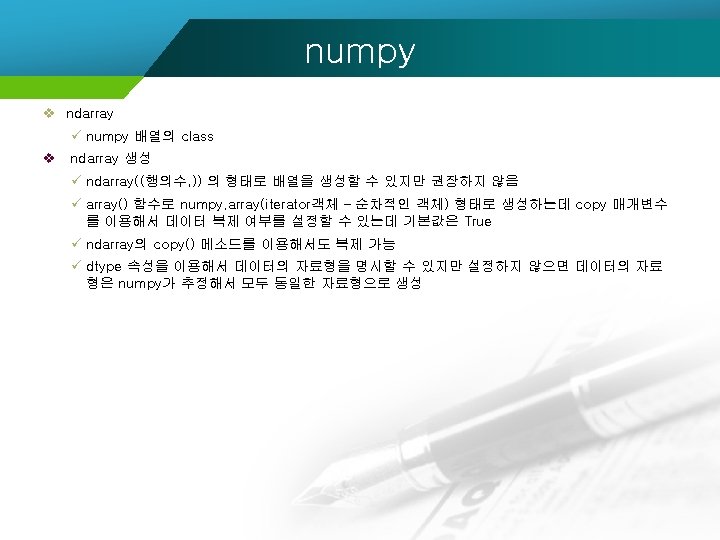
numpy 1 numpy import numpy as np import






 #현재")

![numpy import numpy #list를 이용해서 array 생성 ar = numpy. array([1, 2, 3]) ##생성된](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-10.jpg "numpy import numpy #list를 이용해서 array 생성 ar = numpy. array([1, 2, 3]) ##생성된")
와 유사하게 배열 객체를 만들어주는")
![numpy import numpy # 1차원 배얼 [0, 1, 2, . . . , 9]](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-12.jpg "numpy import numpy # 1차원 배얼 [0, 1, 2, . . . , 9]")

![numpy [1. 1. 1. ] [[0. 0. 0. ] [0. 0. 0. ]] [[1](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-14.jpg "numpy [1. 1. 1. ] [[0. 0. 0. ] [0. 0. 0. ]] [[1")

. reshape((3, 3)) print(ar) print()")

 print(ar) print()")



![numpy import numpy # 1차원 배열 [0, 1, 2, . . . , 9]](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-22.jpg "numpy import numpy # 1차원 배열 [0, 1, 2, . . . , 9]")








![numpy import numpy ar = numpy. array([[1, 2, 3], [4, 5, 6]]) print(ar) print(ar.](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-33.jpg "numpy import numpy ar = numpy. array([[1, 2, 3], [4, 5, 6]]) print(ar) print(ar.")
![numpy import numpy ar = numpy. array([[[1, 2], [3, 4], [5, 6]], [[71, 72],](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-34.jpg "numpy import numpy ar = numpy. array([[[1, 2], [3, 4], [5, 6]], [[71, 72],")

![numpy #벡터화된 연산 import numpy # 행렬을 만듭니다. matrix = numpy. array([[1, 2, 3],](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-36.jpg "numpy #벡터화된 연산 import numpy # 행렬을 만듭니다. matrix = numpy. array([[1, 2, 3],")
![numpy import numpy ar = numpy. array([1, 2, 3]) br = numpy. array([4, 5,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-37.jpg "numpy import numpy ar = numpy. array([1, 2, 3]) br = numpy. array([4, 5,")
![numpy [2 4 6] [5 7 9] [[ 7 9 11] [11 22 33]]](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-38.jpg "numpy [2 4 6] [5 7 9] [[ 7 9 11] [11 22 33]]")

![numpy import numpy ar = numpy. array([1, 2, 3]) br = numpy. array([4, 2,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-40.jpg "numpy import numpy ar = numpy. array([1, 2, 3]) br = numpy. array([4, 2,")
![numpy import numpy ar = numpy. array([1, 0, 3]) br = numpy. array([4, 2,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-41.jpg "numpy import numpy ar = numpy. array([1, 0, 3]) br = numpy. array([4, 2,")
. reshape(5, 4) br = numpy. array(['A', \"B\",")

) #5개의 난수 생성 - 랜덤 print() print(numpy. random.")


![numpy import numpy #print(help(numpy. sum)) ar = numpy. array([[1, 2, 4, 5, 5], [7,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-48.jpg "numpy import numpy #print(help(numpy. sum)) ar = numpy. array([[1, 2, 4, 5, 5], [7,")
![numpy import numpy # 행렬을 만듭니다. matrix = numpy. array([[1, 2, 3], [4, 5,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-49.jpg "numpy import numpy # 행렬을 만듭니다. matrix = numpy. array([[1, 2, 3], [4, 5,")

![numpy import numpy b = numpy. array([1, 2, 3, 4]) c = numpy. array([[1,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-51.jpg "numpy import numpy b = numpy. array([1, 2, 3, 4]) c = numpy. array([[1,")
![numpy import numpy b = numpy. array([1, 2, 3, 4]) c = numpy. array([[1,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-52.jpg "numpy import numpy b = numpy. array([1, 2, 3, 4]) c = numpy. array([[1,")
![numpy import numpy g = numpy. array([1, 2, 4, 10, 13, 20]) print(numpy. diff(g))](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-53.jpg "numpy import numpy g = numpy. array([1, 2, 4, 10, 13, 20]) print(numpy. diff(g))")


![numpy import numpy ar = numpy. array([10, 1, 2, 3, 4, numpy. nan]) print(numpy.](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-57.jpg "numpy import numpy ar = numpy. array([10, 1, 2, 3, 4, numpy. nan]) print(numpy.")

