MPICommrank MPICOMMWORLD rank if rank 0 MPIBsendbuf 1


; if (rank == 0) { MPI_Bsend(buf 1, 20,")
Барьерная синхронизация MPI_Comm_rank( MPI_COMM_WORLD, &rank ); if (rank == 0) { MPI_Bsend(buf 1, 20, MPI_INT, 1, 25, MPI_COMM_WORLD); MPI_Ssend(buf 2, 20, MPI_INT, 1, 26, MPI_COMM_WORLD); printf(“Отправка данных окончена n”); } else if (rank==1) { MPI_Recv(source 1, 20, MPI_INT, 0, 26, MPI_COMM_WORLD, &status); MPI_Recv(source 2, 20, MPI_INT, 0, 25, MPI_COMM_WORLD, &status); printf(“Прием данных окончен n”); } MPI_Barrier(MPI_COMM_WORLD); printf(“Завершение работы процесса %d n”, rank); Параллельное программирование с использованием технологии MPI Аксёнов С. В. 3

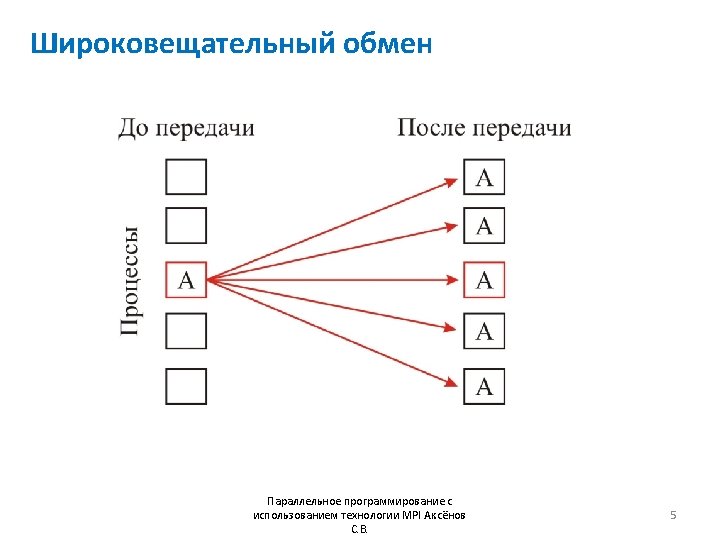
![Широковещательный обмен #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])](http://slidetodoc.com/presentation_image/285d3193e6c1768823f8410a879a9334/image-6.jpg "Широковещательный обмен #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])")
Широковещательный обмен #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[]) { int rank, *a; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); a = malloc(100*sizeof(int)); if (rank==0) for(int i =0; i<100; i++) a[i] =i; MPI_Bcast(a, 100, MPI_INT, 0, MPI_COMM_WORLD); MPI_Finalize(); return 0; } Параллельное программирование с использованием технологии MPI Аксёнов С. В. 6

