n SQL n Optimizer n View View View















 조건에 의한 결정 Primary_key : mandt+vbeln+posnr vbap_1 :")


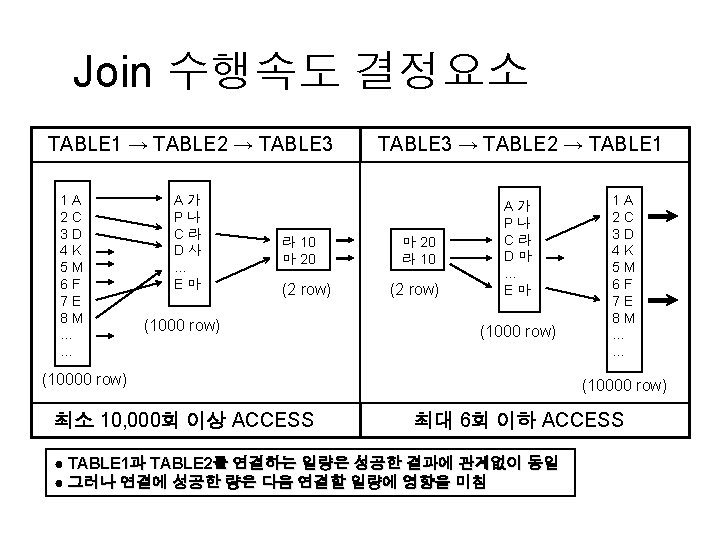
 n n n 그러면 이러한 Index Merge 현상을 강제적으로 없애주기위해서 Index Column")
, >")
 select * from emp where job like 'S%' and ename between 'A'")
 select * from emp where job between 'R' and 'Z' and ename")




 SQL> SELECT CHULNO, CHULDATE, CUSTNAME FROM CUSTOMER Y, CHULGOT X")
 LOOP-QUERY JOIN 2 차 가 공 SQL 운반 단위 SQL SQL")

 */ a. FLD 1, . . .")



 SELECT * FROM EKKO WHERE LIFNR = ZTH 02 -LIFNR. SELECT *")

 n 앞의 SQL 문장을 Join View를 활용한 경우( ZMARAV ) SELECT T")





 n 이런 경우에는 간단한 (Not) Exist Function 을 이용하여 처리함. MOVE 'X'")


- Slides: 47
목차 n SQL – n Optimizer – n View란 / View의 활용 / View 만들기 / View를이용한 Tuning 사례 성능에 대한 관점 – n Join의 활용 / 수행속도결정요소 / Join의 순서에따른 속도차이 / Join vs. Loop Query / Join 의 종류 View – n Index란 / Index 칼럼선정 / 데이터의 분포도 / NULL 문제의 해결 / Index의 결정요소 / Index를사용하지 않는경우 / Index Merge / Operator 의 Ranking / IN vs. BETWEEN Join – n Optomizer란 / Optimizer의 취사선택 / Hint 의 종류 Index – n History of SQL / Open SQL vs. Native SQL / SQL 실행 절차 On-Line / Batch / 부분범위처리 / 전체범위처리 Tuning 사례 , Q & A
SQL ? n
History of SQL n n Dr. E. F Codd 의 Relation Model of Data 발표(1970) - ACM journal SEQUEL 발표 (IBM) - Structured English Query Language. 1979년 Oracle 에 의해 RDBMS 발표 SEQUEL SQL
Open SQL vs. Native SQL n n Open SQL은 데이터베이스 테이블을 조작할 수 있는 ABAP/4 명 령어로 구성되어 있고, 서로다른 DBMS환경에서도 동일한 명령 어를 사용함. Command Set – – – – – SELECT INSERT UPDATE MODIFY DELETE OPEN CURSOR FETCH CLOSE CURSOR COMMIT WORK ROLLBACK WORK
Open SQL vs. Native SQL n Native SQL – – Open SQL의 Command Set 을 그대로 사용가능. Local DB, External DB 를 동시에 지원함. DDL, DML 사용가능 Error Handling, Host Variable 을 사용할 필요 없음. n Command Set u Transaction management - COMMIT - ROLLBACK u Data definition - CREATE TABLE DROP TABLE ALTER TABLE CREATE VIEW DROP VIEW CREATE INDEX DROP INDEX GRANT REVOKE u Data manipulation - SELECT INSERT UPDATE DELETE DECLARE CURSOR OPEN FETCH CLOSE
SQL 실행절차 n n n Open Parsing Execution Fetch Close
Optimizer란 SQL select col 1, col 2*10, from mara a, marc c where a. mandt = c. mandt and a. matnr = b. matnr and a. werks = ‘ 170’; Optimizer SQL 해석 n사용자는 요구만하고 Optimizer가 실행계획수립 n수립된 실행계획에따라 수행 속도 차이발생 n실행계획의 제어가 힘듬 n계획수립을위한 Factor부여 n집합적으로 접근 실행계획 작성 OBJ$ COL$ IND$ TAB$ VIEW$ DATA Dictionary 실행 MARA MARC RESB. . . DATA . . . .
