Miary koncentracji sektorowej w ujciu regionalnym przegld porwnawczy


 • W ciągu ostatnich 60 lat w literaturze wypracowano wiele miar")


 Miary kocentracji")
 Z perspektywy obliczeniowej istnieje kilka różnic między tymi miarami: - miary")
 • Porównanie tych miar pod względem właściwości nie jest nowością. Schmalensee")
 2) 3) 4) Wielu autorów dokonuje w rzeczywistości losowego doboru")
 Miary dla danego regionu wg branż: • Oparte")
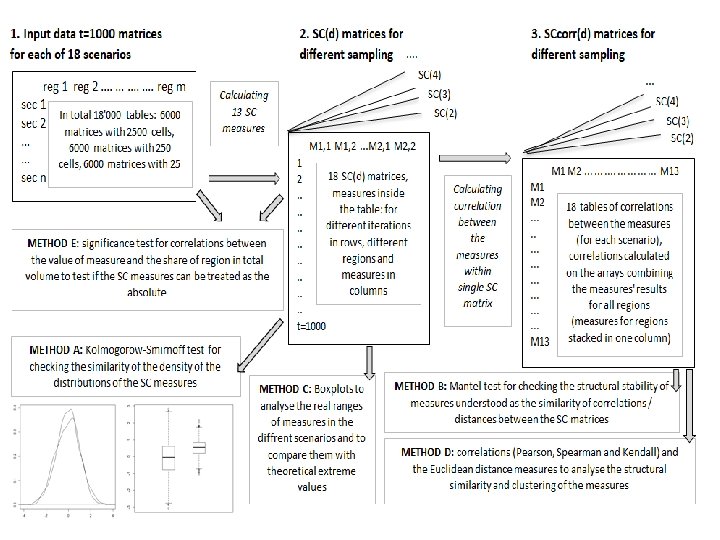
 • Każdy scenariusz ma trzy parametry: wielkość tabeli,")





 i wielkości regionu dla dużych, średnich")
 Theil, b) Gini, c) Ogive - Wrażliwość")
 1) Badanie potwierdza wrażliwość na MAUP wpływa to na decyzje dotyczące skali")
 3) Miary okazały się niezmienne względem położenia, a alokacja (matematyczna permutacja) wartości")
 5) Pojemność informacyjna działań jest podobna w niektórych grupach. należy użyć jednej")


- Slides: 24
Miary koncentracji sektorowej w ujęciu regionalnym: przegląd porównawczy i ocena oparta na symulacji Monte Carlo dr hab. Katarzyna Kopczewska Uniwersytet Warszawski Wydział Nauk Ekonomicznych
Przegląd badania • W artykule przedstawiono przegląd dostępnych miar cluster-based koncentracji geograficznej i sektorowej (nazywanych często specjalizacją) i przetestowano ich zachowanie statystyczne za pomocą zaprojektowanej symulacji Monte Carlo. • Dowodzi to, że stopień agregacji zbioru danych ma znaczenie dla wyniku, a ta wrażliwość na problem jednostki modyfikowalnej (MAUP) jest wbudowana w większość tych miar. • Pokazuje również, że dwa regiony o tej samej wewnętrznej strukturze przemysłowej, ale o różnym udziale w ogólnym wolumenie, będą miały różne wyniki koncentracji sektorowej, co jest wbrew powszechnemu poglądowi o ich absolutnym charakterze i niezależności od innych. • Wskazuje, że pojemność informacyjna miar może być taka sama, dlatego w analizach porównawczych należy dobierać miary z różnych klastrów informacyjnych. Key-words: Modifiable Areal Unit Problem (MAUP), location-invariant measures, cluster-based measures, sectoral concentration, geographical concentration, theory of measures, sample-size bias
Punkt wyjścia (1) • W ciągu ostatnich 60 lat w literaturze wypracowano wiele miar opartych na klastrach (cluster-based), które mierzą koncentrację sektorową (sectoral concentration SC) (często nazywaną specjalizacją) i koncentrację geograficzną (geograpchical concentration GC) - sa to m. indeks Giniego, indeks Krugmana, miara entropii Theila, NAI, itp. • Wszystkie opierają się na dwuwymiarowej tabeli według n sektorów (i = 1, 2, . . , n) i m regionów (j = 1, 2, . . . , m) dla danych np. o zatrudnieniu emp (ij).
