Massimo Lamanna for the SCOD team WLCG REPORT
 WLCG REPORT 9/18/2020 WLCG MB Report WLCG Service")
")
 VO User Team Alarm Total ALICE 4 2 0 6")


















- Slides: 22
Massimo Lamanna (for the SCOD team) WLCG REPORT 9/18/2020 WLCG MB Report WLCG Service Report 1
Summary • Highlights: • • NDGF incidents (data loss due to disk firmware upgrade) RAL power cut (promptly recovered) ASGC tape provisions replenished CERN • Data management: • unavailability as a consequence of a disk(server) failure (momentary file unavailability) • Batch: • LSF problems. Recurrent slow response (affecting mainly ATLAS) and some issues with efficient usage of available resources (not getting all the available job slots) • Many thanx to Mike Kenyon and Maria Dimou for the material 9/18/2020 WLCG MB Report WLCG Service Report 2
GGUS summary (5 weeks) VO User Team Alarm Total ALICE 4 2 0 6 ATLAS 18 164 5 187 CMS 18 8 3 29 LHCb 13 39 0 52 Totals 53 213 8 274 120 Total ALICE Total ATLAS Total CMS 100 Total LHCb 80 60 40 20 0 27 -Jun 13 -Jan 1 -Aug 17 -Feb 5 -Sep 24 -Mar 10 -Oct 27 -Apr 13 -Nov 1 -Jun
Support-related events since last MB • There have been 8 real ALARMs since the 2012/10/16 MB. • 3 were submitted by CMS and 5 by ATLAS. • 1 concerned IN 2 P 3, the rest the CERN site. • A GGUS Release took place since the last MB (on 2012/10/28). All ALARM tests were successful (operators received notification, reacted within minutes, interfaces worked, experts closed promptly). • Detailed analysis in https: //savannah. cern. ch/support/? 132626#comm ent 6 9/18/2020 WLCG MB Report WLCG Service Report 4
CMS ALARM->CERN JOB FAILURE DUE TO CASTORGGUS: 87382 What time UTC What happened 2012/10/16 07: 50 GGUS TEAM ticket opened, automatic email notification to grid-cern-prod-admins@cern. ch AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: Storage Systems. 2012/10/16 08: 11 Monitoring shows all is normal but files are NOT transferred from P 5. Ticket upgraded to ALARM. Email sent to cms-operator-alarm@cern. ch. 2012/10/16 08: 23 The service manager started investigation immediately, while operators record in the ticket that “the CASTOR piquet was called”. 2012/10/16 13: 17 Ticket set to ‘solved’ after 8 comments’ exchange, mainly names of files stuck at P 5 to help debugging. The solution contained no explanation. Possible cause: Diskserver draining (Many small files) with unstable DB instance. ‘verified’ the next day. WLCG MB Report WLCG Service Report 5 9/18/2020
ATLAS ALARM->IN 2 P 3 SRM UNREACHABLEGGUS: 87872 What time UTC What happened 2012/10/29 04: 40 GGUS TEAM ticket opened, automatic email notification to grid. admin@cc. in 2 p 3. fr AND automatic assignment to NGI_FRANCE. Type of Problem: Storage Systems. 2012/10/29 07: 49 After 2 comments by the shifter noting that all T 0 exports fail, the ticket is upgraded into an ALARM. Email sent to lhc-alarm@cc. in 2 p 3. fr. 2012/10/29 13: 27 Ticket set to ‘solved’ by the service manager after 4 comments’ exchange and a restart of the SRM server at 8: 35 CEST. 2012/10/29 13: 45 Ticket set to ‘verified’ by an ATLAS supporter. 9/18/2020 WLCG MB Report WLCG Service Report 6