Optimizer의 취사 선택 Ranking의 차이 select * from emp where ename like ‘AB%’ and empno = ‘ 7890’; EMPNO Index 만 사용 Index Merge 회 피 select * from emp where ename like ‘AB%’ and job like ‘SA%’; ename, job index중 하나만사용 혹은 Full Scan Low Cost의 선 택 select * from emp where empno > ‘ 10’; Hint에 의한 선 택 select /*+ INDEX(EMP JOB_IDX) */ * from emp where ename like ‘AB%’ and job like ‘SA%’; Full Table Scan JOB Index 만 사용
SQL에서 Index의 결정요소 n n EQUAL(‘=‘) 조건에 의한 결정 Primary_key : mandt+vbeln+posnr vbap_1 : mandt+erdat+matnr vbap_2 : mandt+matnr+werks Q) where 조건에 mandt, matnr이 ‘=‘ 조건으로 사용될 경우 어떤 Index를 사용하는가? Optimizer 에 의한 결정 Rule base - 기본적인 우선순위에의해 Access Path 결정 Cost base - 내부에서 구축한 통계정보(Table, Index)를 사용하여 최소한의 Cost를 산정하여 적절한 Access Path결정
Index 를 사용하지 않는경우 n Index Column 의 변형 - 외부적변형 : substr, rtrim, to_date, to_char, NVL, etc. select dept, ename, sal from emp where substr(job, 1, 4) = ‘SALE’; select dept, ename, sal from emp where sal*12 = 350000000 select dept, ename, sal from emp where sal = 350000000/12 - 내부적변형 : 내부적인 Type Conversion이 일어나는 경우 select chr, num, var, dat from emp where chr = 10 ; n n n select chr, num, var, dat from emp where to_number(chr) = 10 ; 모든 표현을 문자 Type 으로 표현하면 문제 없음 : ‘ 10’ 즉 문자와 숫자 Type 이 비교되면 문자가 숫자로 변함. Not 조건인 컬럼 NULL, NOT NULL 조건인 컬럼 문자형 컬럼에 Like 조건이나, ‘%’, ‘? ’ 로 시작하는 Like조건컬럼
Index Merge n n EMP 에 JOB, DEPTNO 가 각각의 INDEX를 가지고 있을경우 SELECT * FROM EMP WHERE JOB = ‘SALESMAN’ AND DEPTNO = 10; 위의 SQL 문장을 수행하면 INDEX MERGE 가 발생한다. 실행계획 Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 4 TABLE ACCESS (BY ROWID) OF 'EMP' 9 AND-EQUAL 5 INDEX (RANGE SCAN) OF 'EMP_2' (NON-UNIQUE) 5 INDEX (RANGE SCAN) OF 'EMP_1' (NON-UNIQUE)
Index Merge(2) n n n 그러면 이러한 Index Merge 현상을 강제적으로 없애주기위해서 Index Column 에 외부적인 변형을 가한다. 이때 두개의 Index 중에서 분포도가 좋은 Index 를 쓸 수 있도록 분포도가 좋지 않은 Index 에 변형을 가한다. SELECT * FROM EMP WHERE JOB = ‘SALESMAN’ AND DEPTNO||’’ = 10; 위 문장을 수행시키면 실행계획 Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 4 TABLE ACCESS (BY ROWID) OF 'EMP' 5 INDEX (RANGE SCAN) OF 'EMP_2' (NON-UNIQUE)