![numpy import numpy ar = numpy. array([1, 2, 3, 4]) br = numpy. array([5,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-59.jpg "numpy import numpy ar = numpy. array([1, 2, 3, 4]) br = numpy. array([5,")

![numpy import numpy ar = [1, 2, 3, 4] br = [5, 6, 7,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-61.jpg "numpy import numpy ar = [1, 2, 3, 4] br = [5, 6, 7,")

![numpy import numpy ar = numpy. array([90, 40, 30, 78, 30]) #중복 제거 print("중복제거:](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-63.jpg "numpy import numpy ar = numpy. array([90, 40, 30, 78, 30]) #중복 제거 print(\"중복제거:")

![numpy import numpy ar = numpy. array([[1, 2, 3, 4], [5, 6, 7, 8],](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-65.jpg "numpy import numpy ar = numpy. array([[1, 2, 3, 4], [5, 6, 7, 8],")
![numpy import numpy ar = numpy. array([90, 40, 30, 78]) ar. sort() print(ar) br](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-66.jpg "numpy import numpy ar = numpy. array([90, 40, 30, 78]) ar. sort() print(ar) br")
![numpy import numpy ar = numpy. array([90, 40, 30, 78]) ar. sort() print(ar[0: int(0.](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-67.jpg "numpy import numpy ar = numpy. array([90, 40, 30, 78]) ar. sort() print(ar[0: int(0.")


![numpy import numpy matrix = np. array([[1, 2, 3], [2, 4, 6], [3, 8,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-70.jpg "numpy import numpy matrix = np. array([[1, 2, 3], [2, 4, 6], [3, 8,")

![numpy import numpy x = numpy. array([[1, 2, 3], [4, 5, 6]]) y =](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-72.jpg "numpy import numpy x = numpy. array([[1, 2, 3], [4, 5, 6]]) y =")

![numpy import numpy mat = numpy. array([[1, 2], [3, 4]]) #역행렬 print(numpy. linalg. inv(mat))](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-74.jpg "numpy import numpy mat = numpy. array([[1, 2], [3, 4]]) #역행렬 print(numpy. linalg. inv(mat))")

![numpy #행렬식 import numpy mat = numpy. array([[1, 2], [3, 4]]) print(numpy. linalg. det(mat))](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-76.jpg "numpy #행렬식 import numpy mat = numpy. array([[1, 2], [3, 4]]) print(numpy. linalg. det(mat))")
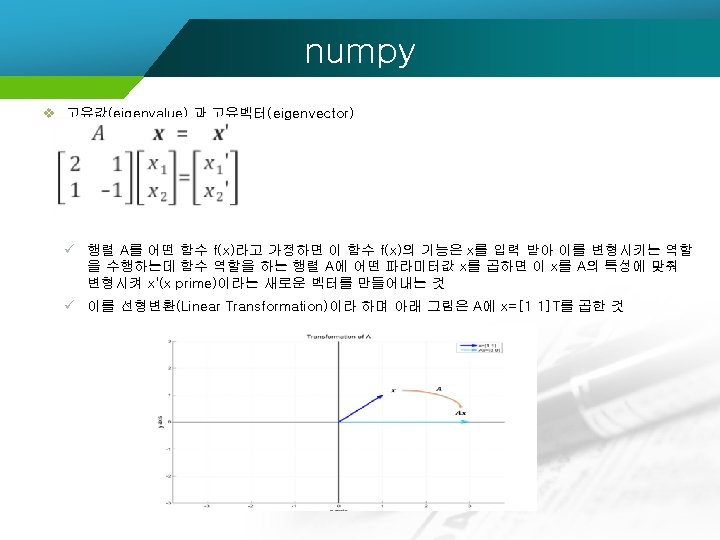
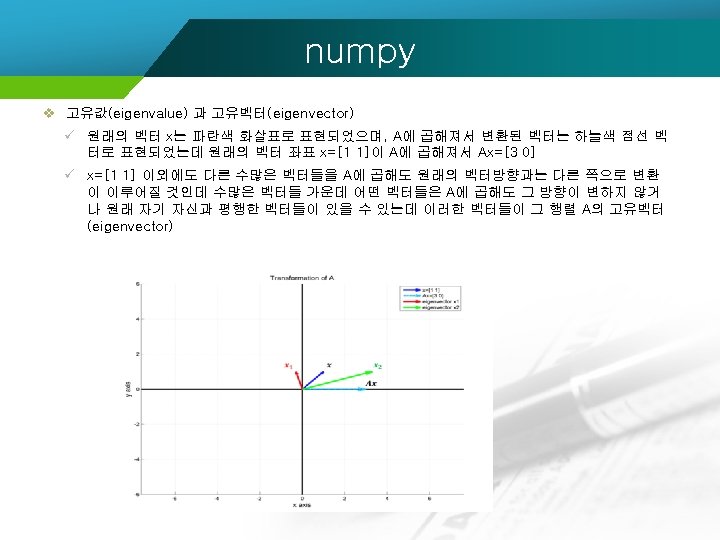


 과 고유벡터(eigen vector) ü 그래프로 표현")


