No SQL ACID Semantics Atomicity All or nothing












 Stores • Access data (values) by strings called keys. • Data")











, oid, array, null, date. •")


 Based on Google’s Big. Table store. What is a")

. Tradeoffs between")



 – Closer to OOP (Object")










- Slides: 45
No. SQL
ACID Semantics • • Atomicity: All or nothing. Consistency: Consistent state of data and transactions. Isolation: Transactions are isolated from each other. Durability: When the transaction is committed, state will be durable. Any data store can achieve Atomicity, Isolation and Durability but do you always need consistency? No. By giving up ACID properties, one can achieve higher performance and scalability.
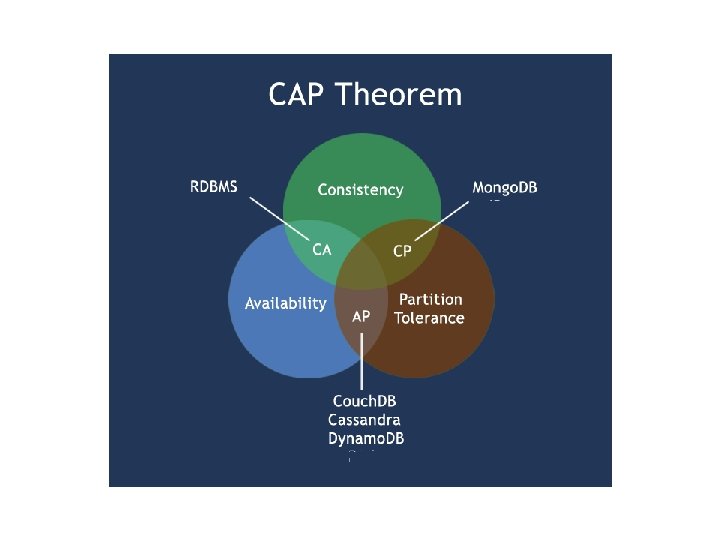
Enter CAP Theorem • Also known as Brewer’s Theorem by Prof. Eric Brewer, published in 2000 at University of Berkeley. • “Of three properties of a shared data system: data consistency, system availability and tolerance to network partitions, only two can be achieved at any given moment. ” • Proven by Nancy Lynch et al. MIT labs. • http: //www. cs. berkeley. edu/~brewer/cs 262 b-2004/PODC-keynote. pdf
CAP Semantics • Consistency: Clients should read the same data. There are many levels of consistency. – Strict Consistency – RDBMS. – Tunable Consistency – Cassandra. – Eventual Consistency – Amazon Dynamo. • Availability: Data to be available. • Partial Tolerance: Data to be partitioned across network segments due to network failures.
A Simple Proof Consistent and available No partition. App Data A Data B
A Simple Proof Available and partitioned Not consistent, we get back old data. App Data A Old Data B
A Simple Proof Consistent and partitioned Not available, waiting… App New Data Wait for new data A B
BASE, an ACID Alternative Almost the opposite of ACID. • Basically available: Nodes in the a distributed environment can go down, but the whole system shouldn’t be affected. • Soft State (scalable): The state of the system and data changes over time. • Eventual Consistency: Given enough time, data will be consistent across the distributed system.
A Clash of cultures ACID: • Strong consistency. • Less availability. • Pessimistic concurrency. • Complex. BASE: • Availability is the most important thing. Willing to sacrifice for this (CAP). • Weaker consistency (Eventual). • Best effort. • Simple and fast. • Optimistic.
CAP Again! Very large systems will partition at some point - failures - It is necessary to decide between C and A - Most web-based DB applications choose A Strict consistency cannot be achieved at the same time as availability on partitioned data ACID must be relaxed!