ATLAS ALARM->CERN CASTOR DATA INACCESSIBLEGGUS: 88064 What time UTC What happened 2012/11/02 09: 40 GGUS ALARM ticket opened, automatic email notification to atlas-operator-alarm@cern. ch AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: File Access. 2012/11/02 09: 42 Service expert takes ownership of the ticket and comments that all examples of inaccessible files are on a diskserver having a controller problem. 2012/11/02 09: 45 Operator records in the ticket that CASTOR piquet was called. 2012/11/05 10: 46 Ticket set to ‘solved’, all files accessible again, after 7 comments exchanged. Vendor needed a number of days to run tests. Experiment required a solution within hours. Service expert explained what can be realistically expected given the tests’ length and the vendor’s working hours’ agreement. WLCG MB Report WLCG Service Report 7 9/18/2020
ATLAS ALARM->CERN SLOW LSF GGUS: 88275 What time UTC What happened 2012/11/07 11: 40 GGUS TEAM ticket opened, automatic email notification to grid-cern-prod-admins@cern. ch AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: Local Batch Systems. 2012/11/07 12: 18 Service expert confirms LSF is slow at times but the reason is not yet understood. 2012/11/07 13: 52 Submitter attaches multiple plots showing the great amount of pending jobs and converts the ticket into an ALARM. Email to atlas-operator-alarm@cern. ch sent. 2012/11/07 14: 12 Operator confirms ALARM reception. 2012/11/14 15: 26 Ticket set to status ‘solved’ after 20 comments’ exchange, from which no real cause of the problem was identified. While doing these drills service and experiment agreed with our suggestion to close this ALARMMBand open. WLCG a TEAM ticket for long-term WLCG Report Service Report 8 investigation. 9/18/2020
ATLAS ALARM->CERN SLOW LSF GGUS: 88493 What time UTC What happened 2012/11/14 15: 38 GGUS TEAM ticket opened as agreed in the previous slide , automatic email notification to grid-cern-prodadmins@cern. ch. AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: Local Batch Systems. 2012/11/14 20: 19 Submitter sees a great service degradation, attaches proving plots & copies the operators in this comment, who suggests to contact the service directly. 2012/11/14 21: 30 Submitter attaches multiple plots showing the great amount of pending jobs and converts the ticket into an ALARM. Email to atlas-operator-alarm@cern. ch sent. 2012/11/14 21: 36 Operator confirms ALARM reception and forward to it-dep-pesps. 2012/11/15 07: 32 Expert confirms the problem is back and investigation is ongoing. 19 comments were exchanged throuhout Thu and Fri. No weekend activity. Reasons are >1, including the WLCG MB Reportjob. WLCG Service submission of 100 k at once by a. Report single user. Still ‘in 9 9/18/2020
CMS ALARM->CERN JOB FAILURE DUE TO CASTORGGUS: 88507 What time UTC What happened 2012/11/15 00: 26 GGUS TEAM ticket opened, automatic email notification to grid-cern-prod-admins@cern. ch AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: File Access. 2012/11/15 00: 33 Ticket upgraded to ALARM. Email sent to cmsoperator-alarm@cern. ch. 13 mins later operator confirms that CASTOR piquet was called. 2012/11/15 00: 51 The service manager (mgr) started investigation immediately (in 3 mins). 2012/11/15 01: 23 Ticket set to ‘solved’ after 6 comments’ exchange. Service mgr found a lot o load on the headnodes, xrootd daemons were restarted. 9/18/2020 WLCG MB Report WLCG Service Report 10