![numpy v 고유값(eigenvalue) 과 고유벡터(eigenvector) #고유값과 고유벡터 구하기 B = numpy. array([[2, 1], [1,](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-87.jpg "numpy v 고유값(eigenvalue) 과 고유벡터(eigenvector) #고유값과 고유벡터 구하기 B = numpy. array([[2, 1], [1,")
 과 고유벡터(eigenvector) #행렬의 랭크 #모든 열의 데이터가 다르므로 rank는 3 ar")



) c 2 = c")

![numpy print(numpy. stack([c 2, d 2])) [[[ 1 2 3 4] [ 5 6](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-95.jpg "numpy print(numpy. stack([c 2, d 2])) [[[ 1 2 3 4] [ 5 6")
![numpy print(numpy. stack([c 2, d 2], axis=1)) [[[ 1 2 3 4] [101 102](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-96.jpg "numpy print(numpy. stack([c 2, d 2], axis=1)) [[[ 1 2 3 4] [101 102")

![numpy v tile 명령은 동일한 배열을 반복하여 연결 a = numpy. array([[0, 1, 2],](https://slidetodoc.com/presentation_image_h2/ba4b98640fa547e87e3e934548c20742/image-99.jpg "numpy v tile 명령은 동일한 배열을 반복하여 연결 a = numpy. array([[0, 1, 2],")
- Slides: 100
numpy 1
numpy import numpy as np import datetime #list 생성 li = range(1, 1000000) #현재 시간 저장 및 출력 s = datetime. now() print("리스트 작업 시작 시간: ", s) #li의 각 요소에 10을 곱하기 for i in li: i = i * 10 s = datetime. now() print("리스트 작업 종료 시간: ", s) #ndarray 생성 ar = np. arange(1, 1000000) s = datetime. now() print("ndarray 작업 시작 시간: ", s) ar = ar * 10 s = datetime. now() print("ndarray 작업 종료 시간: ", s) 리스트 작업 시작 시간: 2017 -04 -12 07: 53: 34. 114300 리스트 작업 종료 시간: 2017 -04 -12 07: 53: 34. 116300 ndarray 작업 시작 시간: 2017 -04 -12 07: 53: 34. 116300 ndarray 작업 종료 시간: 2017 -04 -12 07: 53: 34. 116300
numpy import numpy #list를 이용해서 array 생성 ar = numpy. array([1, 2, 3]) ##생성된 데이터의 자료형 확인 print(type(ar)) #차원 확인 - 1차원 3개의 데이터로 구성 print (ar. shape) #2차원 배열 만들기 br = numpy. array([[1, 2, 3], [4, 5, 6]]) #배열 출력 print(br) #배열의 차원 확인 print (br. shape) #배열의 메모리 크기 확인 print(br. nbytes) <class 'numpy. ndarray'> (3, ) [[1 2 3] [4 5 6]] (2, 3) 48
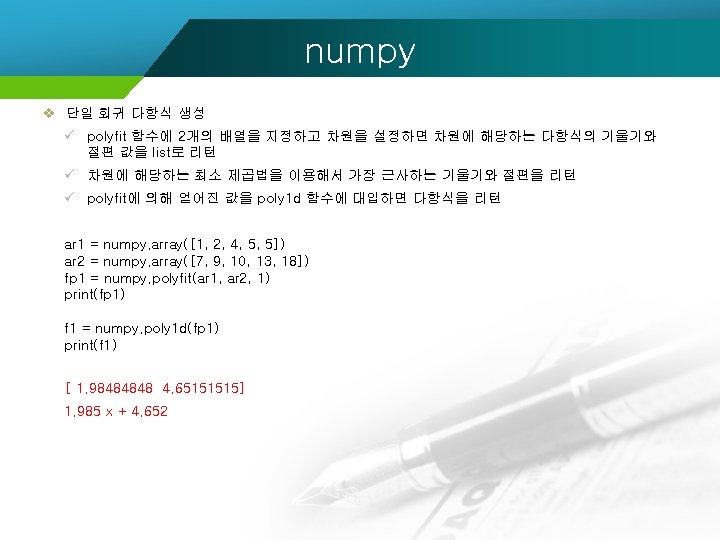
numpy v ndarray 의 생성 ü 파이썬의 내장 함수인 range()와 유사하게 배열 객체를 만들어주는 함수는 arange() numpy. arange([start, ]stop, [step, ]dtype=None) ü 시작점과 끝점을 균일 간격으로 나눈 값들을 이용해서 생성해주는 linspace() numpy. linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
numpy import numpy # 1차원 배얼 [0, 1, 2, . . . , 9] 생성 ar = numpy. arange(10) print(ar) print() # start, end, num-points ar = numpy. linspace(0, 1, 6) print(ar) print() # start, end, num-points, 마지막 포인트는 제외 ar = numpy. linspace(0, 1, 5, endpoint=False) print(ar) print() [0 1 2 3 4 5 6 7 8 9] [0. 0. 2 0. 4 0. 6 0. 8 1. ] [0. 0. 2 0. 4 0. 6 0. 8]
