MMachine and Grids Parallel Computer Architectures Navendu Jain






 n A MAP chip comprises : n n n Three 64")

")

 n")
 n Vertical Threads (V-Threads) Thread level parallelism (a standard process) n")
 VLIW,")

 n Communication n Register-Register read/writes n")








![Ideas: Divergence M-Machine n On-chip cache Register based mech. [Delays] n Broadcasting and Point-to-point](https://slidetodoc.com/presentation_image_h/25178632049884e8380ff6b745b2cce4/image-25.jpg "Ideas: Divergence M-Machine n On-chip cache Register based mech. [Delays] n Broadcasting and Point-to-point")
 M-Machine Grid Processor Arch. n Data Caches far from ALUs n")

 n On-fly data-dependence detection (RAW/WAR) n TLP/ILP Balance – M Multi-Computer")

- Slides: 29
M-Machine and Grids Parallel Computer Architectures Navendu Jain
Readings The M-machine multicomputer Marco et al. , MICRO 1995 n Exploiting fine-grain thread level parallelism on the MIT multi-ALU processor Keckler et al. , MICRO 1998 n A design space evaluation of grid processor architectures Nagarajan et al. , MICRO 2001 n
Outline n The M-Machine Multicomputer n Thread Level Parallelism on M-Machine n Grid Processor Architectures n Review and Discussion
The M-Machine Multicomputer
Design Motivation n Achieve higher throughput of memory resources Increase chip area devoted to processors n Arithmetic to bandwidth ratio of 12 operations/word n Minimize global communication (local sync. ) n Faster execution of fixed size problems n Easier programmability of parallel computers n n Incremental approach
Architecture A bi-directional 3 -D network mesh of multithreaded processing nodes n A chip comprises of a multi-ALU processor (MAP) and 128 KB on-chip sync. DRAM n A user-accessible message passing system (SEND) n Single global virtual address space n Target CLK 100 MHz (control logic 40 MHz) n
Multi-ALU processor (MAP) n A MAP chip comprises : n n n Three 64 -bit 3 -issue clusters 2 -way interleaved on-chip cache A Memory Switch A Cluster switch External memory interface On-chip network interfaces and routers
A MAP Cluster n n n 64 -bit three issue pipelined processor 2 Integer ALUs 1 Floating point ALU Register Files 4 KB Instruction cache A MAP instruction has 1, 2 or 3 operations
Map Chip Die (18 mm side, 5 M transistors)
Exploiting Parallelism on M-Machine
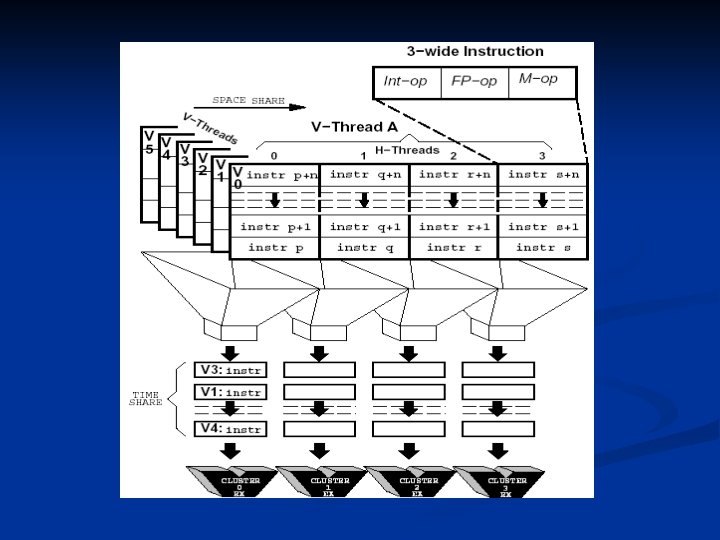
Threads Exploit ILP both with-in and across the clusters n Horizontal Threads (H-Threads) n Instruction level parallelism n Executes on a single MAP cluster n 3 -wide instruction stream n Communication/synchronization through messages/registers/memory n Max. 6 H-Threads can be interleaved dynamically on a cycle-by-cycle basis n
Threads (contd. ) n Vertical Threads (V-Threads) Thread level parallelism (a standard process) n contains up-to 4 H-Threads (one per cluster) n Flexibility of scheduling (compiler/run-time) n Communication/synchronization through registers n At-most 6 resident V-Threads n n 4 user slots, 1 event slot, 1 exception
Concurrency Model Three Levels of Parallelism n Instruction Level Parallelism ( 1 instruction) VLIW, Superscalar processors n Issues: Control Flow, Data dependency, Scalability n n Thread Level Parallelism (~ 1000 instructions) Chip Multiprocessors n Issues: Limited coarse TLP, Inner cores nonoptimal n n Fine grain Parallelism (~ 50 – 1000 instructions)
Mapping Granularity Program Architecture ILP Sub-expr Cluster Fine-Grain Inner loops sub-routines MAP chip TLP Outer loops Co-routines Nodes
Fine-grain overheads Thread creation (11 cycles – hfork) n Communication n Register-Register read/writes n Message passing/on-chip cache n n Synchronization Blocking on a register (full/empty bit) n Barrier Instruction (cbar instruction) n Memory (sync bit) n
Grid Processor Architecture
Design Motivation Continued scaling of the clock rate n Scalability of the processing core n Higher ILP - Instruction throughput (IPC) n Mitigate global wire and delay overheads n Closer coupling of Architecture and compiler n
Architecture An inter-connected 2 -D network of ALU arrays n Each node has a IB and a execution unit n A single control thread maps instructions to nodes n Block-Atomic Execution Model n Mapping blocks of statically scheduled instructions n Dynamic execution in data-flow order n Forwarding temp. values to the consumer ALUs n Critical path scheduled along shortest physical path n
GPA Architecture
Example: Block-Atomic Mapping
Implementation n Instruction fetch and map n predicated hyper-block, move instructions Execution - control logic n Operand routing – max 3 dest. , split instructions n Hyper-block control n Predication (execute-all approach), cmove instructions n Block-commit n Block-stitching n
Review and Discussion
Key Ideas: Convergence n n n Microprocessor – no. of superscalar processors comm. /sync. via registers – low overheads Exploiting ILP – TLP granularities Dependency mapped to a grid of ALUs n n Replication reduces design/verification effort Point-to-point communication Exposing architecture partitioning and flow of operations to the compiler Avoid wire, routing delays, memory wall problems
Ideas: Divergence M-Machine n On-chip cache Register based mech. [Delays] n Broadcasting and Point-to-point communication GPA n Register Set Grid: Chaining [Scalability] n Point-to-point communication TERA n Fine-grain threads – Memory comm/sync (full/empty) n No support for single threaded code
Drawbacks (Unresolved Issues) M-Machine Grid Processor Arch. n Data Caches far from ALUs n Scalability n Clock speeds n Incur delays between dependent operations due n Memory to network router and wires Synchronization n Complex Frame(use hfork) management and Blockstitching n Explicit compiler dependence
Challenges/Future Directions n Architectural support to extract TLP n Parallelizing compiler technology n How many cores/threads n n No. of threads – memory latency, wire delays [Flynn] Inter-thread communication Height of Grid == 8 (IPC 5 -6) [GPA, Peter] Optimization - f(comm. , delays, memory costs)
Challenges (contd. ) n On-fly data-dependence detection (RAW/WAR) n TLP/ILP Balance – M Multi-Computer
Thanks