Operator의 Ranking n n SQL 문장의 where조건내의 Operator 들간의 우선 순위는 =, like(between), > < 임. Examples select * from emp where job like 'A%' and ename like 'F%' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 2 TABLE ACCESS (BY ROWID) OF 'EMP' 3 INDEX (RANGE SCAN) OF 'EMP_JOB' (NON-UNIQUE) 같은 like조건일경우 나중에 만들어진 Index를 사용함 select * from emp where job like 'S%' and ename > 'A' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 4 TABLE ACCESS (BY ROWID) OF 'EMP' 5 INDEX (RANGE SCAN) OF 'EMP_JOB' (NON-UNIQUE) like조건이 > < 조건보다 우선 순위가 높음
Operator의 Ranking(2) select * from emp where job like 'S%' and ename between 'A' and 'M' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 4 TABLE ACCESS (BY ROWID) OF 'EMP' 5 INDEX (RANGE SCAN) OF 'EMP_JOB' (NON-UNIQUE) like, Between은 같은 우선순위를 가지고 있으므로 나중에 만든 job index를 사용함 select * from emp where job between 'R' and 'Z' and ename like 'C%' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 4 TABLE ACCESS (BY ROWID) OF 'EMP' 5 INDEX (RANGE SCAN) OF 'EMP_JOB' (NON-UNIQUE) like, Between은 같은 우선순위를 가지고 있으므로 나중에 만든 job index를 사용함 select * from emp where job||'' between 'R' and 'Z' and ename like 'C%' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 1 TABLE ACCESS (BY ROWID) OF 'EMP' 2 INDEX (RANGE SCAN) OF 'EMP_ENAME' (NON-UNIQUE) ename Index를 사용하게하기위해 job Index를 변형 시킴
Operator의 Ranking(3) select * from emp where job between 'R' and 'Z' and ename > 'C' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 4 TABLE ACCESS (BY ROWID) OF 'EMP' 5 INDEX (RANGE SCAN) OF 'EMP_JOB' (NON-UNIQUE) select * from emp where job > 'C' and ename between 'A' and 'T' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 12 TABLE ACCESS (BY ROWID) OF 'EMP' 13 INDEX (RANGE SCAN) OF 'EMP_ENAME' (NON-UNIQUE) select * from emp where job > 'C' and ename||'' between 'A' and 'T' Rows Execution Plan -----------------------------0 SELECT STATEMENT GOAL: RULE 0 TABLE ACCESS (BY ROWID) OF 'EMP' 0 INDEX (RANGE SCAN) OF 'EMP_JOB' (NON-UNIQUE) Between 은 <> 보다 우선순위가 높으므로 job Index를 사용함 강제적으로 job Index 를 쓰고자 유도 하기 위해서 ename Index에 변형을 가함
IN 의 활용 SELECT * FROM TAB 1 WHERE COL 1 = ‘A’ AND COL 2 BETWEEN ‘ 111’ AND ‘ 112’ COL 2 COL 1 110 A 110 ROWID SELECT * FROM TAB 1 WHERE COL 1 = ‘A’ AND COL 2 IN ( ‘ 111’, ‘ 112’) COL 2 COL 1 10 110 A 10 B 41 111 A 11 111 B 65 111 C 96 111 D 5 112 A 73 112 B 18 112 C 45 114 A 22 INDEX 1 TABLE ACCESS BY ROWID TAB 1 INDEX RANGE SCAN INDEX 1 ROWID INDEX 1 CONCATENATION TABLE ACCESS BY ROWID TAB 1 INDEX RANGE SCAN INDEX 1