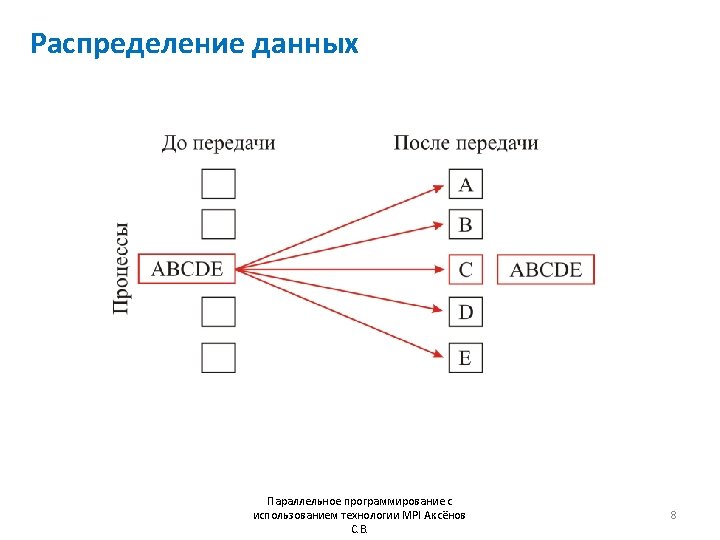
![Пример MPI_Scatter #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])](http://slidetodoc.com/presentation_image/285d3193e6c1768823f8410a879a9334/image-9.jpg "Пример MPI_Scatter #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])")
Пример MPI_Scatter #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[]) { int rank, gsize, *sendbuf, size; int root =0, rbuf[100]; MPI_Init(&argc, &argv); MPI_Comm_size( comm, &gsize); MPI_Comm_rank(MPI_COMM_WORLD, &rank); size = gsize*100; sendbuf = malloc(size*sizeof(int)); if (rank==root) for( i =0; i<size; i++) sendbuf[i] =i; MPI_Scatter(sendbuf, 100, MPI_INT, root, MPI_COMM_WORLD); MPI_Finalize(); return 0; } Параллельное программирование с использованием технологии MPI Аксёнов С. В. 9
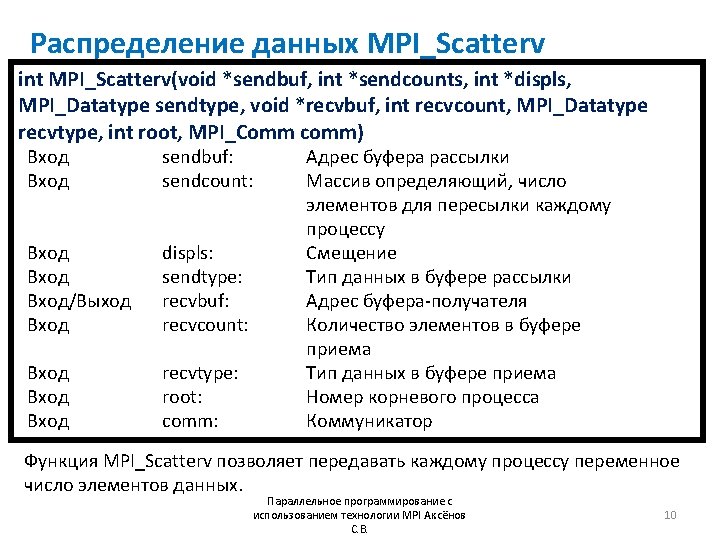
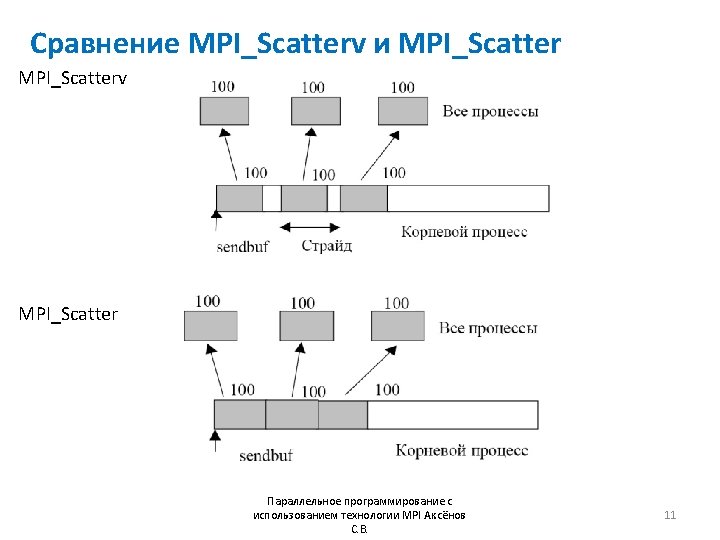
![Пример MPI_Scatterv #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])](http://slidetodoc.com/presentation_image/285d3193e6c1768823f8410a879a9334/image-12.jpg "Пример MPI_Scatterv #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])")
Пример MPI_Scatterv #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[]) { int gsize, *sendbuf, root, rbuf[100], i, *displs, *scounts; MPI_Init(&argc, &argv); MPI_Comm_size(comm, &gsize); sendbuf = malloc(gsize*stride*sizeof(int)); displs = malloc(gsize*sizeof(int)); scounts = malloc(gsize*sizeof(int)); for (i=0; i<gsize; ++i) { displs[i] = i*stride; scounts[i] = 100; } MPI_Scatterv( sendbuf, scounts, displs, MPI_INT, rbuf, 100, MPI_INT, root, MPI_COMM_WORLD); MPI_Finalize(); return 0; } Параллельное программирование с использованием технологии MPI Аксёнов С. В. 12

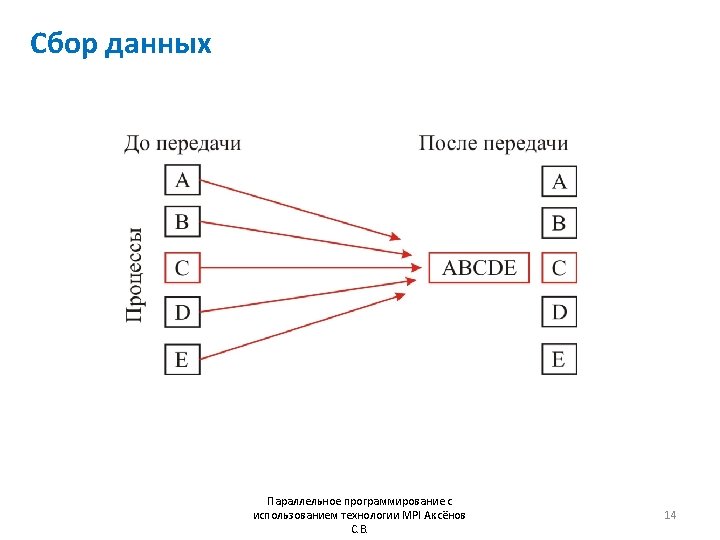
![Пример MPI_Gather #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])](http://slidetodoc.com/presentation_image/285d3193e6c1768823f8410a879a9334/image-15.jpg "Пример MPI_Gather #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])")
Пример MPI_Gather #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[]) { int gsize, sendarray[100]; int root=0, rank, *rbuf; MPI_Init(&argc, &argv); MPI_Comm_rank( comm, &rank); if ( rank == root) { MPI_Comm_size(MPI_COMM_WORLD, &gsize); rbuf = malloc(gsize*100*sizeof(int)); } MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, MPI_COMM_WORLD); MPI_Finalize(); return 0; } Параллельное программирование с использованием технологии MPI Аксёнов С. В. 15