numpy [1. 1. 1. ] [[0. 0. 0. ] [0. 0. 0. ]] [[1 0] [0 1]] [[0. 1. 0. ] [0. 0. 1. ] [0. 0. 0. ]] [[0. 1. 0. 0. ] [0. 0. 1. 0. ] [0. 0. 0. 1. ]] [[0 1 2] [3 4 5] [6 7 8]] [0 4 8] [1 5] [3 7] [[5. e-324 0. e+000] [0. e+000 5. e-324]]
numpy #9개짜리 일차원 배열을 3*3행렬로 변환 ar = numpy. arange(9). reshape((3, 3)) print(ar) print() br = numpy. diag(ar) print(br) print() #중앙의 대각선에서 위나 아래 한칸 이동해서 데이터를 가져와서 벡터를 생성 cr = numpy. diag(ar, k=1) print(cr) print() dr = numpy. diag(ar, k=-1) print(dr) print() er = numpy. empty( (2, 2) ) # 가비지 값으로 채원진 2 x 2 크기의 배열 생성 print(er)
numpy import numpy from scipy import sparse ar = numpy. eye(3, k=1) print(ar) print() # CSR 행렬을 만듭니다. sp = sparse. csr_matrix(ar) print(sp) print() #원래의 ndarray로 변환 br = sp. toarray() print(br) [[0. 1. 0. ] [0. 0. 1. ] [0. 0. 0. ]] (0, 1) 1. 0 (1, 2) 1. 0 [[0. 1. 0. ] [0. 0. 1. ] [0. 0. 0. ]]
numpy import numpy # 1차원 배열 [0, 1, 2, . . . , 9] 생성 ar = numpy. arange(10) print(ar) print() [0 1 2 3 4 5 6 7 8 9] # 같은 요소를 가지고 2 x 5 배열로 변형 ar = ar. reshape(2, 5) print(ar) print() [0 1 2 3 4 5 6 7 8 9] [0. 0. 2 0. 4 0. 6 0. 8 1. ] [0. 0. 2 0. 4 0. 6 0. 8] [[0 1 2 3 4] [5 6 7 8 9]]
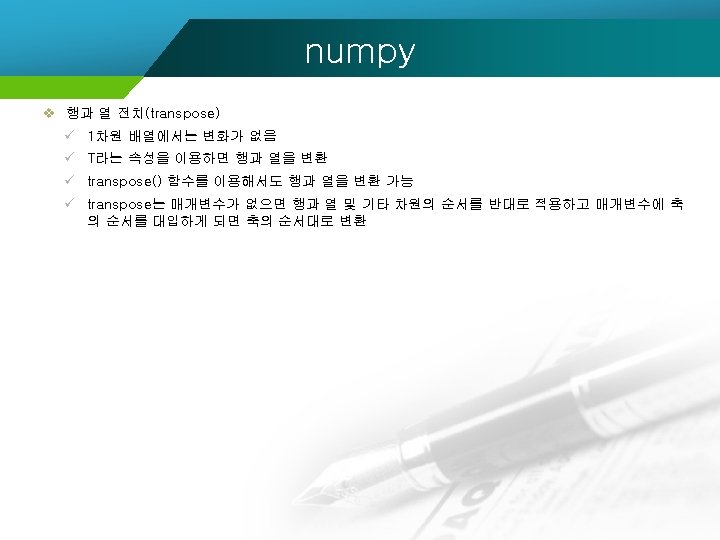
numpy import numpy ar = numpy. array([[1, 2, 3], [4, 5, 6]]) print(ar) print(ar. T) [[1 2 3] [4 5 6]] [[1 4] [2 5] [3 6]]
numpy import numpy ar = numpy. array([[[1, 2], [3, 4], [5, 6]], [[71, 72], [73, 74], [75, 76]]]) print(ar. transpose()) print(ar. transpose(2, 1, 0)) print(ar. transpose(1, 0, 2)) [[[ 1 71] [ 3 73] [ 5 75]] [[ 2 72] [ 4 74] [ 6 76]]] [[[ 1 2] [71 72]] [[ 3 4] [73 74]] [[ 5 6] [75 76]]]
numpy #벡터화된 연산 import numpy # 행렬을 만듭니다. matrix = numpy. array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 100을 더하는 함수를 생성 add_100 = lambda i: i + 100 # 벡터화된 함수를 만듭니다. vectorized_add_100 = numpy. vectorize(add_100) # 행렬의 모든 원소에 함수를 적용합니다. vectorized_add_100(matrix) array([[101, 102, 103], [104, 105, 106], [107, 108, 109]])
numpy import numpy ar = numpy. array([1, 2, 3]) br = numpy. array([4, 5, 6]) cr = numpy. array([[6, 7, 8], [10, 20, 30]]) result = ar * 2 #배열의 모든 요소에 2를 곱한 결과 print(result) print() result = ar + br; #배열 간의 덧셈: 동일한 위치간의 덧셈을 한 결과 print(result) print() result = ar + cr #작은 차원인 ar 의 모든 데이터를 cr에 덧셈 print(result) print() dr = numpy. array([1, 2]) result = ar + dr #차원은 1차원으로 같은데 데이터 개수가 달라서 에러