Access Path Ranking n n n n Single Row by ROWID Single Row by Cluster Join Single Row by hash cluster key with unique or primary key Single Row by unique or primary key Cluster Join Hash Cluster key Indexed Cluster key Composite Key Single-Column Indexes Bounded range search on indexed column Unbounded range search on indexed column Sort-Merge Join MAX, MIN of indexed column Order by on indexed column Full Table scan
실행계획에 따른 ACCESS량 ■ ACCESS량이 많음 SELECT a. FLD 1, . . . , b. FLD 1, . . . FROM TAB 2 b, TAB 1 a WHERE a. KEY 1 = b. KEY 2 AND b. FLD 2 like ‘A%’ AND a. FLD 1 = ‘ 10’ 100 row 50 row KEY 2 =KEY 1 FLD 1 =‘ 10’ . . INDEX (FLD 1) TAB 1 INDEX TAB 2 (KEY 2) ■ ACCESS량이 적음 70 row 100 row FLD 2 like ‘A%’ KEY 1 =KEY 2 운반 단위 FLD 2 like ‘A%’ FLD 1 = ‘ 10’ TAB 1 INDEX (KEY 1) TAB 2 INDEX (FLD 2)
처리범위에 따른 ACCESS량 연결고리 이상없슴 SELECT a. FLD 1, . . . , b. FLD 1, . . . FROM TAB 2 b, TAB 1 a WHERE a. KEY 1 = b. KEY 2 AND b. FLD 2 =‘ABC’ AND a. FLD 1 = ‘ 10’ ■ RULE-BASE OPTIMIZER 500 row 50 row . . 3 row 5 row 10 row FLD 2 =‘ABC’ KEY 1 =KEY 2 운반 단위 FLD 2 = ‘ABC’를 Check INDEX TAB 1 INDEX TAB 2 (FLD 1) (10, 000 row) (KEY 2) (1, 000 row) ■ ANALYZE table ■ HINT (/*+ ORDERED */) ■ SUPRESSING (a. FLD 1||’’ = ‘ 10’) ■ COST-BASE OPTIMIZER, TUNING KEY 2 =KEY 1 FLD 1 =‘ 10’ TUNING 방법 운반 단위 FLD 1 = ‘ 10’을 Check TAB 1 INDEX (10, 000 row)(KEY 1) TAB 2 INDEX (1, 000 row) (FLD 2)
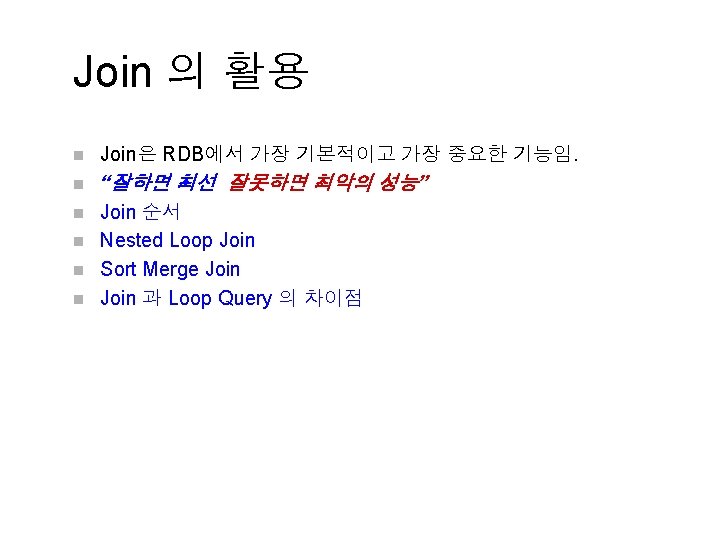
JOIN의 순서에 따른 속도차이(예제) SQL> SELECT CHULNO, CHULDATE, CUSTNAME FROM CUSTOMER Y, CHULGOT X WHERE X. CUSTON = Y. CUSTNO AND X. CHULDATE = ‘ 941003’ AND Y. NATION = ‘KOR’ NESTED LOOPS TABLE ACCESS BY ROWID CUSTOMER INDEX RANGE SCAN CU_NATION TABLE ACCESS BY ROWID CHULGOT AND-EQUAL INDEX RANGE SCAN CH_CUSTNO INDEX RANGE SCAN CH_CHULDATE SQL> SELECT CHULNO, CHULDATE, CUSTNAME FROM CHULGOT X, CUSTOMER Y WHERE X. CUSTON = Y. CUSTNO AND X. CHULDATE = ‘ 941003’ AND Y. NATION = ‘KOR’ NESTED LOOPS TABLE ACCESS BY ROWID CHULGOT INDEX RANGE SCAN CH_CHULDATE TABLE ACCESS BY ROWID CUSTOMER INDEX UNIQUE SCAN PK_CUSTNO 1 rows 0. 15 sec 1 rows 0. 04 sec
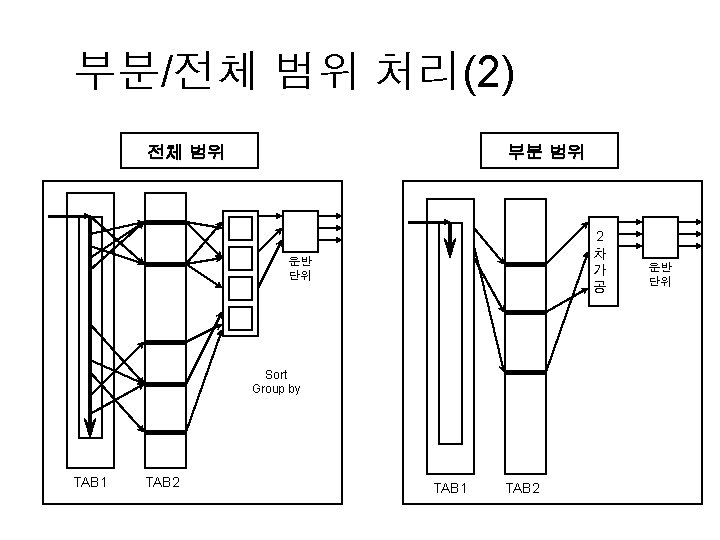
JOIN과 LOOP QUERY(전체범위처리) LOOP-QUERY JOIN 2 차 가 공 SQL 운반 단위 SQL SQL TAB 1 TAB 2 운반 단위