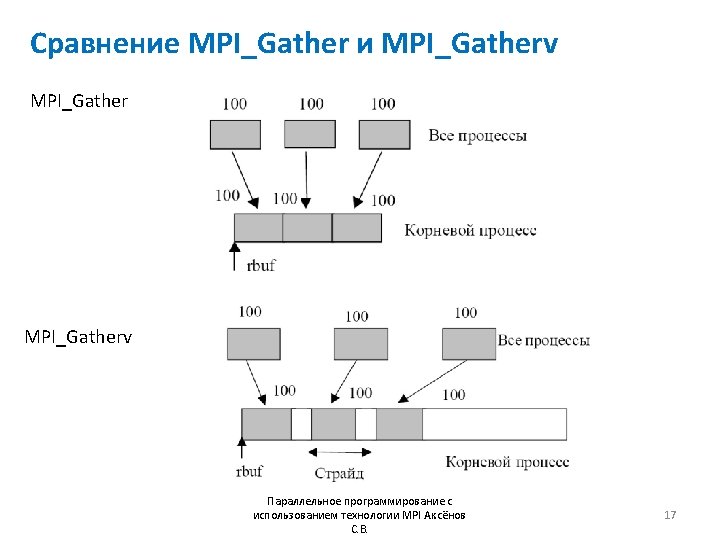
![Пример MPI_Gatherv #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])](http://slidetodoc.com/presentation_image/285d3193e6c1768823f8410a879a9334/image-18.jpg "Пример MPI_Gatherv #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])")
Пример MPI_Gatherv #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[]) { int gsize, sendarray[100], root=0, *rbuf, stride=105, *displs, *rcounts; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &gsize); rbuf = malloc(gsize*stride*sizeof(int)); displs = malloc(gsize*sizeof(int)); rcounts = malloc(gsize*sizeof(int)); for (int i=0; i<gsize; i++) { displs[i] = i*stride; rcounts[i] = 100; } MPI_Gatherv( sendarray, 100, MPI_INT, rbuf, rcounts, displs, MPI_INT, root, MPI_COMM_WORLD); MPI_Filnalize(); return 0; } Параллельное программирование с использованием технологии MPI Аксёнов С. В. 18

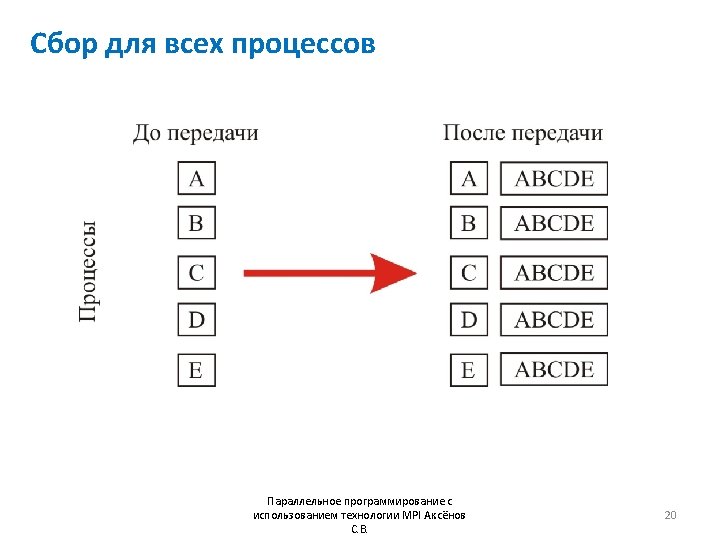
![Пример MPI_Allgather #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])](http://slidetodoc.com/presentation_image/285d3193e6c1768823f8410a879a9334/image-21.jpg "Пример MPI_Allgather #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[])")
Пример MPI_Allgather #include “mpi. h” #include <stdio. h> int main (int argc, char *argv[]) { int gsize, sendarray[100], *rbuf; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &gsize); rbuf = malloc(gsize*100*sizeof(int)); MPI_Allgather( sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, MPI_COMM_WORLD); MPI_Finalize(); return 0; } Параллельное программирование с использованием технологии MPI Аксёнов С. В. 21
- Slides: 21