numpy [2 4 6] [5 7 9] [[ 7 9 11] [11 22 33]] -------------------------------------Value. Error Traceback (most recent call last) <ipython-input-15 -f 26 f 7731 a 145> in <module> 11 12 dr = numpy. array([1, 2]) ---> 13 result = ar + dr #차원은 1차원으로 같은데 데이터 개수가 달라서 에러 Value. Error: operands could not be broadcast together with shapes (3, ) (2, )
numpy import numpy ar = numpy. array([1, 2, 3]) br = numpy. array([4, 2, 6]) #각 요소가 같은지 비교 print(numpy. equal(ar, br)) print(ar == br) print() #각 요소가 다른지 비교 print(numpy. not_equal(ar, br)) print(ar != br) print() #ar의 요소가 큰지 확인 print(numpy. greater(ar, br)) print(numpy. greater_equal(ar, br)) print() #ar의 요소가 작은지 확인 print(numpy. less(ar, br)) print(numpy. less_equal(ar, br)) [False True False] [ True False True] [False] [False True False] [ True False True] [ True]
numpy import numpy ar = numpy. array([1, 0, 3]) br = numpy. array([4, 2, 3]) [ True False True] [ True] [False True False] #논리 연산 print(numpy. logical_and(ar, br)) print(numpy. logical_or(ar, br)) print(numpy. logical_xor(ar, br)) print() True False #데이터의 소속 여부 확인 print(1 in ar) print(2 in ar)
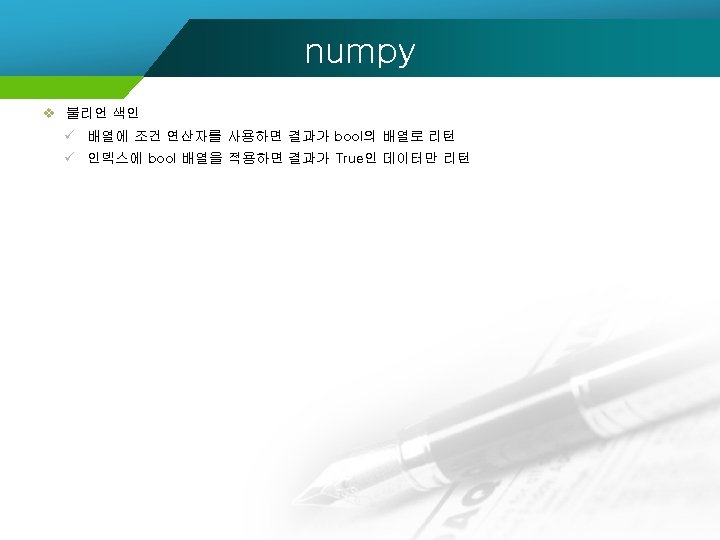
numpy import numpy ar = numpy. arange(20). reshape(5, 4) br = numpy. array(['A', "B", 'C', 'A', 'C']) print(br == 'A') #데이터가 A인 경우는 True 그렇지 않으면 False print(ar[br == 'A']) #True 인 행만 반환 print(ar[br == 'A', 2]) #열을 2번째만 반환 [ True False] print(ar[br == 'A', 0: 2]) #열을 0부터 2앞까지 반환 [[ 0 1 2 3] ar[br == 'A'] = 100 [12 13 14 15]] print(ar) [ 2 14] [[ 0 1] [12 13]] [[100 100 100] [ 4 5 6 7] [ 8 9 10 11] [100 100 100] [ 16 17 18 19]]
numpy import numpy print(numpy. random. normal(size=5)) #5개의 난수 생성 - 랜덤 print() print(numpy. random. normal(size=(2, 3))) #2행 3열의 난수 생성 print() numpy. random. seed(seed=100) #시드 설정 print(numpy. random. normal(size=5)) #5개의 난수 생성 - 실행할 때마다 동일한 값 [-0. 24961316 -0. 48887513 -0. 36998486 0. 74862078 -0. 27312433] [[ 1. 40273795 0. 84421724 -0. 13975186] [ 0. 00408551 0. 90391068 -0. 88485027]] [-1. 74976547 0. 3426804 1. 1530358 -0. 25243604 0. 98132079]
numpy import numpy ar = numpy. array([1, 2, 4, 5, 5, 7, 9, 10, 13, 18, 21]) print('배열의 합계: ', numpy. sum(ar)) print('배열의 평균: ', numpy. mean(ar)) print('배열의 중간값: ', numpy. median(ar)) print('배열의 표준편차: ', numpy. std(ar)) print('배열의 분산: ', numpy. var(ar)) print('배열에서 3/4에 해당하는 값: ', numpy. percentile(ar, 75)) 배열의 합계: 95 배열의 평균: 8. 6363636 배열의 중간값: 7. 0 배열의 표준편차: 6. 1388883695 배열의 분산: 37. 6859504132 배열에서 3/4에 해당하는 값: 11. 5