Nested Loop Join SELECT a. FLD 1, . . . , b. FLD 1, . . . FROM TAB 2 b, TAB 1 a WHERE a. KEY 1 = b. KEY 2 AND b. FLD 2 =‘ABC’ AND a. FLD 1 = ‘ 10’ • 순차적(부분범위처리 가능) • 종속적(먼저 처리되는 테이블의 처리범위에따라 처리량 결정) • Random Access 위주(단점) • 연결고리 상태에 따라 영향이 큼 • 주로 좁은 범위 처리에 유리 Table Access By ROWID FLD 1 =‘ 10’ KEY 2 =KEY 1 Table Access by ROWID 운반 단위 . . FLD 2 = ‘ABC’를 Check INDEX (FLD 1) TAB 1 INDEX TAB 2 (KEY 2)
Sort Merge Join SELECT /*+ use_merge(a b) */ a. FLD 1, . . . , b. FLD 1, . . . FROM TAB 2 b, TAB 1 a WHERE a. KEY 1 = b. KEY 2 AND b. FLD 2 =‘ABC’ AND a. FLD 1 = ‘ 10’ • 동시적(무조건 전체범위처리) • 독립적(자기의 리범위만으로 처리량 결정) • Scan Access 위주 • 연결고리 상태에 따라 영향無 • 주로 넓은 범위 처리에 유리 • Sort 발생(단점) Table Access By ROWID FLD 1 =‘ 10’ TAB 1 KEY 2 =KEY 1 S O R T . . INDEX (FLD 1) a. key 1 = b. key 2를 조건으로 Merge Table Access by ROWID 운반 단위 TAB 2 INDEX (KEY 2)
View 만들기 SELECT SINGLE * FROM EKKO WHERE EBELN = TAB-EBELN. SELECT SINGLE * FROM LFA 1 WHERE LIFNR = EKKO-LIFNR. . SELECT SINGLE NAME 1 INTO TAB-NAME 1 FROM ZEKKO_LFA 1 WHERE EBELN = TAB-EBELN. ZEKKO_LFA 1 View : SELECT T 1. MANDT, T 1. EBELN, T 1. LIFNR, T 2. NAME 1 FROM EKKO T 1, LFA 1 T 2 WHERE T 1. MANDT = T 2. MANDT AND T 1. LIFNR = T 2. LIFNR 위의 SQL 문장은 EKKO, LFA 1 Table 정보를 읽어 업체명을 가져 오는 내용임. “Select all “ 로 가져오지 않고, 원하는 Field만 가져옴으로써 Overhead 를 줄일 수 있다.
View 만들기(2) SELECT * FROM EKKO WHERE LIFNR = ZTH 02 -LIFNR. SELECT * FROM EKPO WHERE LOEKZ = ' ' AND ELIKZ = ' ' AND EBELN = EKKO-EBELN AND MATNR = ZTH 02 -MATNR AND LGORT = ZTH 02 -LGORT AND LGORT <> 'S 008'. SELECT * FROM EKET WHERE EBELN = EKPO-EBELN AND EBELP = EKPO-EBELP AND EINDT <= SY-DATUM. SELECT * FROM ZEKKO_POET WHERE LIFNR = ZTH 02 -LIFNR AND LOEKZ = ' ' AND ELIKZ = ' ' AND MATNR = ZTH 02 -MATNR AND LGORT = ZTH 02 -LGORT AND LGORT <> 'S 008' AND EINDT <= SY-DATUM. ZEKKO_POET View : SELECT T 1. MANDT, T 1. LIFNR, T 1. EBELN, T 2. LOEKZ, T 2. ELIKZ, T 2. MATNR, T 2. LGORT, T 2. EBELP, T 3. MENGE, T 3. WEMNG, T 3. EINDT FROM EKKO T 1, EKPO T 2, EKET T 3 WHERE T 1. MANDT = T 2. MANDT AND T 2. MANDT = T 3. MANDT AND T 1. EBELN = T 2. EBELN AND T 2. EBELN = T 3. EBELN AND T 2. EBELP = T 3. EBELP
