is more than one codon specifying a particular amino acid v The first two nucleotides are the most important; most degeneracy occurs in the third position v The third position is referred to as the “wobble position”
The Amino Acids Phenylalanine (Phe) v Leucine (Leu) v Isoleucine (Ile) v Methionine (Met) v Valine (Val) v Serine (Ser) v Proline (Pro) v Threonine (Thr) v Alanine (Ala) v Tyrosine (Tyr) v Histidine v Glutamine (Gln) v Asparagine (Asn) v Lysine (Lys) v Aspartic Acid (Asp) v Glutamic Acid (Glu) v Cysteine (Cys) v Tryptophan (Trp) v Arginine (Arg) v Gycine (Gly) v
Other Codons (met) is also the initiation codon v AUG UAG, UGA are stop codons v These two types of codons specify the beginning and ending of the DNA sequence that will be transcribed into RNA v UAA,
Alterations in DNA (Mutation) that Affect Transcription and Subsequent Translation Nonsense: alteration that results in a stop codon, which produces a truncated polypeptide AUG UGC ACC CAU Met Cys Thr His AUG UGA ACC CAU Met STOP
Alterations in DNA (Mutation) that Affect Transcription and Subsequent Translation Frameshift: insertion or deletion of one or two nucleotides that shifts the reading frame such that the codons are changed G AUG UGC ACC CAU AUG UGG CAC CCA U Met Cys Thr His Met Trp His Pro
Other Characteristics of the Code v Non-overlapping: After translation begins, a given RNA nucleotide is part of only ONE triplet codon v Unambiguous: A codon specifies ONE item, either a single amino acid or the stop function v Without “punctuation”: Once translation begins, the codons are read continuously without breaks v Universal: The coding dictionary is used by almost all viruses, prokaryotes, archebacteria and eukaryotes
The Triplet Code Again, the four bases possible at each of the three positions in a codon allows for 64 different combinations for codons. The universal designation of those codons demands an examination of philosophy, which can never be divorced from objective science.
Perspectives on Information To be or not to be…. How long would it take a monkey at a typewriter to generate this famous sentence if he randomly selected among the six possible letters, accounting for the relative frequencies of the different letters, and worked continuously?
Hmmm? A few years? A few millenia? In fact, it would take a billion, billion (2 x 1018) years!
Given that the age of the earth is estimated to be only a few billion years, you should now be wondering… What is the origin of our information?
Is it possible to generate information from scratch? Or, can information arise out of chaos?
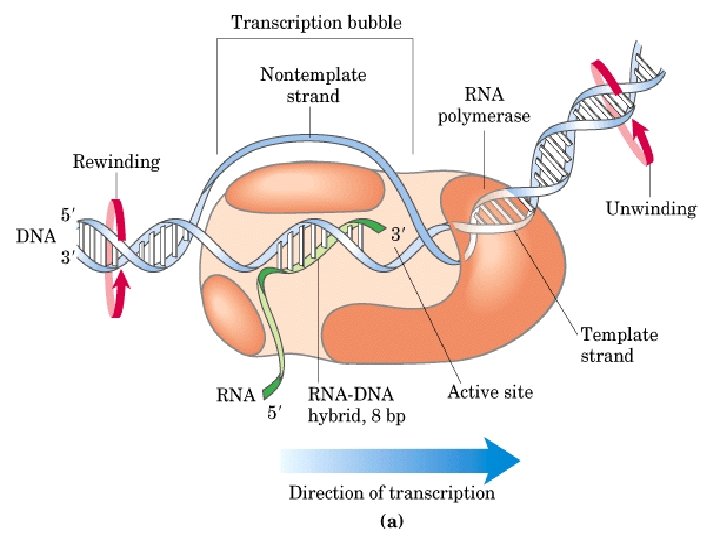
Transcription Occurs in the nucleus (as opposed to translation, which occurs on ribosomes out in the cytoplasm) The enzyme responsible is RNA Polymerase, a multi-subunit protein associated with a complex of other proteins (transcription factors) that direct placement of the polymerase on the DNA molecule.
Transcription: Synthesis of an RNA molecule on a DNA template Sense Antisense Sense
~2, 000 NT 5, 00050, 000 NT
Transcription Initiation: Formation of the transcription complex, consisting of RNA Polymerase and other proteins that drive transcription and determines the transcription start site Elongation: Synthesis of the RNA molecule Termination: Synthesis ends and the RNA molecule is released
Initiation Promoters are specific DNA sequences that are upstream (5’) of the point where transcription of the RNA molecule begins. Promoters determine the efficiency of transcription. Promoters contain a number of sequences that determine where transcription factors bind
Consensus Sequences are similar (homologous) sequences that 1. Appear in different genes of the same organism 2. In one or more genes related organisms Conservation across organisms indicates their critical role in gene expression.
