More IO services and recovery Jeff Chase Duke


 • RAID appliance • Multiple protocols – i. SCSI, NFS,")







 that the service needs to")

")

 • Disk may reorder pending writes. – Limited ordering")

 physical disk")

 physical disk sector")


 Root Inode Metadata File Data Blocks Net. App Confidential")


")







 Your program")



 on")


- Slides: 40
More I/O services and recovery Jeff Chase Duke University
The De. Filer buffer cache File abstraction implemented in upper DFS layer. All knowledge of how files are laid out on disk is at this layer. Access underlying disk volume through buffer cache API. Obtain buffers (dbufs), write/read to/from buffers, orchestrate I/O. DBuffer dbuf = get. Block(block. ID) release. Block(dbuf) DBuffer. Cache Device I/O interface Asynchronous I/O to/from buffers block read and write Blocks numbered by block. IDs DBuffer read(), write() start. Fetch(), start. Push() wait. Valid(), wait. Clean()
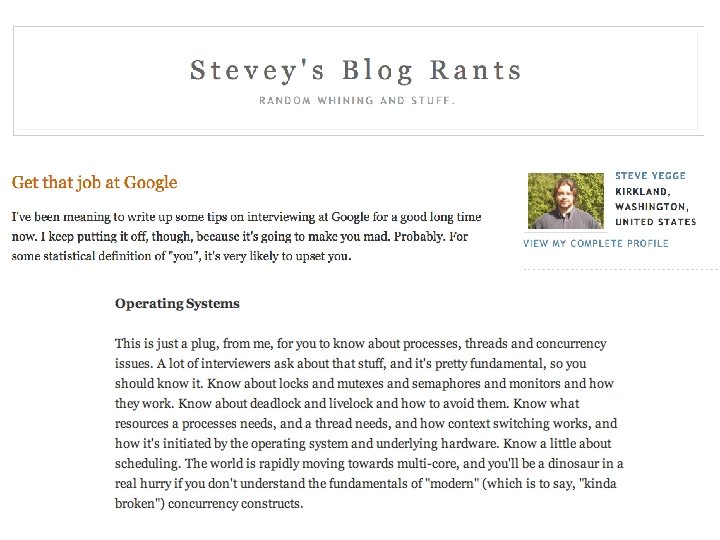
“Filers” • Network-attached (IP) • RAID appliance • Multiple protocols – i. SCSI, NFS, CIFS • Admin interfaces • Flexible configuration • Lots of virtualization: dynamic volumes • Volume cloning, mirroring, snapshots, etc. • Net. App technology leader since 1994 (WAFL)
What is clustered Data ONTAP? ¡ Net. App’s “scale-out” clustering solution ¡ 1 -24 “nodes” (filers), 10 Gb ethernet interconnect ¡ Designed for extreme performance and flexibility ¡ Key concepts: – Vserver – Aggregate – Volume (Flex. Vol) Net. App Confidential - Limited Use 5
Architecture of clustered Data ONTAP Client Node Network Spin. NP N-Blade Network, Protocols D-Blade WAFL, RAID, Storage, HA, NVRAM HA Pair N-Blade HA Pair Client Disks Net. App Confidential - Limited Use 6
Notes on “scale-out” • Net. App filer solution is “scalable”. – “Just buy more blades. ” – Load is distributed: among the blades, interfaces, disks, etc. . – If we add another blade, it adds to the total load we can serve. • What about failure? – Redistribute load to the surviving blades. – But what if the failed blade has some critical state? • E. g. , D-blades have writeback I/O caches. – Replicate nodes in “HA pairs” (Highly Available). – If one fails, the other can take over. (like the “buddy system”)
File data and metadata A file’s data blocks could be “anywhere” on disk. The file’s inode maps them. A fixed-size inode has a fixed-size block map. How to represent large files that have more logical blocks than can fit in the inode’s map? attributes block map inode An inode could be “anywhere” on disk. How to find the inode for a given file? Once upo n a time /nin a l and far away , /nlived t he wise and sage wizard. data blocks
Representing Large Files inode Classic Unix file systems inode == 128 bytes inodes are packed into blocks direct block map indirect block Each inode has 68 bytes of attributes and 15 block map entries. Suppose block size = 8 KB 12 direct block map entries: 96 KB of data. One indirect block pointer in inode: + 16 MB of data. One double indirect pointer in inode: +2 K indirects. Maximum file size is 96 KB + 16 MB + (2 K*16 MB) +. . . double indirect blocks
Skewed tree block maps • Inodes are the root of a tree-structured block map. – Like multi-level hierarchical page tables, but • These maps are skewed. – Low branching factor at the root: just enough for small files. – Small files are cheap: just need the inode to map it. – Inodes for small files are small…and most files are small. • Use indirect blocks for large files – Requires another fetch for another map block – But the shift to a high branching factor covers most large files. • Double indirects allow very large files, at higher cost. • Other advantages to trees?
Writes in the FS buffer cache • Delayed writes – Partial-block writes may be left dirty in the cache. The push is deferred in expectation of later writes to the same block. • Write-behind – Dirty blocks are pushed asynchronously; write call returns before push is complete. – May lose data! Be sure you know the failure semantics of the file systems you use in your life. A classic UNIX file system may discard any subset of recent writes on failure. – Fsync system call to wait for push, for use by applications that really want to know their data is “safe”. – Good file systems sync-on-close.
Failures, Commits, Atomicity • Hard state is state (data) that the service needs to function correctly. Soft state is non-critical. • What guarantees does the system offer about the hard state if the system fails? – Durability • Did my writes commit, i. e. , are they saved? Can I get it back? – Failure atomicity • Can a set of writes “partly commit”? – Recoverability and Corruption • Can we recover a previous state? • Is the state consistent? • Is the metadata well-formed?
