Map Reduce Hadoop Implementation Outline Map Reduce overview








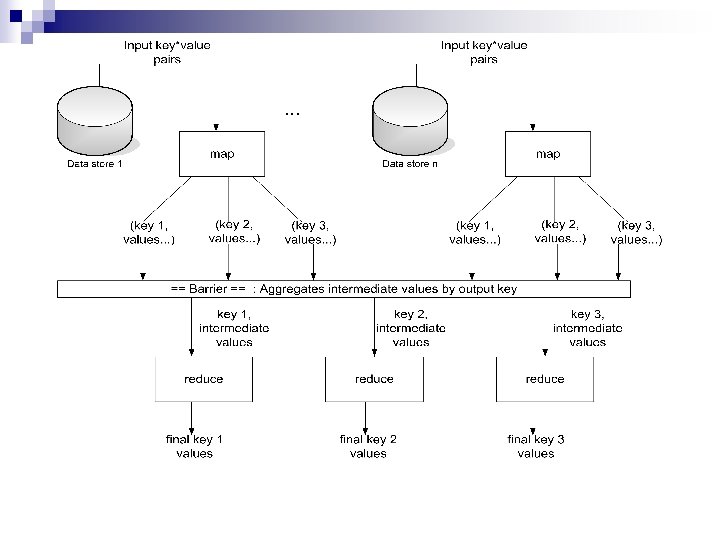
 functions run in parallel, creating different intermediate values from different input data")
: // input_key: document name // input_value:")










- Slides: 21
Map. Reduce: Hadoop Implementation
Outline Map. Reduce overview n Applications of Map. Reduce n Hadoop overview n
Implicit Parallelism In map n n n In a purely functional setting, elements of a list being computed by map cannot see the effects of the computations on other elements If order of application of f to elements in list is commutative, we can reorder or parallelize execution This is the “secret” that Map. Reduce exploits
Motivation: Large Scale Data Processing Want to process lots of data ( > 1 TB) n Want to parallelize across hundreds/thousands of CPUs n … Want to make this easy n
Map. Reduce Automatic parallelization & distribution n Fault-tolerant n Provides status and monitoring tools n Clean abstraction for programmers n
Programming Model Borrows from functional programming n Users implement interface of two functions: n ¨ map (in_key, in_value) -> (out_key, intermediate_value) list ¨ reduce (out_key, intermediate_value list) -> out_value list
map Records from the data source (lines out of files, rows of a database, etc) are fed into the map function as key*value pairs: e. g. , (filename, line). n map() produces one or more intermediate values along with an output key from the input. n
reduce After the map phase is over, all the intermediate values for a given output key are combined together into a list n reduce() combines those intermediate values into one or more final values for that same output key n (in practice, usually one final value per key) n
Parallelism map() functions run in parallel, creating different intermediate values from different input data sets n reduce() functions also run in parallel, each working on a different output key n All values are processed independently n Bottleneck: reduce phase can’t start until map phase is completely finished. n
Example: Count word occurrences map(String input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: Emit. Intermediate(w, "1"); reduce(String output_key, Iterator intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += Parse. Int(v); Emit(As. String(result));
Optimizations n No reduce can start until map is complete: ¨ A single slow disk controller can rate-limit the whole process n Master redundantly executes “slowmoving” map tasks; uses results of first copy to finish Why is it safe to redundantly execute map tasks? Wouldn’t this mess up the total computation?
Optimizations “Combiner” functions can run on same machine as a mapper n Causes a mini-reduce phase to occur before the real reduce phase, to save bandwidth n Under what conditions is it sound to use a combiner?
n n n Distributed Grep: The map function emits a line if it matches a given pattern. The reduce function is an identity function that just copies the supplied intermediate data to the output. Count of URL Access Frequency: The map function processes logs of web page requests and outputs <URL, 1>. The reduce function adds together all values for the same URL and emits a <URL, total count> pair. Inverted Index: The map function parses each document, and emits a sequence of <word, document ID> pairs. The reduce function accepts all pairs for a given word, sorts the corresponding document IDs and emits a <word, list(document ID)> pair. The set of all output pairs forms a simple inverted index. It is easy to augment this computation to keep track of word positions
What is Map. Reduce used for n At Google: ¨ Index construction for Google Search ¨ Article clustering for Google News ¨ Statistical machine translation n At Yahoo!: ¨ “Web map” powering Yahoo! Search ¨ Spam detection for Yahoo! Mail n At Facebook: ¨ Data mining ¨ Ad optimization
Map Reduce Advantages/Disadvantages Simple and easy to use. n Fault tolerance. n Flexible. n Independent of the storage. Disadvantages: n no high level language. n No schema and no index. n A single fixed dataflow. n Low efficiency. n
Hadoop n Apache Hadoop is an open source Map. Reduce implementation that has gained significant traction in the last few years in the commercial sector. n Hadoop is an open-source distributed computing platform that implements the Map. Reduce model. n Hadoop consists of two core components: the job management framework that handles the map and reduce tasks and the Hadoop Distributed File System (HDFS).
n Hadoop's job management framework is highly reliable and available, using techniques such as replication and automated restart of failed tasks. n HDFS is a highly scalable, fault-tolerant file system modeled after the Google File System. The data locality features of HDFS are used by the Hadoop scheduler to schedule the I/O intensive map computations closer to the data n HDFS relies on local storage on each node while parallel file systems are typically served from a set of dedicated I/O servers.
n Job. Tracker is the daemon service for submitting and tracking Map. Reduce jobs in Hadoop. There is only One Job Tracker process run on any hadoop cluster. n The Job. Tracker is single point of failure for the Hadoop Map. Reduce service. If it goes down, all running jobs are halted. n A Task. Tracker is a slave node daemon in the cluster that accepts tasks (Map, Reduce and Shuffle operations) from a Job. Tracker. There is only One Task Tracker process run on any hadoop slave node.
Difference between HDFS and NAS n n n In HDFS Data Blocks are distributed across local drives of all machines in a cluster. Whereas in NAS data is stored on dedicated hardware. HDFS is designed to work with Map Reduce System, since computation are moved to data. NAS is not suitable for Map Reduce since data is stored separately from the computations. HDFS runs on a cluster of machines and provides redundancy using a replication protocol. Whereas NAS is provided by a single machine therefore does not provide data redundancy.
n THANK YOU n G. shiva theja