numpy import numpy #print(help(numpy. sum)) ar = numpy. array([[1, 2, 4, 5, 5], [7, 9, 10, 13, 18]]) #배열 전체의 합계 print(numpy. sum(ar)) print('========') #열 단위의 합계 print(numpy. sum(ar, axis=0)) 74 print('========') ======== #행 단위의 합계 [ 8 11 14 18 23] print(numpy. sum(ar, axis=1)) ======== [17 57]
numpy import numpy # 행렬을 만듭니다. matrix = numpy. array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 각 행에서 최댓값 print(numpy. max(matrix, axis=1)) print() [3 6 9] #결과가 동일한 차원의 배열 print(numpy. max(matrix, axis=1, keepdims=True)) [[3] [6] [9]]
numpy import numpy b = numpy. array([1, 2, 3, 4]) c = numpy. array([[1, 2], [3, 4]]) print(numpy. prod(b)) # 1*2*3*4 print(numpy. prod(c, axis=0)) # [1*3, 2*4] print(numpy. prod(c, axis=1)) # [1*2, 3*4] print(numpy. sum(b)) # [1+2+3+4] print(numpy. sum(b, keepdims=True)) print(numpy. sum(c, axis=0)) # [1+3, 2+4] print(numpy. sum(c, axis=1) ) # [1+2, 3+4] 24 [3 8] [ 2 12] 10 [10] [4 6] [3 7]
numpy import numpy b = numpy. array([1, 2, 3, 4]) c = numpy. array([[1, 2], [3, 4]]) print(numpy. cumprod(b))# [1, 1*2*3, 1*2*3*4] print(numpy. cumprod(c, axis=0)) # [[1, 2], [1*3, 2*4]] print(numpy. cumprod(c, axis=1)) # [[1, 1*2], [3, 3*4]] print(numpy. cumsum(b))# [1, 1+2+3, 1+2+3+4] print(numpy. cumsum(c, axis=0)) # [[1, 2], [1+3, 2+4]] print(numpy. cumsum(c, axis=1)) # [[1, 1+2], [3, 3+4]] [ 1 2 6 24] [[1 2] [3 8]] [[ 1 2] [ 3 12]] [ 1 3 6 10] [[1 2] [4 6]] [[1 3] [3 7]]
numpy import numpy g = numpy. array([1, 2, 4, 10, 13, 20]) print(numpy. diff(g)) # [2 -1, 4 -2, 10 -4, 13 -10, 20 -13] print(numpy. diff(g, n=2)) # [2 -1, 6 -2, 3 -6, 7 -3] [1 2 6 3 7] [ 1 4 -3 4]
numpy import numpy ar = numpy. array([-4. 62, -2. 19, 0, 1. 57, 3. 40, 4. 06]) print(numpy. around(ar)) print(numpy. round_(ar, 1)) print(numpy. rint(ar)) print(numpy. fix(ar)) print(numpy. ceil(ar)) print(numpy. floor(ar)) print(numpy. trunc(ar)) [-5. -2. 0. 2. [-4. 6 -2. 2 0. [-5. -2. 0. 2. [-4. -2. 0. 1. [-4. -2. 0. 2. [-5. -3. 0. 1. [-4. -2. 0. 1. 3. 4. ] 1. 6 3. 4 4. 1] 3. 4. ] 4. 5. ] 3. 4. ]
numpy import numpy ar = numpy. array([10, 1, 2, 3, 4, numpy. nan]) print(numpy. isnan(ar)) #isnan을 이용해서 nan 데이터가 있는지 확인 br = ar[numpy. logical_not(numpy. isnan(ar))] #nan 데이터를 제외하고 가져오기 print(br) print(numpy. logical_not( br <= 2 )) #2보다 큰 데이터가 있는지 확인 cr = br[numpy. logical_not( br <= 2 )] #2보다 큰 데이터 추출 print(cr) [False False True] [10. 1. 2. 3. 4. ] [ True False True] [10. 3. 4. ]
numpy import numpy ar = numpy. array([1, 2, 3, 4]) br = numpy. array([5, 6, 7, 8]) print(ar + br) print(numpy. add(ar, br)) cond = [True, False, True] print(numpy. where(cond, ar, br)) [ 6 8 10 12] [1 6 7 4]