ATLAS ALARM->CERN CASTOR DISKSERVERGGUS: 88528 What time UTC What happened 2012/11/15 16: 59 GGUS ALARM ticket opened, automatic email notification to atlas-operator-alarm@cern. ch AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: File Access. 2012/11/15 17: 08 Service expert checking the server is up but has a RAID controller problem. 2012/11/15 17: 21 Operator confirms ALARM reception and forwards to CASTOR piquet. Meanwhile the expert set the host out of production 2012/11/16 05: 28 Expert observes an interrupt in the file draining. Submitter confirms all necessary files are accessible for ATLAS users. 2012/11/16 21: 56 The service manager confirms the file drain did complete correctly and set the ticket to status ‘solved’. 9/18/2020 WLCG MB Report WLCG Service Report 11
CMS ALARM->CERN JOBS QUEUEING GGUS: 88530 What time UTC What happened 2012/11/15 20: 40 GGUS TEAM ticket opened, automatic email notification to grid-cern-prod-admins@cern. ch AND automatic assignment to ROC_CERN. Automatic SNOW ticket creation successful. Type of Problem: Local Batch System. 2012/11/15 21: 13 Ticket upgraded to ALARM. Email sent to cmsoperator-alarm@cern. ch. 16 mins later operator confirms ticket was sent to it-dep-pes-ps-sms. 2012/11/15 00: 33 The submitter offered various status plots showing the degradation of job submission rate per queue. Service expert forced a LSF reconfiguration normally planned for the next morning. 2012/11/19 08: 02 Ticket set to ‘solved’ after 13 comments’ exchange during the night of 15 -16 Nov. Solution was an LSF reconfiguration. 9/18/2020 WLCG MB Report WLCG Service Report 12
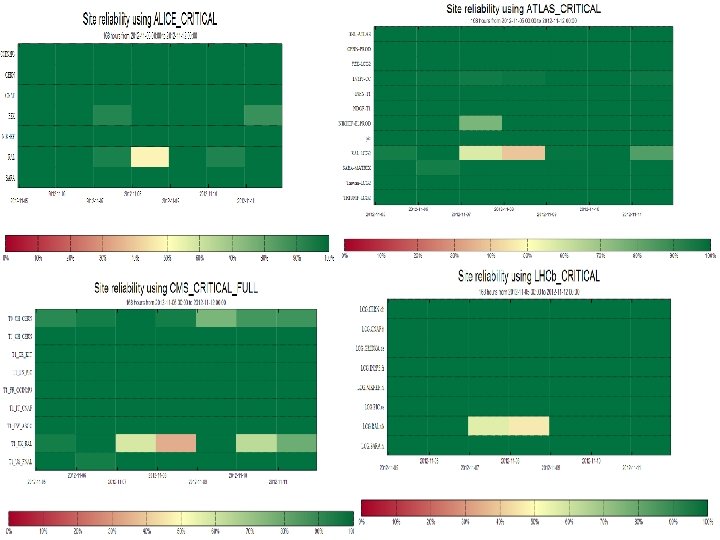
Analysis of the reliability plots : Week 22/10/2012 • • ALICE : – ATLAS : – – CMS : – – LHCb : – – UNSCHEDULED 1. 1: RAL-LCG 2: 24/10: downtime for the migration to EMI-2 CREAM. 2. 1: RAL-LCG 2: 24/10: downtime for the migration to EMI-2 CREAM. 2. 2: pic: 25 -26/10: org. atlas. WN-swtag test failing due to “valid credentials could not be found”. 3. 1: KIT: 22/10: new CREAM-CEs have been added. 3. 2: FNAL: 22/10: there was a 6 hrs period when the org. sam. CE-Job. Submit tests were failing. 4. 1: 23 -24/10: Proxy used for SAM/Nagios test submission expired. It has been renewed. 4. 2: RAL-LCG 2: 22/10: downtime for the migration to EMI-2 CREAM.
1. 1 2. 2 2. 1 3. 2 4. 1 4. 2 4. 1 2. 2
Analysis of the reliability plots : Week 15/10/2012 • Alice : NTR UNSCHEDULED • • • Atlas : – CMS : – – – 2. 1 IN 2 P 3 : CREAMCE – intermittent failures of the Job. Submit test. Transfer to CREAM failed due to authorization exception. 3. 1 CERN : SRM – failures of the VOPut test, CASTOR issue, see GGUS 3. 2 KIT : CREAMCE – Job. Submit test timing out 3. 3 IN 2 P 3 : CREAMCEs are not running the WN-xrootd. access test. Unavailability of these test results are affecting reliability of the whole site. The cause is being investigated by CMS experts. It has been agreed that this test should pass in OSG sites, but other sites may fail it. LHCb : NTR
2. 1 3. 2 3. 3 2. 1
Analysis of the reliability plots : Week 29/10/2012 • ALICE UNSCHEDULED • 1. 1: FZK 31/10 CREAMCE-Job. Submit test failing on cream-4 & 5; CEs not in downtime. • ATLAS • 2. 1: FZK 31/10 CREAMCE-Job. Submit test failing on cream-4 & 5; CEs not in downtime. • CMS • Nothing to report. • LHCb • Nothing to report.
2. 1 1. 1 2. 1
Analysis of the reliability plots : Week 05/11/2012 • All VOs: 1. 07/11/2012: RAL affected by site-wide power loss from 1130 UTC. UNSCHEDULED
Analysis of the reliability plots : Week 12/11/2012 • ALICE: Nothing to report UNSCHEDULED • ATLAS: • 1. 1: 17/11/2012 INFN: Intermittent failure of SRM-VO Put/Get/Del tests against storm-fe. cr. cnaf. infn. it endpoint. • CMS: Nothing to report • LHCb: Nothing to report
1. 1