Failure/Atomicity • File writes are not guaranteed to commit until close. – – A process can force commit with a sync. The system forces commit every (say) 30 seconds. Failure may lose an arbitrary subset of writes. Want better reliability? Use a database. • Problem: safety of metadata. – – How to protect the integrity of the metadata structures? E. g. , directory tree, inodes, block map trees Metadata is a complex linked data structure, e. g. , a tree. Must be possible to restore with a scrub (“fsck”) on restart.
Write Anywhere File Layout (WAFL)
Metadata updates and recovery • Metadata updates incur extra seek overhead. – E. g. , extending a file requires writes to the inode, direct and/or indirect blocks, cylinder group bit maps and summaries, and the file block itself. • Metadata items are often updated repeatedly, so delayed writes help. • But delayed writes incur a higher risk of file system corruption in a crash. – If you lose your metadata, you are dead in the water. • Option 1: careful write ordering, with scrub on recovery • Option 2: shadowing (e. g. , WAFL) • Option 3: logging/journaling (used in databases)
Disk write behavior (cartoon version) • Disk may reorder pending writes. – Limited ordering support (“do X before Y”). – Can enforce ordering by writing X synchronously: wait for write of X to complete before issuing Y. • Writes at sector grain are atomic (512 bytes? ). • Writes of larger blocks may fail “in the middle”. • Disk may itself have a writeback cache. – Even “old” writes may be lost. – (Can be disabled. )
Metadata write ordering A common approach to safety of file system metadata: • Order essential metadata writes carefully. – Various techniques to enforce a partial order of writes to the disk, i. e. , ensure that write A completes before write B begins. • Maintain invariants! E. g. , avoid dangling references. – Never recycle a structure (block or inode) before zeroing all pointers to it (truncate, unlink, rmdir). – Never point to a new structure before it has been initialized. E. g. , sync inode on creat before filling directory entry, and sync a new block before writing the block map. • Traverse the metadata tree to rebuild derived structures. – Can rebuild e. g. , free block bitmaps, free inode bitmaps.
A quick peek at sequential write in BSD Unix “FFS” (Circa 2001) physical disk sector write stall read note sequential block allocation sync command (typed to shell) pushes indirect blocks to disk sync read next block of free space bitmap (? ? ) time in milliseconds
Sequential writes: a closer look physical disk sector 16 MB in one second (one indirect block worth) 140 ms delay for cylinder seek etc. (? ? ? ) time in milliseconds Push indirect blocks synchronously. longer delay for head movement to push indirect blocks write stall
Small-File Create Storm 50 MB inodes and file contents (localized allocation) physical disk sector note synchronous writes for some metadata sync delayed-write metadata sync write stall time in milliseconds
WAFL and Writes • In WAFL, any modified data or metadata can go anywhere on the disk. – Don’t overwrite the “old” copies! – Group writes together and write them in bursts! – Avoid small writes! better RAID performance • An arbitrary stream of updates can be installed atomically. – Retain the old copy, switch to new copy with a single write to the root of the tree (shadowing). – Old copy lives on as a point-in-time snapshot.
Shadowing 1. starting point 2. write new blocks to disk modify purple/grey blocks prepare new block map 3. overwrite block map (atomic commit) and free old blocks
WAFL’s on-disk structure (high level) Root Inode Metadata File Data Blocks Net. App Confidential - Limited Use 23
WAFL Snapshots The snapshot mechanism is used for user-accessible snapshots and for transient consistency points.
Another Look
Write Anywhere File Layout (WAFL)
WAFL and the disk system • WAFL generates a continuous stream of large-chunk contiguous writes to the disk system. – WAFL does not overwrite the old copy of a modified structure: it can write a new copy anywhere. So it gathers them together. • Large writes minimize seek overhead and deliver the full bandwidth of the disk. • WAFL gets excellent performance by/when using many disks in tandem (“RAID”)… • …and writing the chunks in interleaved fashion across the disks (“striping”). • Old copies of the data and metadata survive on the disk and are accessible through point-in-time “snapshots”.
Building a better disk: RAID 5 • Redundant Array of Independent Disks • Striping for high throughput for pipelined reads. • Data redundancy: parity • Enables recovery from one disk failure • RAID 5 distributes parity: no“hot spot” for random writes • Market standard Fujitsu