Dostępne miary cluster-based
Dostępne miary cluster-based
Dostępne miary cluster-based Miary koncentracji sektorowej (rozkład aktywności między sektory w regionie) Miary kocentracji geograficznej (rozkład aktywności między regionami w sektorze) NAI, KLD, Lilien (dynamic index), Ogive index, Theil S, refined diversification index, Krugman index, Hallet index, Gini index, RSI (max LQ), Herfindahl index Relative Diversity Index (RDI) (inverse Krugman), Hachman index, Absolute Diversity Index (ADI) (inverse HH), Shannon entropy, Relative H Gini index, Krugman index, Bruhlart & Traeger index, locational Gini, Guillain & Le. Gallo (Moran I for LQ), Ellison-Glaeser index, Agglomeration V, clustering index (Bergstrand) KLD, Maurell-Sedillot index Miary ogólnej koncentracji w gospodarce Geographic concentration index, Theil total Miary dla pojedynczych „komórek” /dla sektora w regionie/ Location Quotient
Punkt wyjścia (2) Z perspektywy obliczeniowej istnieje kilka różnic między tymi miarami: - miary obliczane dla terytoriów (według sektorów) nazywane są koncentracją sektorową (często specjalizacją), ponieważ analizują rozkład sektorowy działalności gospodarczej w ramach jednego regionu; - miary obliczane dla branż (według regionów) nazywa się koncentracją geograficzną, ponieważ analizują geograficzny (międzyregionalny) rozkład działalności gospodarczej w ramach jednego przemysłu; - miary są w większości skonstruowane jako stosunek obserwowanego rozkładu aktywności do pewnego rozkładu wskaźnika, który może być empiryczny, dany przez globalne rozkłady brzegowe lub teoretyczny, z rozkładu jednostajnego (losowego); - większość miar jest obliczana dla danej branży lub danego regionu, ale można znaleźć lokalne miary dla każdej komórki (jak współczynnik lokalizacji LQ), jak również globalne, które dają jedną liczbę dla całej tabeli.
Punkt wyjścia (3) • Porównanie tych miar pod względem właściwości nie jest nowością. Schmalensee (1977) napisał 40 lat temu: "Nieskończoną liczbę alternatywnych miar koncentracji można obliczyć na podstawie typowo dostępnych danych. Dopóki korelacje nie są doskonałe, różne miary będą czasami dawać różne sygnały. Zatem w każdym konkretnym badaniu może być ważne, który z nieskończonych zestawów dostępnych środków jest wybrany, a istniejąca literatura nie dostarcza wskazówek, jak najlepiej dokonać tego wyboru". To wciąż jest prawdą, a co więcej wzrosła liczba miar. • W literaturze jest kilka przykładów porównań miar, głównie dla wskaźnika Herfindahla i innych wskaźników struktury rynku (Rosenbluth, 1955, Scherer, 1970, Bayley i Boyle, 1971, Hart, 1971, Kwoka, 1981, Sheuwaegen & Dehandschutter, 1986; Palan, 2010 r. , Latreille i Mackley, 2011 itd. ) - są one w większości empiryczne. • Istnieje również niewiele artykułów dotyczących statystycznych cech miar. Deltas (2003) pokazuje w symulacji Monte Carlo, że jednowymiarowy indeks Giniego jest obciążony w małej próbie i dowodzi, że Gini dla małej próbki jest znacznie niższy niż dla dużej. • Jednak w tej tematyce brak innych badań. Niniejszy artykuł ma wypełnić lukę teoretyczną analizą i symulacją dostępnych wskaźników koncentracji sektorowej i geograficznej.