Consensus Sequences A prime example is the TATA box, located 10 -35 bases upstream of the site of transcription inititiation. The TATA box directs the RNA polymerase where to “sit down” in the most basic sense (transcription factors also influence this)
Enhancers Consensus sequences located farther upstream that increase transcription efficiency. May be located a relatively long distance upstream.
Promoter with Proteins Bound
Elongation Chain lengthening as RNA polymerase moves along, reading the DNA template and adding corresponding RNA nucleotides
Termination RNA synthesis terminates when a stop codon is encountered RNA polymerase dissociates along with associated transcription factors
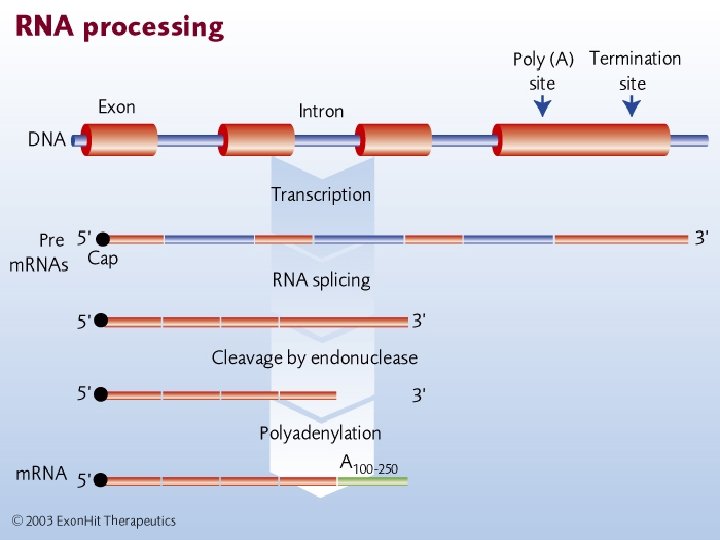
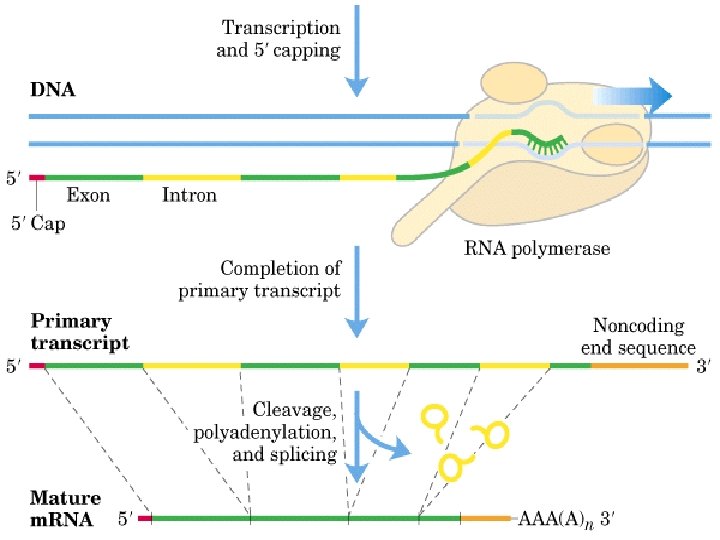
RNA Processing Heteronuclear RNA (hn. RNA) is the “raw” RNA transcribed off DNA. This RNA is processed before leaving the nucleus.
Introns and Exons are spans of RNA that are retained in the final transcript (m. RNA) that exits the nucleus; may encode amino acids. Introns are spans of RNA that are removed from hn. RNA after termination, during processing. hn. RNA Exons
Introns may be very large (20, 000 NT) compared to exons (200 -300 NT) Removal of introns is sequence specific (splice junctions) recognized by processing enzymes
Splicing to remove introns
Splicing
Other processing steps v 5’ cap: 7 -methylguanosine (7 m. G) attached to 5’ end of the transcript, usually during elongation v 3’ poly-A tail: ~200 adenine added to the 3’ end of the transcript Attachment of the poly-A tail is directed by a consensus sequence toward the 3’ end of the transcript
Summary of Transcription