Different Types of No. SQL Systems • Distributed Key-Value Systems - Lookup a single value for a key – Amazon’s Dynamo • Document-based Systems - Access data by key or by search of “document” data. – Couch. DB – Mongo. DB • Column-based Systems – Google’s Big. Table – Facebook’s Cassandra • Graph-based Systems - Use a graph structure - Google’s Pregel - Neo 4 j Use different types for different types of applications
Complexity
Key-Value Pair (KVP) Stores • Access data (values) by strings called keys. • Data has no required format – data may have any format Extremely simple interface § Data model: (key, value) pairs § Basic Operations: Insert(key, value), Fetch(key), Update(key), Delete(key) Implementation: efficiency, scalability, fault-tolerance § Records distributed to nodes based on key § Replication § Single-record transactions, “eventual consistency” Example systems § Amazon Dynamo, …
“Value” is stored as a “blob” - Without caring or knowing what is inside - Application is responsible for understanding the data In simple terms, a No. SQL Key-Value store is a single table with two columns: one being the (Primary) Key, and the other being the Value. Each record may have a different schema
Example
Original Key-Value Store was Dynamo - Amazon’s Highly-Available Key-Value Store • Main observation from Amazon: – “There are many services on Amazon’s platform that only need primary-key access to a data store. ” E. g. Best seller lists, shopping carts, customer preferences, session management, sales rank, product catalog Aside: Dynamo now superseded by Dynamo. DB. http: //www. allthingsdistributed. com/files/amazon-dynamo-sosp 2007. pdf
Dynamo applies a MD 5 hash on the key to generate a 128 -bit identifier, which is then used to determine the storage node that is responsible for serving the key. - Data records are randomly assigned to storage nodes. - This allows the data store to scale incrementally dynamically partition the data over the set of nodes (i. e. , storage hosts) in the system. The simplicity of Key-Value Stores makes them ideally suited to extremely fast, highly-scalable retrieval of the values needed for application tasks like managing user profiles or sessions or retrieving product names. This is why Amazon makes extensive use of its own Key-Value system, Dynamo, in its shopping cart.
Other Key-Value Stores • Memcached – Key value stores. • Membase – Memcached with persistence and improved consistent hashing. • App. Fabric Cache – Multi region Cache. • Redis – Data structure server. • Riak – Based on Amazon’s Dynamo. • Project Voldemort – eventual consistent key value stores, auto scaling.
Memcached • • Very easy to setup and use. Consistent hashing. Scales very well. In memory caching, no persistence. LRU eviction policy. O(1) to set/get/delete. Atomic operations set/get/delete. No iterators, or very difficult.
Membase • • • Easy to manage via web console. Monitoring and management via Web console. Consistency and Availability. Dynamic/Linear Scalability, add a node, hit join to cluster and rebalance. Low latency, high throughput. Compatible with current Memcached Clients. Data Durability, persistent to disk asynchronously. Rebalancing (Peer to peer replication). Fail over (Master/Slave). v. Buckets are used for consistent hashing. O(1) to set/get/delete.
Document Stores Like Key-Value Stores, except Value is a “Document” § Data model: (key, “document”) pairs § Document format: JSON, XML, other semi-structured formats § Basic operations: Insert(key, document), Fetch(key), Update(key), Delete(key) § Also Fetch() based on document contents Example systems § Couch. DB, Mongo. DB, Simple. DB, … Document stores – Store arbitrary/extensible structures as a “value”
The records are called documents. “Documents” are encoded in a standard data exchange format such as XML, JSON (Java. Script Object Notation) or BSON (Binary JSON). Unlike the simple key-value stores, the value column in document databases contains semi-structured data – specifically attribute name/value pairs. A single column can house hundreds of such attributes, and the number and type of attributes recorded can vary from row to row. Also, unlike simple key-value stores, both keys and values are fully searchable in document databases.