Co należy zbadać? 1) 2) 3) 4) Wielu autorów dokonuje w rzeczywistości losowego doboru miar, które zostaną wykorzystane do porównań w swoich badaniach i w konsekwencji analizuje podobieństwa (lub różnice) wyników. Badanie ma na celu zbadanie korelacji między miarami, a tym samym podobieństwa pojemności informacyjnej. Daje wskazówkę, które miary wybrać w celu uzyskania wiarygodnych wyników, a nie podwojenia informacji. Nawet jeśli powszechnie znane są skrajne wartości miar, które stosuje się do interpretacji zjawiska, praktyka pokazuje, że wiele miar bardzo rzadko osiąga swoje ekstremalne wartości. Badanie ma na celu zbadanie zakresu, w którym najczęściej pojawiają się wyniki, co jest pomocne przy przeskalowaniu przedziałów zmienności dla interpretacji. Brak badań nad wrażliwością miar na permutację, skalę mierzonego zjawiska (średnia i odchylenie standardowe badanej zmiennej), obciążenie ze względu na wielkość próby, agregację i MAUP (problem jednostki modyfikowalnej), który wynika z liczby regionów i branż użytych do analizy. Badanie ma na celu sprawdzenie odporność wyników dla różnej agregacji danych. Literatura zakłada, że bezwzględne wartości miar są w pełni porównywalne i niezależne od innych czynników, takich jak wielkość regionu lub sektora. Badanie porównuje wyniki w różnych scenariuszach i testuje tę niezależność.
Analizowane miary – koncentracja sektorowa (SC) Miary dla danego regionu wg branż: • Oparte na rozkładzie referencyjnym empirycznym: National Averages index (NAI), Krugman Dissimilarity index, Relative Diversity index (RDI) (calculated as an inverse Krugman dissimilarity index), Hachman index, Hallet index, Kullback. Leibler Divergence (KLD), Lilien index (the dynamic one). • Oparte na rozkładzie referencyjnym jednostajnym (losowym): Shannon’s H, Theil’s H, Relative H, Ogive index and Refined Diversification index. • Oparte na rozkładzie referencyjnym empirycznym przekształconym: Gini coefficient and Relative Specialisation index (RSI) based on maximum of Location Quotient. • Bez rozkładu brzegowego, ale z wykorzystaniem liczby firm: Herfindahl index (HH) and Absolute Diversity index (ADI) (calculated as an inverse HH index).
Symulacja Monte Carlo – design (1) • Każdy scenariusz ma trzy parametry: wielkość tabeli, parametry rozkładu, rodzaj próbkowania. • Otrzymuje się dla każdego scenariusza t = 1000 iterowanych zestawów tabel danych wejściowych o różnej wielkości (n sektorów i m regionów) i właściwości danych. Dla tych tabel obliczany jest pełny zestaw (k) miar dla każdej iteracji t = 1000 dla każdego scenariusza. • Obliczane jest k = 13 miar koncentracji sektorowej w macierzy wyników SCd wielkości [iteracje, 13 x m regionów] i k = 12 miar koncentracji geograficznej w macierzy wyników GC wielkości [t iteracji, 12 x n sektorów]. Eksperyment zakłada, że scenariusze (design) D = 1, . . . d, co wygeneruje d macierzy SC i d macierzy GC.
Projekt eksperymentu statystycznego Distribution Type of sampling “Big” table m=25 regions, n=100 sectors “Middle” table m=10 regions, n=25 sectors “Small” table m=5 regions, n=5 sectors drawn t=1000 iterations aggregation of the “big” aggregation of “middle” (separate data tables) of table, irregular groups 25 100=2500 cells of regions and sectors N 1( ∊(0, 50), ∊(0, 25)) Double randomisation Scheme 1 Scheme 7 Scheme 13 N 1( ∊(0, 50), ∊(0, 25)) Single randomisation Scheme 2 Scheme 8 Scheme 14 N 1( ∊(0, 50), ∊(0, 25)) Permutation Scheme 3 Scheme 9 Scheme 15 N 2( ∊(0, 500), ∊(0, 100)) Double randomisation Scheme 4 Scheme 10 Scheme 16 N 2( ∊(0, 500), ∊(0, 100)) Single randomisation Scheme 5 Scheme 11 Scheme 17 N 2( ∊(0, 500), ∊(0, 100)) Permutation Scheme 6 Scheme 12 Scheme 18
