Measures of Dispersion Variance and Standard Deviation Basic

Measures of Dispersion Variance and Standard Deviation

Basic Assumptions about Distributions • We should be able to plot the number of times a specific value occurs on a graph using a line chart or histogram (interval/ratio data) • Some distributions will be normal or bell-shaped. • Some distributions will be bi-modal or will have data points distributed irregularly. • Some distributions will be skewed to the right or skewed to the left. • Theoretically, samples taken from one population, should over time, approximate a normal distribution. • We should have a normal distribution if we are to use inferential statistics.

Other reasons to use Measures of Dispersion • To see if variables taken from two or more samples are similar to one another. • To see if a variable taken from a sample is similar to the same variable taken from a population – in other words is our sample representative of people in the population at least on that one variable.

Variation in Two Samples Sample 1 Sample 2 1 2 3 3 4 4 5 6 7 Mo = 4 Mdn = 4 Mean = 4 5 7 9 9 10 Mo, 3, 9 Mdn = 6 Mean = 6
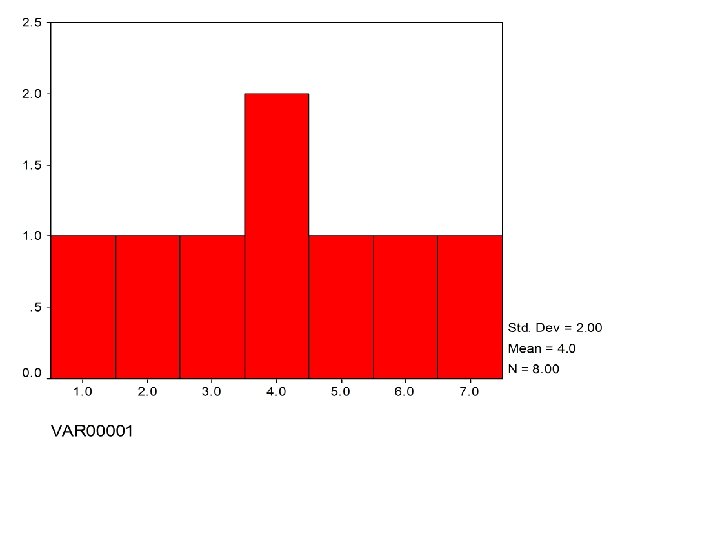

Sample 2

Normal Distributions are Bellshaped and have the same number of measures on either side of the mean. Note: According to Montcalm & Royse only unimodal distributions can be normal distributions.
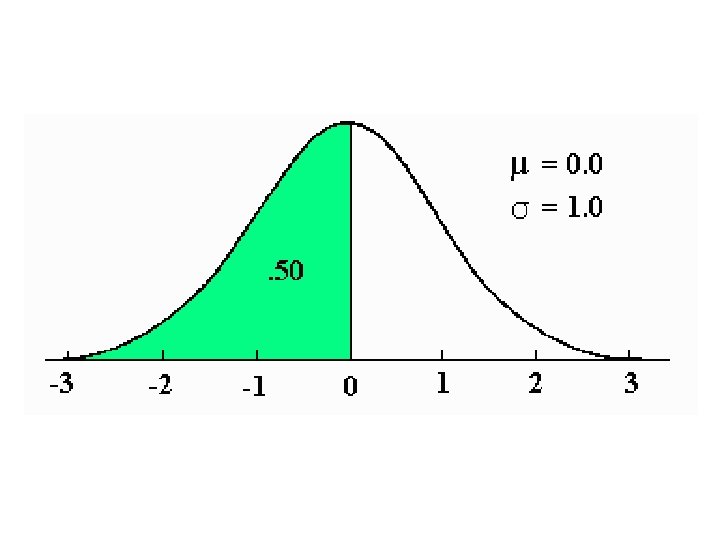

Normal Distributions • 50% of all scores are on either side of the mean. • The distribution is symmetrical – same number of scores fall above and below the mean. • The mean is the midpoint of the distribution. • Mean = median = mode • The entire area under the bell-shaped curve = 100%.

A standard deviation is: • The degree to which each of the scores in a distribution vary from the mean. (x – mean) • Calculated by squaring the deviation of each score from the mean. • Based on first calculating a statistic called the variance.
")
Formulas are: • Variance = Sum of each deviation squared divided by (n -1) where n is the number of values in the distribution. • Standard Deviation = the square root of the sum of squares divided by (n – 1).
 = -3 9 Mean")
Using Sample 1 as an example 1 Total (1 -4) = -3 9 Mean = 4 2 (2 -4) = -2 4 3 (3 -4) = -1 1 4 (4 -4) = 0 0 Variance S. D. 4 (4 -4) = 0 0 28/(8 -1) Sq Root 4 5 (5 -4) = 1 1 6 (6 - 4) = 2 4 7 (7 = 4) = 3 9 0 28 4 2

Another variance/SD example 1 -5. 00 25. 00 Mean = 6 2 -4. 00 16. 00 4 -2. 00 4. 00 8 2. 00 4. 00 10 4. 00 Variance = 90/(6 SD = sq root of 16. 00 -1) 18 11 5. 00 25. 00 0. 00 90. 00 Total 18. 00 4. 24

Other Important Terms in This Chapter • Mean squares – the average of squared deviations from the mean in a set of numbers. (Same as variance) • Interquartile range – points in a set of numbers that occur between 75% of the scores and 25% of the scores – that is, where the middle 50% of all scores lie (use cumulative percentages) • Box plot – gives graphic information about minimum, maximum, and quartile scores in a distribution.

Box Plot

Interquartile Range Test Scores Frequency 100 3 Cumulative Percent 25% 100% 90 3 25% 75% 80 3 25% 50% 70 1 8. 3% 25% 60 2 16. 7% 12 100. 0% Total Percent

This information is important to our discussion of normal distributions
 specifies that: • 50%")
Central Limit Theorem (we will discuss this in two weeks) specifies that: • 50% of all scores in a normal distribution are on either side of the mean. • 68. 25% of all scores are one standard deviation from the mean. • 95. 44% of all scores are two standard deviations from the mean. • 99. 74% of all scores in a normal distribution are within 3 standard deviations of the mean.

Therefore, we will be able to • Predict what scores are contained within one, two, or three standard deviations from the mean in a normal distribution. • Compare the distribution of scores in samples. • Compare the distribution of scores from populations to samples.

To calculate measures of central tendency and dispersion in SPSS • • Select descriptive statistics Select descriptives Select your variables Select options (mean, sd, etc. )

SPSS output
- Slides: 21