METODA POTPORNIH VEKTORA Metoda potpornih vektora eng Supportvector

 je jedna od metoda mašinskog učenja koja se")



")

 uz")



 između dva cilja")


")
, d=2 (kvadratni")


- Slides: 22
METODA POTPORNIH VEKTORA
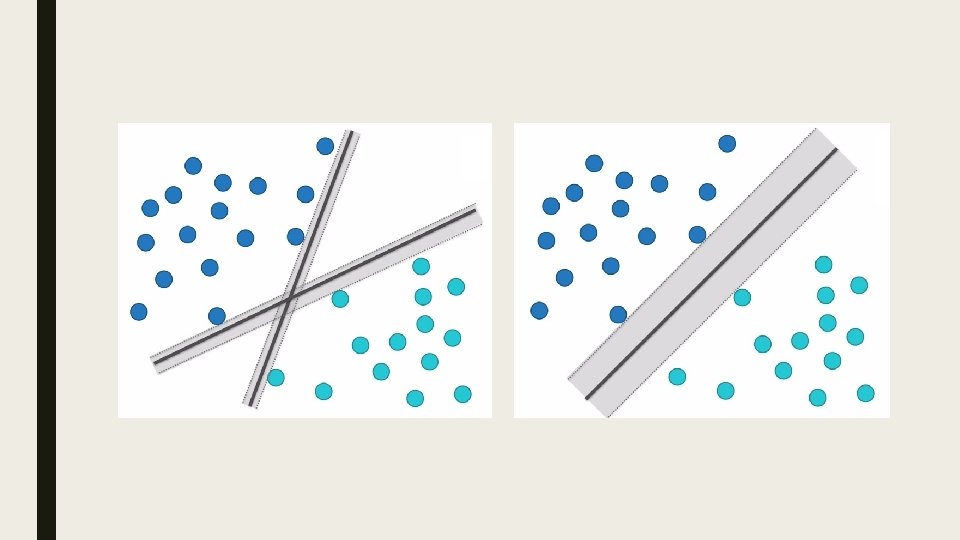
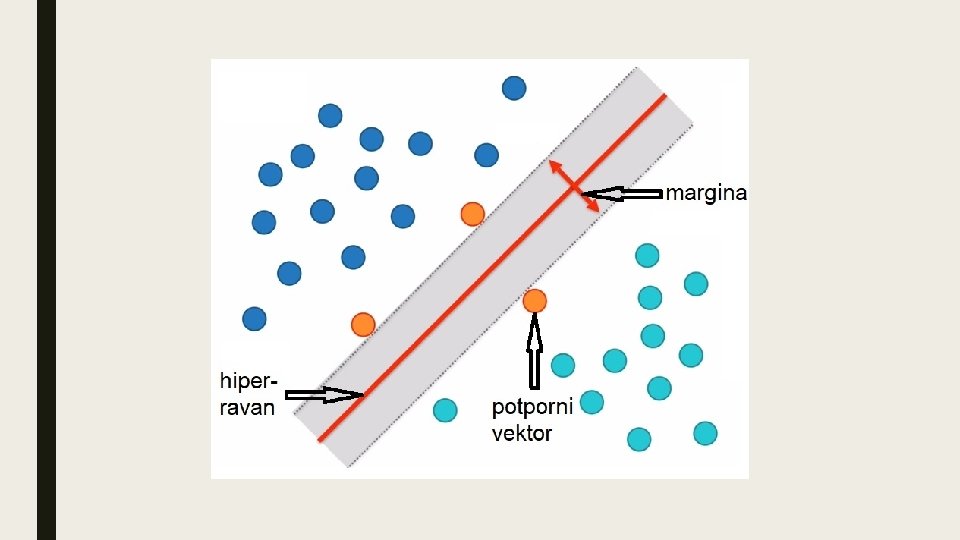
Metoda potpornih vektora (eng. Support-vector machine) je jedna od metoda mašinskog učenja koja se koristi u pronalaženju skrivenog znanja (data mining) čiji je cilj da se nadgledanim učenjem na trening primerima kreira model koji će pravilno kategorizovati nove primere. To se postiže konstrukcijom hiperravni u slučaju binarne klasifikacije (ili skupa hiperravni u slučaju višeklasne klasifikacije) u višedimenzionalnom prostoru ulaznih vektora (trening primera) koja ima najveću moguću udaljenost (marginu) od najbližih trening podataka različitih klasa, čime se postiže smanjenje greške generalizacije.
Primer: Napraviti model mašinskog učenja koji prepoznaje da li je na slici pudla ili mačka (da nove sličice pravilno klasifikuje), pri čemu je na x 1 osi dužina njuške, a na x 2 osi dužina repa.
Optimizacioni problem kod metode potpornih vektora trening skup od n tačaka: hiperravan razdvajanja je skup tačaka koje zadovoljavaju jednačinu: odstojanje hiperravni od koordinatnog početka duž vektora normale na hiperravan razdvajanja
Npr. neka je hiperravan prava: tj. b=2
Uloga metode potpornih vektora je da nađe jednačine dve paralelne hiperravni (njihovo i b) koje razdvajaju dve klase podataka, takve da je rastojanje među njima najveće moguće. Oblast između te dve ravni se naziva “margina”, a hiperravan sa najvećom marginom leži na pola puta između te dve granične hiperravni. Za binarni klasifikator, jednačina gornje hiperravni koja naleže na potporne vektore iz klase y=+1 (jedna granica puta) je: a sve tačke na njoj ili iznad nje se klasifikuju kao +1. Jednačina druge hiperravni koja naleže na potporne vektore iz klase y=-1 (druga granica puta): a sve tačke na njoj ili ispod nje se klasifikuju kao -1.