RAID Parity with XOR • Bitwise exclusive or: xor • “One or the other but not both” • Bit sum, with no carry – Commutative, associative • Or: sum up the 1 s, and choose parity to make the sum even. – “Even parity” • If any bit is lost, xor of the surviving bits gets it back. • If any bit flips, the parity flips. • What if two bits flip or are lost? XOR
WAFL & NVRAM ¡ NVRAM provides low latency pending request stable storage – Many clients don’t consider a write complete until it has reached stable storage ¡ Allows WAFL to defer writes until many are pending (up to ½ NVRAM) – Big write operations: get lots of bandwidth out of disk – Crash is no problem, all pending requests stored; just replay – While ½ of NVRAM gets written out, other is accepting requests (continuous service) Net. App Confidential - Limited Use 30
Postnote • The following slides on logging were not covered in lecture and won’t be tested.
Alternative: Logging/Journaling • Logging can be used to localize synchronous metadata writes, and reduce the work that must be done on recovery. • Universally used in database systems. • Used for metadata writes in journaling file systems • Key idea: group each set of related updates into a single log record that can be written to disk atomically (“all-or-nothing”). – Log records are written to the log file or log disk sequentially. • No seeks, and preserves temporal ordering. – Each log record is trailed by a marker (e. g. , checksum) that says “this log record is complete”. – To recover, scan the log and reapply updates.
Transactions group a sequence of operations, often on different objects. BEGIN T 1 read X read Y … write X END BEGIN T 2 read X write Y … write X END
Recoverable Data with a Log volatile memory (e. g. , buffer cache) Your program (or file system or database software) executes transactions that read or change the data structures in memory. Your data structures in memory Log transaction events as they occur Push a checkpoint or snapshot to disk periodically snapshot log After a failure, replay the log into the last snapshot to recover the data structure.
Transactions: logging Commit Write. N Write 1 Begin transaction Append info about modifications to a log Append “commit” to log to end x-action Write new data to normal database Single-sector write commits x-action (3) Begin 1. 2. 3. 4. ê … Transaction Complete Invariant: append new data to log before applying to DB Called “write-ahead logging”
Transactions: logging Commit Write. N … Write 1 Begin transaction Append info about modifications to a log Append “commit” to log to end x-action Write new data to normal database Single-sector write commits x-action (3) Begin 1. 2. 3. 4. ê What if we crash here (between 3, 4)? On reboot, reapply committed updates in log order.
Transactions: logging Write. N … Write 1 Begin transaction Append info about modifications to a log Append “commit” to log to end x-action Write new data to normal database Single-sector write commits x-action (3) Begin 1. 2. 3. 4. ê What if we crash here? On reboot, discard uncommitted updates.
Anatomy of a Log • A log is a sequence of records (entries) on recoverable storage. • Each entry is associated with some transaction. • The entries for transaction T record execution progress of T. • Atomic operations: – Append/write entry to log tail – Truncate entries from log head (old) Log Sequence Number (LSN) . . . LSN 11 XID 18 LSN 12 XID 18 Transaction ID (XID) LSN 13 XID 19 commit record LSN 14 XID 18 commit – Read/scan entries • Log writes are atomic and durable, and complete detectably in order. tail (new)
Using a Log • Log entries for T record the writes by T or method calls in T. – Redo logging head (old) Log Sequence Number (LSN) • To recover, read the checkpoint Transaction ID (XID) and replay committed log entries. – “Redo” by reissuing writes or reinvoking the methods. – Redo in order (head to tail) – Skip the records of uncommitted Ts • No T can affect the checkpoint until T’s commit is logged. – Write-ahead logging commit record . . . LSN 11 XID 18 LSN 12 XID 18 LSN 13 XID 19 LSN 14 XID 18 commit tail (new)
Managing a Log • On checkpoint, truncate the log – No longer need the entries to recover • Checkpoint how often? Tradeoff: – Checkpoints are expensive, BUT – Long logs take up space head (old) Log Sequence Number (LSN) – Is it safe to redo/replay records whose effect is already in the checkpoint? – Checkpoint “between” transactions, so checkpoint is a consistent state. – Lots of approaches LSN 11 XID 18 LSN 12 XID 18 Transaction ID (XID) LSN 13 XID 19 – Long logs increase recovery time • Checkpoint+truncate is “atomic” . . . commit record LSN 14 XID 18 commit tail (new)