Boxplot dla miar S. C. dla dużych, średnich i małych tabel - Różna wariancja - Różna skala zmienności miar - Sample-size bias (obciążenie ze względu na wielkość próby)
Korelacje miar SC wyniki dla podwójnej randomizacji i rozkładu N 1 Big table Middle table Small table - Wzorce grupowe - Efekty agregacji - Różna wrażliwość na agregację
Test Mantela dla korelacji Pearsona i odległości Eulidesowej miar SC testowanie znaczenia agregacji (dla danego DGP – rozkład i losowanie) Hypothesis H 1 MAUP H 1 MAUP Triple comparison of matrices* (big, middle, small) for the same drawing scheme N 1. DR. (1, 7, 13) N 1. SR. (2, 8, 14) N 1. P. (3, 9, 15) N 2. DR. (4, 10, 16) N 2. SR. (5, 11, 17) N 2. P. (6, 12, 18) Patrial Mantel test (and pvalue) for Pearson correlation 0. 945 (0. 001) 0. 947 (0. 001) 0. 945 (0. 001) 0. 944 (0. 001) 0. 788 (0. 001) 0. 944 (0. 001) Partial Mantel test (and pvalue) for Euclidean distance 0. 560 (0. 085) 0. 566 (0. 087) 0. 576 (0. 086) 0. 396 (0. 096) 0. 373 (0. 101) 0. 397 (0. 086) Dual comparison of extreme matrices (big, small) N 1. DR. (1, 13) N 1. SR. (2, 14) N 1. P. (3, 15) N 2. DR. (4, 16) N 2. SR. (5, 17) N 2. P. (6, 18) Mantel test (and p-value) for Pearson for Euclidean correlation distance 0. 574 (0. 002) 0. 648 (0. 001) 0. 614 (0. 001) 0. 546 (0. 001) 0. 248 (0. 029) 0. 543 (0. 001) -0. 015 (0. 150) -0. 022 (0. 146) -0. 019 (0. 153) 0. 037 (0. 155) 0. 055 (0. 158) 0. 028 (0. 159) - Utrata podobieństwa macierzy miar po agregacji danych – wrażliwość na MAUP
Korelacje Persona pomiędzy miarami SC i wielkością regionu - Miary nie są niezależne od wielkości regionu
Korelacje miar SC (Krugman dissimilarity i Gini index) i wielkości regionu dla dużych, średnich i małych tabel
Rozkładu miar SC dla różnych schematów a) Theil, b) Gini, c) Ogive - Wrażliwość na MAUP i skalę agregacji – należy porównywać miary dla tej samej skali agregacji
Wnioski (1) 1) Badanie potwierdza wrażliwość na MAUP wpływa to na decyzje dotyczące skali agregacji zbioru danych Wielkość tabeli danych (liczba sektorów i regionów) ma znaczenie dla wartości miar SC (podobne wyniki w dużych tabelach, wysoka czułość w mniejszych tabelach) potwierdza to istnienie błędu wielkości próby, udowodnione przez Deltas (2003). 2) Miary SC są niewrażliwe na skalę i zmienność danych wejściowych. Jednostka pomiaru nie ma znaczenia w analizach porównawczych.
Wnioski (2) 3) Miary okazały się niezmienne względem położenia, a alokacja (matematyczna permutacja) wartości nie ma znaczenia dla ogólnego wyniku. Potwierdza to jej słabą reakcję na nieregularne wzorce lokalizacji firmy i zmiany we wzorcu lokalizacji. 4) "Rzeczywiste" przedziały wartości nie pokrywają się z oczekiwanymi teoretycznymi zakresami Nie należy zakładać, że miara osiągnie wartość ekstremalną (min. lub maks. ), a także że przedziały interpretacyjne muszą być dostosowane do rzeczywistej zmienności miary.
Wnioski (3) 5) Pojemność informacyjna działań jest podobna w niektórych grupach. należy użyć jednej miary z grupy określonej przez rozkład referencyjny, ponieważ reszta jest skorelowana. Te grupy to i) oparte na empirycznym rozkładzie wskaźnika, ii) oparte na losowym rozkładzie wskaźnika, iii) oparte na transformowanym rozkładzie empirycznym, iv) bez brzegowego rozkładu. 6) Nie można traktować wartości miar jako absolutne, ponieważ są zależne od agregacji (zależne od rozmiaru tabeli danych) i zewnętrznie skorelowane z pozycją analizowanego regionu. nie są w pełni porównywalne między przypadkami nie są niezależne od innych czynników i cech regionów / sektorów, np. udział w regionie / sektorze w ogólnej wielkości.
Więcej w książce…
DZIĘKUJĘ ZA UWAGĘ!