Markov chain Monte Carlo with people Tom Griffiths





|x(t)) • Variables x(t+1)")
 by constructing Markov")

")
 Step 1: propose a state")
")
")
")
 A(x(t), x(t+1)) = 0. 5")
")
 A(x(t), x(t+1)) = 1")

 What are the consequences of learners learning from other learners?")
 PP(d|h) PL(h|d): probability of inferring hypothesis h from data d")
 PP(d|h) Assume learners sample from their posterior distribution:")
 h 1 PP(d|h) d 1 PL(h|d) h 2")
 • Markov")
 PP(d|h) • Intuitively: data acts once, prior many")
 • Participants see stimuli, then reproduce them from memory •")
")



")
")
 E present (e+) E absent (e-)")

")
")
 four iterated learning chains one independent learning “chain” (Yeung")
")
")
")
 • Reproduction from")

")












")

 Giraffes are distinguished by neck length, body height and")

")




- Slides: 63
Markov chain Monte Carlo with people Tom Griffiths Department of Psychology Cognitive Science Program University of California, Berkeley
Two deep questions • What are the biases that guide human learning? – prior probability distribution P(h) • What do mental representations look like? – category distribution P(x|c)
Two deep questions • What are the biases that guide human learning? – prior probability distribution on hypotheses, P(h) • What do mental representations look like? – distribution over objects x in category c, P(x|c) Develop ways to sample from these distributions
Outline Markov chain Monte Carlo Sampling from the prior (with Mike Kalish, Steve Lewandowsky, Saiwing Yeung) Sampling from category distributions (with Adam Sanborn)
Outline Markov chain Monte Carlo Sampling from the prior (with Mike Kalish, Steve Lewandowsky, Saiwing Yeung) Sampling from category distributions (with Adam Sanborn)
Markov chains x x x x Transition matrix T = P(x(t+1)|x(t)) • Variables x(t+1) independent of history given x(t) • Converges to a stationary distribution under easily checked conditions (i. e. , if it is ergodic)
Markov chain Monte Carlo • Sample from a target distribution P(x) by constructing Markov chain for which P(x) is the stationary distribution • Two main schemes: – Gibbs sampling – Metropolis-Hastings algorithm
Gibbs sampling For variables x = x 1, x 2, …, xn and target P(x) Draw xi(t+1) from P(xi|x-i) x-i = x 1(t+1), x 2(t+1), …, xi-1(t+1), xi+1(t), …, xn(t)
Gibbs sampling (Mac. Kay, 2002)
Metropolis-Hastings algorithm (Metropolis et al. , 1953; Hastings, 1970) Step 1: propose a state (we assume symmetrically) Q(x(t+1)|x(t)) = Q(x(t))|x(t+1)) Step 2: decide whether to accept, with probability Metropolis acceptance function Barker acceptance function
Metropolis-Hastings algorithm p(x)
Metropolis-Hastings algorithm p(x)
Metropolis-Hastings algorithm p(x)
Metropolis-Hastings algorithm p(x) A(x(t), x(t+1)) = 0. 5
Metropolis-Hastings algorithm p(x)
Metropolis-Hastings algorithm p(x) A(x(t), x(t+1)) = 1
Outline Markov chain Monte Carlo Sampling from the prior (with Mike Kalish, Steve Lewandowsky, Saiwing Yeung) Sampling from category distributions (with Adam Sanborn)
Iterated learning (Kirby, 2001) What are the consequences of learners learning from other learners?
Analyzing iterated learning PL(h|d) PP(d|h) PL(h|d): probability of inferring hypothesis h from data d PP(d|h): probability of generating data d from hypothesis h
Iterated Bayesian learning PL(h|d) PP(d|h) Assume learners sample from their posterior distribution:
Analyzing iterated learning d 0 PL(h|d) h 1 PP(d|h) d 1 PL(h|d) h 2 PP(d|h) d 2 PL(h|d) h 3 A Markov chain on hypotheses h 1 d PP(d|h)PL(h|d) h 2 d PP(d|h)PL(h|d) h 3 A Markov chain on data d 0 h PL(h|d) PP(d|h) d 1 h PL(h|d) PP(d|h) d 2 h PL(h|d) PP
Stationary distributions • Markov chain on h converges to the prior, P(h) • Markov chain on d converges to the “prior predictive distribution” (Griffiths & Kalish, 2005)
Explaining convergence to the prior PL(h|d) PP(d|h) • Intuitively: data acts once, prior many times • Formally: iterated learning with Bayesian agents is a Gibbs sampler on P(d, h) (Griffiths & Kalish, 2007)
Serial reproduction (Bartlett, 1932) • Participants see stimuli, then reproduce them from memory • Reproductions of one participant are stimuli for the next • Stimuli were interesting, rather than controlled – e. g. , “War of the Ghosts”
Iterated function learning data hypotheses • Each learner sees a set of (x, y) pairs • Makes predictions of y for new x values • Predictions are data for the next learner (Kalish, Griffiths, & Lewandowsky, 2007)