Širina margine je
Optimizacioni problem: naći maksimum margine (što se pogodnije svede na minimizovanje funkcije ) uz uslov da su svi podaci pravilno klasifikovani: tj. prikazano kao jedan uslov Ovakav optimizacioni problem – traženje i b koji određuju naš klasifikator minimizacijom kvadratne funkcije uz linearna ograničenja (nejednakosti) se matematički rešava pomoću Lagranžovih multiplikatora.
Tražimo optimum:
Meka margina Funkcija gubitka: Linearno neseparabilni problem
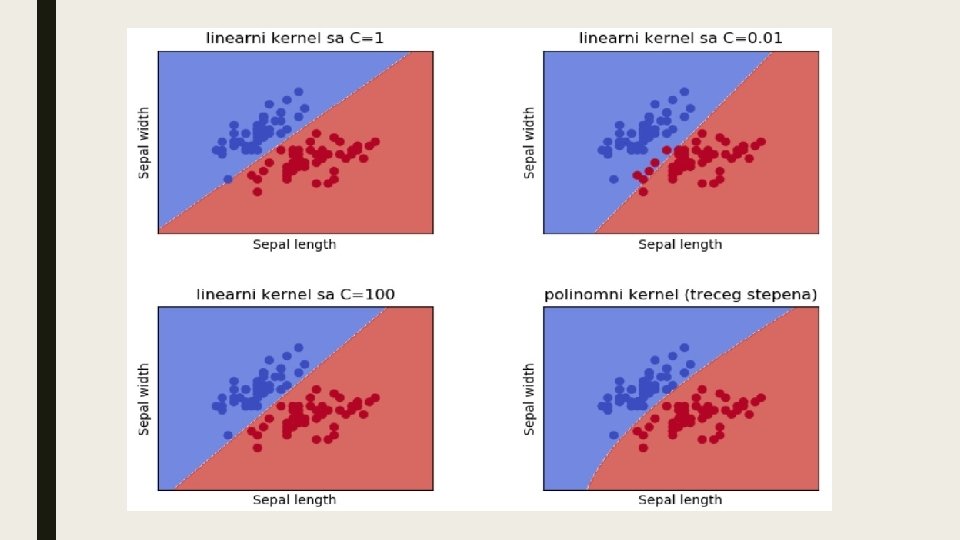
Funkcija greške procenjuje kvalitet modela mašinskog učenja koji je nastao primenom metode potpornih vektora i ona mora da uzme u obzir dva suprotstavljena cilja optimizacije: što šira margina (bolja generalizacija za nove, neviđene podatke) i što veća tačnost klasifikacije pojedinačnih podataka (obezbeđivanja da leži sa prave strane margine): uz uslov
Parametar C je hiperparametar modela čijim se podešavanjem vrši balansiranje (trgovina) između dva cilja optimizacije (bias/variance tradeoff koji se javlja kod svih modela mašinskog učenja).
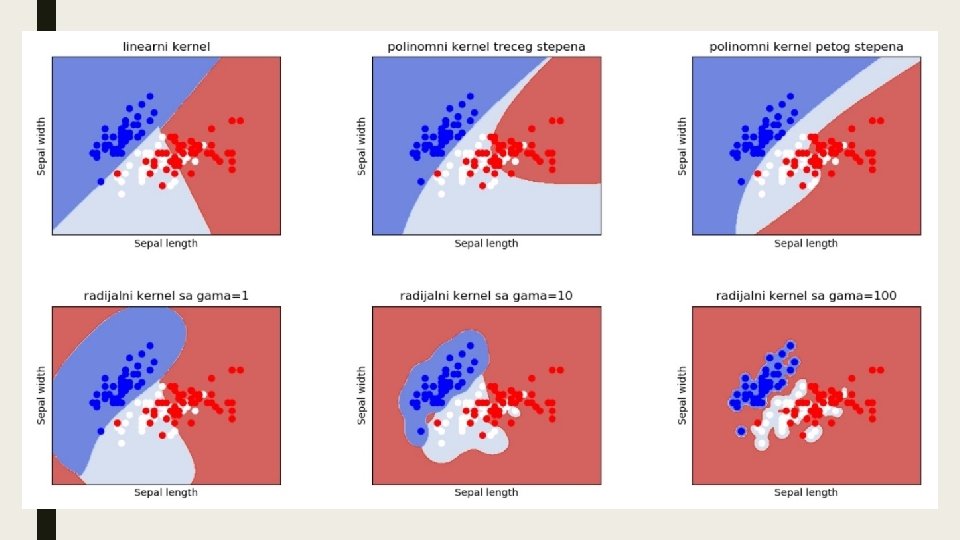
Nelinearna klasifikacija i kerneli
Kernel funkcije Izraz za dualnu reprezentaciju: Rešenje za smanjenje računskog vremena je tzv. “kernel trik” kod koga se koriste posebne, kernel funkcije koje za zadate vektore implicitno računaju njihov skalarni proizvod u nekom prostoru sa više dimenzija, bez da te vektore prethodno eksplicitno transformišu u taj prostor. Kernel funkcija: Dualna reprezentacija:
Najčešće kernel funkcije: Linearna Polinomna Radijalna (RBF-radial basis function)
Primer: Tražimo funkciju preslikavanja za polinomni kernel sa parametrima: m=2 (broj osobina), d=2 (kvadratni kernel), c=0, Računamo kernel funkciju za dva podatka (dvodimenzionalna (m=2) vektora)
Višeklasna klasifikacija Problem višeklasne klasifikacije se razbija na više binarnih klasifikacija. Postoje dva moguća pristupa za razlaganje problema klasifikacije sa k klasa: 1. “jedan protiv svih” (OVR: One vs Rest) – problem se razbija na k binarnih klasifikatora tako što se kreira po jedan binarni klasifikator (hiperravan razdvajanja) za svaku od klasa koji razdvaja tu klasu od svih ostalih klasa. Novi podatak se svrstava u onu klasu čiji binarni klasifikator klasifikuje dati podatak u tu klasu sa najvećom udaljenošću između njegove hiperravni razdvajanja i podatka. 2. “svako protiv svakog” (OVO: One vs One) – problem se razbija na binarnih klasifikatora tako što se kreira po jedan binarni klasifikator (hiperravan razdvajanja) između svake dve postojeće klase. Novi podatak se svrstava sistemom glasanja pri čemu svaki od klasifikatora svrstava novi podatak u jednu od dve klase - daje toj klasi jedan glas.
Prednosti i nedostaci Prednosti: -u celini jedna od najboljih metoda mašinskog učenja, primenjiva za širok spektar problema -dobro se snalazi sa višedimenzionalnim podacima -uspešan je i sa malim skupom trening podataka -metoda generalno nije sklona overfitting-u -na položaj hiperravni utiču jedino potporni vektori koje metoda sama pronalazi Nedostaci: -za velike skupove podataka trening traje dugo, kerneli dodatno usporavaju -odabir hiperparametara sa kojima se postiže dobra generalizacija može biti komplikovan -selekcija odgovarajuće kernel funkcije zavisi od konkretnog zadatka i može biti problematična