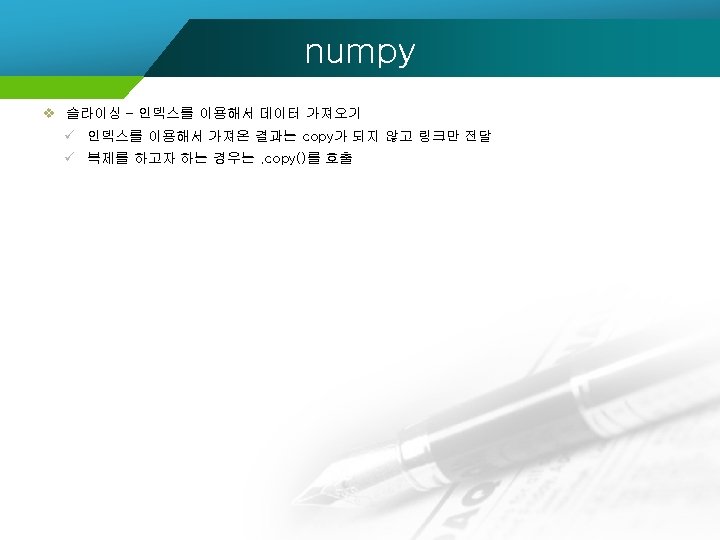
numpy import numpy ar = [1, 2, 3, 4] br = [5, 6, 7, 8] cr = numpy. concatenate((ar, br)) print(cr) ar = numpy. array([[1, 2], [3, 4]]) br = numpy. array([[5, 6], [7, 8]]) cr = numpy. concatenate((ar, br), axis = 0) print(cr) cr = numpy. concatenate((ar, br), axis = 1) print(cr) [1 2 3 4 5 6 7 8] [[1 2] [3 4] [5 6] [7 8]] [[1 2 5 6] [3 4 7 8]]
numpy import numpy ar = numpy. array([90, 40, 30, 78, 30]) #중복 제거 print("중복제거: ", numpy. unique(ar)) br = numpy. array([30, 45, 76, 90]) #교집합 print('교집합: ', numpy. intersect 1 d(ar, br)) #합집합 print('합집합: ', numpy. union 1 d(ar, br)) #소속여부 print('소속여부: ', numpy. in 1 d(ar, br)) #차집합 print('차집합', numpy. setdiff 1 d(ar, br)) #한쪽에만 속한 데이터 print(numpy. setxor 1 d(ar, br)) 중복제거: [30 40 78 90] 교집합: [30 90] 합집합: [30 40 45 76 78 90] 소속여부: [ True False True] 차집합 [40 78] [40 45 76 78]
numpy import numpy ar = numpy. array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13 , 14 , 15, 16]]) print(ar) [[ 1 2 3 4] print() [ 5 6 7 8] split. Y = numpy. split(ar, 2, axis = 0) [ 9 10 11 12] #x축 방향으로 2개로 나눔 [13 14 15 16]] print(split. Y[0]) print(split. Y[1]) [[1 2 3 4] print() [5 6 7 8]] split. X = numpy. split(ar, [2, 3], axis = 1) [[ 9 10 11 12] #2번째 앞까지 나누고 3번째 앞까지 나누고 나머지 [13 14 15 16]] print(split. X[0]) print(split. X[1]) [[ 1 2] print(split. X[2]) [ 5 6] [ 9 10] [13 14]] [[ 3] [ 7] [11] [15]] [[ 4] [ 8] [12] [16]]
numpy import numpy ar = numpy. array([90, 40, 30, 78]) ar. sort() print(ar) br = numpy. sort(ar) print(br) ar = numpy. array([[90, 40, 50], [30, 78, 27]]) ar. sort(axis=0) print(ar) [30 40 78 90] [[30 40 27] [90 78 50]]
numpy import numpy ar = numpy. array([90, 40, 30, 78]) ar. sort() print(ar[0: int(0. 5 * len(ar))]) #하위 50% print(ar[int(0. 5 * len(ar))*-1: ]) #상위 50% [30 40] [78 90]
numpy import numpy matrix = np. array([[1, 2, 3], [2, 4, 6], [3, 8, 9]]) # 대각 원소를 반환 print(matrix. diagonal()) print(matrix. diagonal(offset = -1)) print() [1 4 9] [2 8]
numpy import numpy x = numpy. array([[1, 2, 3], [4, 5, 6]]) y = numpy. array([[1, 2], [3, 4], [5, 6]]) #행렬의 곱 mat = numpy. dot(x, y) #1*1 + 2*3 + 3*5 #1*2 + 2*4 + 3*6 #4*1+5*3+6*5 #4*2+5*4+6*6 print(mat) mat = x @ y print(mat) [[22 28] [49 64]]
numpy import numpy mat = numpy. array([[1, 2], [3, 4]]) #역행렬 print(numpy. linalg. inv(mat)) #행렬과 역행렬의 곱 print(numpy. dot(mat, numpy. linalg. inv(mat) )) [[-2. 1. ] [ 1. 5 -0. 5]] [[1. 0000 e+00 1. 11022302 e-16] [0. 0000 e+00 1. 0000 e+00]]