Function learning experiments Stimulus Feedback Response Slider Examine iterated learning with different initial data
Initial data Iteration 1 2 3 4 5 6 7 8 9
Iterated predicting the future data A movie has made $30 million so far hypotheses $60 million total • Each learner sees values of t • Makes predictions of ttotal • The next value of t is chosen from (0, ttotal) (Lewandowsky, Griffiths & Kalish, 2009)
Movie grosses Poems ttotal Chains of predictions Iteration (Lewandowsky, Griffiths & Kalish, 2009)
Stationary distributions (Lewandowsky, Griffiths & Kalish, 2009)
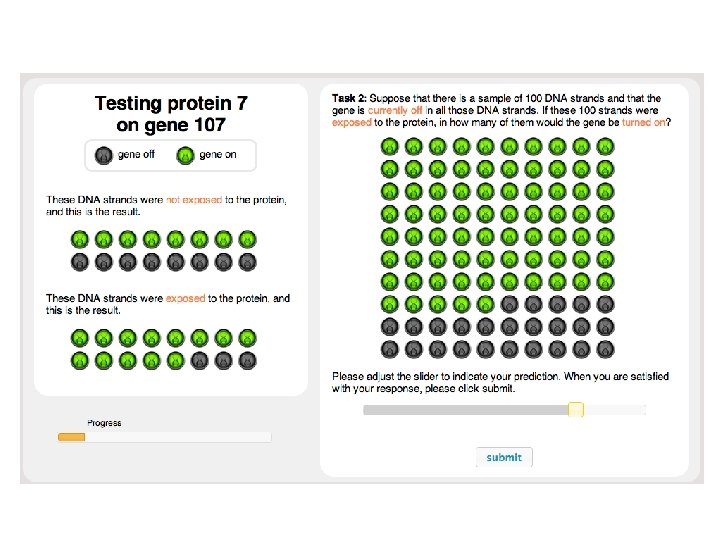
Iterated causal learning hypotheses data C present (c+) E present (e+) E absent (e-) C absent (c-) w 0 w 1 • Each trial shows contingency data • Elicits estimates of w 0 and w 1 • Data on next trial sampled with these values (Yeung & Griffiths, in press)
Eliciting strength judgments Generative: “Of 100 people who did not express the effect, how many would express the effect in presence of the cause? ” Preventive: “Of 100 people who expressed the effect, how many would express the effect in presence of the cause? ” Model using (Lu, Yuille, Liljeholm, Cheng, & Holyoak, 2008)
Priors on causal strength “Sparse and Strong” (Lu, Yuille, Liljeholm, Cheng, & Holyoak, 2008)
Comparing models to data (Lu, Yuille, Liljeholm, Cheng, & Holyoak, 2008)
Experiment design (for each subject) four iterated learning chains one independent learning “chain” (Yeung & Griffiths, in press)
Empirical prior Sparse and Strong prior (Yeung & Griffiths, in press)
Comparing models to data (Yeung & Griffiths, in press)
Empirical fit vs. SS prior fit (Yeung & Griffiths, in press)
Other empirical results… • Concept learning (Griffiths, Christian, & Kalish, 2008) • Reproduction from memory (Xu & Griffiths, 2008) • Estimating linguistic frequencies “DUP” (Reali & Griffiths, 2009) • Systems of color terms (Xu, Dowman, & Griffiths, 2010)
Outline Markov chain Monte Carlo Sampling from the prior (with Mike Kalish, Steve Lewandowsky, Saiwing Yeung) Sampling from category distributions (with Adam Sanborn)
Sampling from categories Frog distribution P(x|c)
A task Ask subjects which of two alternatives comes from a target category Which animal is a frog?
A Bayesian analysis of the task Assume:
Response probabilities If people probability match to the posterior, response probability is equivalent to the Barker acceptance function for target distribution p(x|c)
Collecting the samples Which is the frog? Trial 1 Trial 2 Trial 3
Verifying the method
Training Subjects were shown schematic fish of different sizes and trained on whether they came from the ocean (uniform) or a fish farm (Gaussian)
Between-subject conditions
Choice task Subjects judged which of the two fish came from the fish farm (Gaussian) distribution
Examples of subject MCMC chains
Estimates from all subjects • Estimated means and standard deviations are significantly different across groups • Estimated means are accurate, but standard deviation estimates are high – result could be due to perceptual noise or response gain
Sampling from natural categories Examined distributions for four natural categories: giraffes, horses, cats, and dogs Presented stimuli with nine-parameter stick figures (Olman & Kersten, 2004)
Choice task
Samples from Subject 3 (projected onto plane from LDA)
Mean animals by subject S 1 giraffe horse cat dog S 2 S 3 S 4 S 5 S 6 S 7 S 8
Marginal densities (aggregated across subjects) Giraffes are distinguished by neck length, body height and body tilt Horses are like giraffes, but with shorter bodies and nearly uniform necks Cats have longer tails than dogs
Relative volume of categories Convex Hull Minimum Enclosing Hypercube Convex hull content divided by enclosing hypercube content Giraffe Horse Cat Dog 0. 00004 0. 00006 0. 00003 0. 00002
Discrimination method (Olman & Kersten, 2004)
Parameter space for discrimination Restricted so that most random draws were animal-like
MCMC and discrimination means
Conclusion • Markov chain Monte Carlo provides a way to sample from subjective probability distributions • Many interesting questions can be framed in terms of subjective probability distributions – inductive biases (priors) – mental representations (category distributions) • Other MCMC methods may provide further empirical methods… – Gibbs for categories, adaptive MCMC, …