Loop Query n n 정의 선행SQL로부터 추출된 집합에대해 건건이 상수화된 조건 자료 로 활용하여 후행 SQL을 반복수행 Examples SELECT * FROM MARA WHERE LVORM NE 'X' AND ( MTART = 'ROH' OR MTART = 'HALB' ). SELECT * FROM MARC WHERE MATNR = MARA-MATNR. ~ ~ ~ ~ ~ ENDSELECT. n n 문제점 N/W Traffice , Resource 낭비(CPU, Memory). . . 대안 Join 을 효과적으로 활용함(View이용)
Loop Query(2) n 앞의 SQL 문장을 Join View를 활용한 경우( ZMARAV ) SELECT T 1. MANDT, T 1. MATNR, T 2. WERKS, T 1. LVORM, T 1. MTART, T 2. LGFSB, T 2. SOBSL, T 2. EKGRP, T 2. DISPO, T 2. BESKZ FROM MARA T 1, MARC T 2 WHERE T 1. MANDT = T 2. MANDT AND T 1. MATNR = T 2. MATNR n n ABAP/4 개발환경에서는 Join 문장을 사용할 수 없으므로 View를 생성해 놓고 그 View를 프로그램내에서 Table처럼 Access한다. 앞장의 SQL 문을 view 이용하여 바꿈 SELECT * FROM ZMARAV APPENDING TABLE MARA_TAB PACKAGE SIZE 5000 WHERE LVORM NE 'X' AND MTART IN ('ROH', 'HALB') ENDSELECT. n 효과. .
성능에대한 관점 n On-Line n Batch
Full Scan Policy n n SELECT * FROM 위 문장이 – ABAP/4 환경 n n – n ZP 022; Open SQL Native SQL 일반 SQL 환경 mandt 를 포함한 어떤 Index 사용 Full table scan Full Table scan 가장 많이 사용되는 Open SQL 환경에서 위같은 문장을 쓰 면서 Full Table Scan 을 유도하기 위해서는 다음과 같 은 방법을 사용 – – view 를 만듬(Hint 사용) create view zp 022 v as select from zp 022; view 를 Select 함 select * from zp 022 v; /*+ FULL_SCAN */ *
Storage Para. of Table PCTFREE n PCTUSED n FREELIST n INITTRANS n etc. n
Exist Check SELECT * FROM EINA LOOP AT INTO TABLE ITAB_EINA WHERE MATNR = MARA-MATNR AND LOEKZ EQ ' '. ITAB_EINA. SELECT * FROM EINE " INTO ITAB_EINE WHERE INFNR = ITAB_EINA-INFNR AND NOT ( BSTAE = '2' OR BSTAE = 'B' OR BSTAE = 'C' ). MOVE EINE TO ITAB_EINE. APPEND ITAB_EINE. ENDSELECT. ENDLOOP. DESCRIBE TABLE ITAB_EINE LINES LIN. IF LIN > 0. MOVE 'X' TO ZP 022 -ABSKZ. ELSE. MOVE SPACE TO ZP 022 -ABSKZ. ENDIF.
Exist Check(2) n 이런 경우에는 간단한 (Not) Exist Function 을 이용하여 처리함. MOVE 'X' TO ITAB_ZP 022 -ABSKZ. EXEC SQL. SELECT ' ' INTO : ITAB_ZP 022 -ABSKZ FROM DUAL WHERE NOT EXISTS ( SELECT 'X' FROM EINE A, EINA B WHERE A. MANDT = B. MANDT AND A. INFNR = B. INFNR AND A. BSTAE NOT IN ('2', 'B', 'C') AND B. MANDT = '170' AND B. MATNR = : ITAB_ZMARAV-MATNR AND B. LOEKZ = ' ' ) ENDEXEC.
Data Insert 방법 n 기존 LOOP AT ITAB_ZP 022. MOVE-CORRESPONDING INSERT ZP 022. ENDLOOP. ITAB_ZP 022 COMMIT WORK. n 변경후 INSERT ZP 022 FROM TABLE ITAB_ZP 022. COMMIT WORK. TO ZP 022.
Data Delete 방법 n 기존 SELECT * FROM ZP 022. DELETE ZP 022. ENDSELECT. COMMIT WORK. n 변경후 DELETE FROM COMMIT WORK. ZP 022 CLIENT SPECIFIED WHERE MANDT = '170'.