numpy #행렬식 import numpy mat = numpy. array([[1, 2], [3, 4]]) print(numpy. linalg. det(mat)) mat = numpy. array([[1, 1, 1], [4, 1, 6], [7, 8, 1]]) print(numpy. linalg. det(mat)) -2. 000000004 15. 99999998
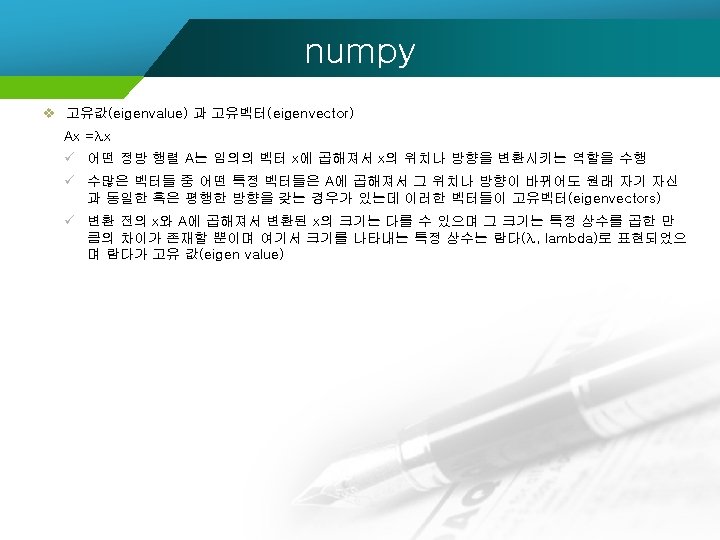
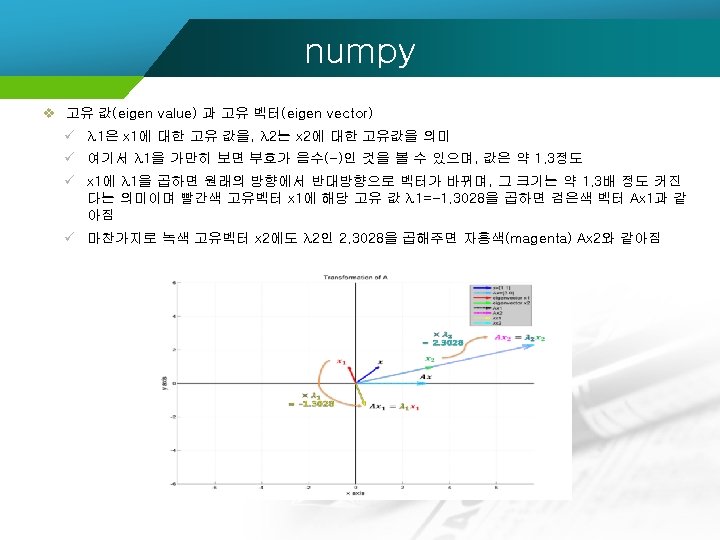
numpy v 고유 값(eigen value) 과 고유벡터(eigen vector) ü 그래프로 표현
numpy v 고유값(eigenvalue) 과 고유벡터(eigenvector) #고유값과 고유벡터 구하기 B = numpy. array([[2, 1], [1, -1]]) w 2, V 2 = numpy. linalg. eig(B) print(w 2) print(V 2) [ 2. 30277564 -1. 30277564] [[ 0. 95709203 -0. 28978415] [ 0. 28978415 0. 95709203]]
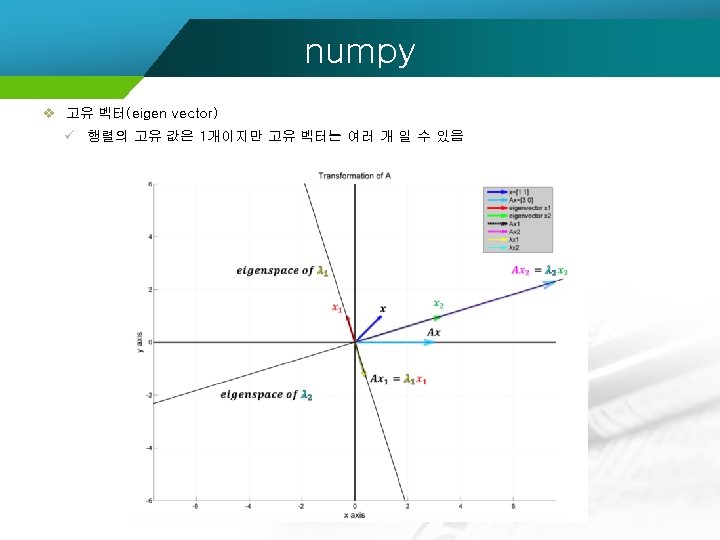
numpy v 고유값(eigenvalue) 과 고유벡터(eigenvector) #행렬의 랭크 #모든 열의 데이터가 다르므로 rank는 3 ar = numpy. array([[2, 1, 1], [1, -1, 2], [1, -1, 3]]) print(numpy. linalg. matrix_rank(ar)) #두번째 열과 세번째 열이 동일하므로 rank는 2 br = numpy. array([[2, 1, 1], [1, -1, 2]]) print(numpy. linalg. matrix_rank(br)) 3 2
numpy v hstack: 행의 수가 같은 두 개 이상의 배열을 옆으로 연결하여 열의 수가 더 많은 배열을 생성 import numpy a 1 = numpy. ones((2, 3)) print(a 1) print() [[1. 1. 1. ]] a 2 = numpy. zeros((2, 2)) print(a 2) print() [[0. 0. ]] print(numpy. hstack([a 1, a 2])) [[1. 1. 1. 0. 0. ]]
numpy v vstack: 열의 수가 같은 두 개 이상의 배열을 위아래로 연결하여 행의 수가 더 많은 배열 생성 import numpy a 1 = numpy. ones((2, 2)) print(a 1) print() a 2 = numpy. zeros((2, 2)) print(a 2) print(numpy. vstack([a 1, a 2])) [[1. 1. ]] [[0. 0. ]] [[1. 1. ] [0. 0. ]]
numpy import numpy c 1 = numpy. array(range(1, 13, 1)) c 2 = c 1. reshape(3, 4) print(c 2) print() d 1 = numpy. array(range(101, 113, 1)) d 2 = d 1. reshape(3, 4) print(d 2) print(numpy. dstack([c 2, d 2])) [[ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12]] [[101 102 103 104] [105 106 107 108] [109 110 111 112]] [[[ [ 1 101] 2 102] 3 103] 4 104]] [[ [ 5 105] 6 106] 7 107] 8 108]] [[ 9 109] [ 10 110] [ 11 111] [ 12 112]]]
numpy print(numpy. stack([c 2, d 2])) [[[ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12]] [[101 102 103 104] [105 106 107 108] [109 110 111 112]]]
numpy print(numpy. stack([c 2, d 2], axis=1)) [[[ 1 2 3 4] [101 102 103 104]] [[ 5 6 7 8] [105 106 107 108]] [[ 9 10 11 12] [109 110 111 112]]]
numpy v tile 명령은 동일한 배열을 반복하여 연결 a = numpy. array([[0, 1, 2], [3, 4, 5]]) print(numpy. tile(a, 2)) print(numpy. tile(a, (3, 2))) array([[0, 1, 2, 0, 1, 2], [3, 4, 5, 3, 4, 5]]) array([[0, 1, 2, 0, 1, 2], [3, 4, 5, 3, 4, 5], [0, 1, 2, 0, 1, 2], [3, 4, 5, 3, 4, 5]])