Records within a single table can have different structures. An example record from Mongo. DB, using JSON format, might look like { “_id” : Object. Id(“ 4 fccbf 281168 a 6 aa 3 c 215443″), “first_name” : “Thomas”, “last_name” : “Jefferson”, “address” : { “street” : “ 1600 Pennsylvania Ave NW”, “city” : “Washington”, “state” : “DC” } } Embedded object Though records are called documents, they are not documents in the sense of a word processing document, although you can store binary data (using BSON format) in any of the fields in the document. You can also modify the structure of any document on the fly by adding and removing members from the document, either by reading the document into your program, modifying it and re-saving it, or by using various update commands.
Document databases are good for storing and managing Big Datasize collections of literal documents, like text documents, email messages, and XML documents, as well as conceptual “documents” like de-normalized (aggregate) representations of a database entity such as a product or customer. They are also good for storing “sparse” data in general, that is to say irregular (semi-structured) data that would require an extensive use of “nulls” in an RDBMS.
Mongodb • Data types: bool, int, double, string, object(bson), oid, array, null, date. • Database and collections are created automatically. • Lots of Language Drivers. • Capped collections are fixed size collections, buffers, very fast, FIFO, good for logs. No indexes. • Object id are generated by client, 12 bytes packed data. 4 byte time, 3 byte machine, 2 byte pid, 3 byte counter. • Possible to refer other documents in different collections but more efficient to embed documents. • Replication is very easy to setup. You can read from slaves.
Mongodb • Connection pooling is done for you. Sweet. • Supports aggregation. – Map Reduce with Java. Script. • You have indexes, B-Trees. Ids are always indexed. • Updates are atomic. Low contention locks. • Querying mongo done with a document: – Lazy, returns a cursor. – Reduceable to SQL, select, insert, update limit, sort etc. • There is more: upsert (either inserts or updates) – Several operators: • $ne, $and, $or, $lt, $gt, $incr, $decr and so on. • Repository Pattern makes development very easy.
Couchdb • Availability and Partial Partition Tolerance. • Views are used to query. Map/Reduce. • MVCC – Multi-version Concurrency Control. No locks. – A little overhead with this approach due to garbage collection. – Conflict resolution. Very simple, REST based. Schema Free. Shared nothing, seamless peer based Bi-Directional replication. Auto Compaction. Manual with Mongodb. Uses B-Trees Documents and indexes are kept in memory and flushed to disc periodically. • Documents have states, in case of a failure, recovery can continue from the state documents were left. • No built in auto-sharding, there are open source projects. • You can’t define your indexes. • • •
Column-based Stores (aka Wide-Column Stores) Based on Google’s Big. Table store. What is a column-based store? - Data tables are stored as sections of columns of data, rather than as rows of data.
Column Stores Row oriented Id username email Department 1 John john@foo. com Sales 2 Mary mary@foo. com Marketing 3 Yoda yoda@foo. com IT Column oriented Id Username email Department 1 John john@foo. com Sales 2 Mary mary@foo. com Marketing 3 Yoda yoda@foo. com IT
Cassandra • Tunable consistency. – Cassandra values Availability and Partitioning tolerance (AP). Tradeoffs between consistency and latency are tunable in Cassandra. You can get strong consistency with Cassandra (with an increased latency). But, you can't get row locking • • • Decentralized. Writes are faster than reads. No Single point of failure. Incremental scalability. Uses consistent hashing (logical partitioning) when clustered. Hinted handoffs. Peer to peer routing(ring). Thrift API. Multi data center support.
Cassandra at Netflix http: //techblog. netflix. com/2011/11/benchmarking-cassandra-scalability-on. html
Hbase • • Use Apache HBase when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Big. Table. Just as Big. Table leverages the distributed data storage provided by the Google File System, Apache Hbase provides Big. Table-like capabilities on top of Hadoop and HDFS. Features – – – Linear and modular scalability. Strictly consistent reads and writes. Automatic and configurable sharding of tables Automatic failover support between Region. Servers. Convenient base classes for backing Hadoop Map. Reduce jobs with Apache HBase tables. Easy to use Java API for client access. Block cache and Bloom Filters for real-time queries. Query predicate push down via server side Filters Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options Extensible jruby-based (JIRB) shell Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
Object Stores • Objectivity. • Db 4 o.
Objectivity • No need for ORM (Object Relational Mapping) – Closer to OOP (Object Oriented Programming). • • Complex data modeling. Schema evolution. Scalable Collections: List, Set, Map. Object relations. – Bi-Directional relations • ACID properties. • Blazingly fast, uses paging. • Supports replication and clustering.
Graph Stores • Based on Graph Theory. • Scale vertically, no clustering. • You can use graph algorithms easily.
Neo 4 J • • Nodes, Relationship. Traversals. HTTP/REST. ACID. Web Admin. Not too much support for languages. Has transactions.
Which one to use? • Key-value stores: – Processing a constant stream of small reads and writes. • Document databases: – Natural data modeling. Programmer friendly. Rapid development. Web friendly, CRUD. • RDMBS: – OLTP. SQL. Transactions. Relations. • OODBMS – Complex object models. • Data Structure Server: – Quirky stuff. • Columnar: – Handles size well. Massive write loads. High availability. Multiple-data centers. Map. Reduce • Graph: – Graph algorithms and relations. • Want more ideas ? http: //highscalability. com/blog/2011/6/20/35 -use-cases-for-choosing-your-nextnosql-database. html
Summary – the No. SQL Movement • A reaction to RDBMS do not scale and administrative complexity • Unpredictable RDBMS response times become “dangerous” at scale • Relax a subset of ACID to achieve scale: – Eventually consistent – Non-durable on commit – Do not fully isolate conflicting transactions – Do not support multi-item atomic update – Light-to-no schema enforcement – No complex query, no joins, no aggregates, no … • Simple programming model and administration – Eventual consistency often not “really” understood – App code required for complex queries • Good for some workloads at scale: – Cassandra, Mongo. DB, Couch. DB, Simple. DB, …
The Downsides of No. SQL • There is no universal query language like SQL - Each No. SQL product does things differently • SQL is very powerful and expressive • Relational databases are very mature 40+ years versus 6+ years • Relational databases are part of a vast “ecosystem” Tools availability
SQL Fights Back …
New. SQL is a class of modern RDMS that seeks to provide the same scalable performance of No. SQL systems for online transaction processing (read-write) workloads, while still maintaining the ACID guarantees of a traditional database system. New. SQL systems are relational databases designed to provide ACID compliance, real-time OLTP (On. Line Transaction Processing) and conventional SQL-based OLAP (On. Line Analytic Processing) in Big Data environments. These systems break through conventional RDBMS performance limits by employing No. SQL-style features such as column-oriented data storage and distributed architectures, or by employing technologies like in-memory processing , symmetric multiprocessing (SMP) or Massively Parallel Processing (MPP).
Flying on ACID!
What is Ne. WSQL? ? 451 Group’s Definition … • A DBMS that delivers the scalability and flexibility promised by No. SQL, while retaining the support for SQL queries and/or ACID, or to improve performance for appropriate workloads. Michael Stonebraker’s Definition … • SQL as the primary interface. • ACID support for transactions • Non-locking concurrency control. • High per-node performance. • Parallel, shared-nothing architecture – each node is independent and self-sufficient – do not share memory or storage
Technology is still in its infancy – only two years old. Google’s Spanner is an implementation of New. SQL. http: //static. googleusercontent. com/external_content/untrusted_dlcp/research. google. com/en//archive/spanner-osdi 2012. pdf http: //www. clustrix. com/Portals/146389/docs/451 How%20 will%20 the%20 database%20 incumbents%20 respond%20 to%20 No. SQL%20 an d%20 New. SQL. pdf http: //cacm. org/blogs/blog-cacm/109710 -new-sql-an-alternative-to-nosql-and-old-sql -for-new-oltp-apps/fulltext http: //highscalability. com/blog/2012/9/24/google-spanners-most-surprising-revelationnosql-is-out-and. html http: //www. linuxforu. com/2012/01/newsql-handle-big-data/