Machine Translation Models with Attention 1 1 Machine





 7")













 Bilinear (Luong et")

















![참고문헌 [1] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based](https://slidetodoc.com/presentation_image_h/b4839cd72871035caefaf6c6680ab36d/image-42.jpg "참고문헌 [1] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. \"Effective approaches to attention-based")
- Slides: 42
Machine Translation & Models with Attention 인공지능 연구실, 조상현 1
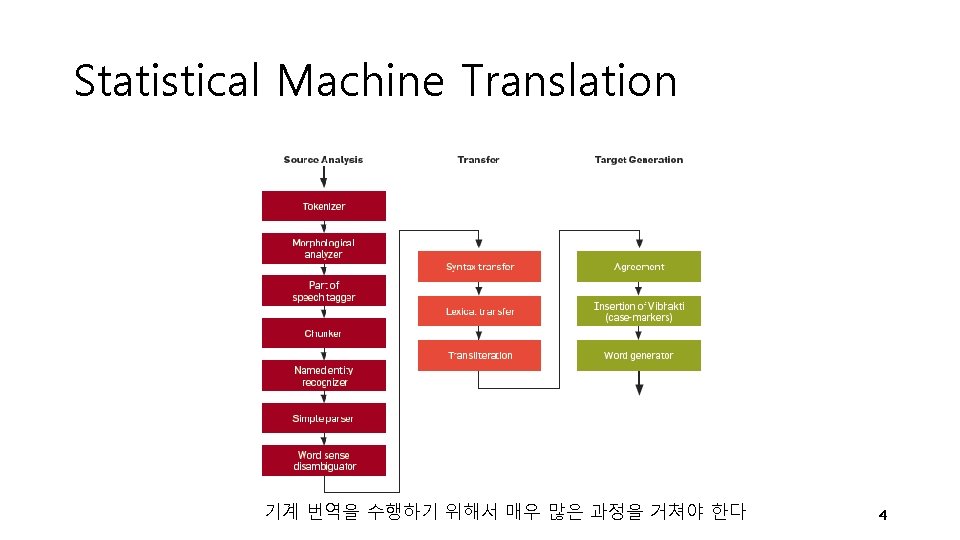
목차 1. Machine Translation 2. Encoder-Decoder Model 3. Encoder-Decoder Sequence Model 4. Big wins of NMT 5. Multilingual NMT 6. Attention with NMT 7. More about Attention 8. Decoding Method 9. Recent Trends of NMT 10. Conclusion 2
Neural Machine Translation Source Sentence Preprocess Neural Network Target Sentence 5
Neural encoder-decoder Architectures 6
Modern Sequence Models(Seq 2 Seq) 7
Modern Sequence Models - 1 8
Conditional Recurrent Language Model - 1 9
Conditional Recurrent Language Model - 2 10
Four big wins of Neural MT 11
Failure of NMT 12
Changes of NMT 13
Multilingual NMT System - 1 14
Multilingual NMT System - 2 15
Multilingual NMT System - 3 16
Zero-Shot Translation 17
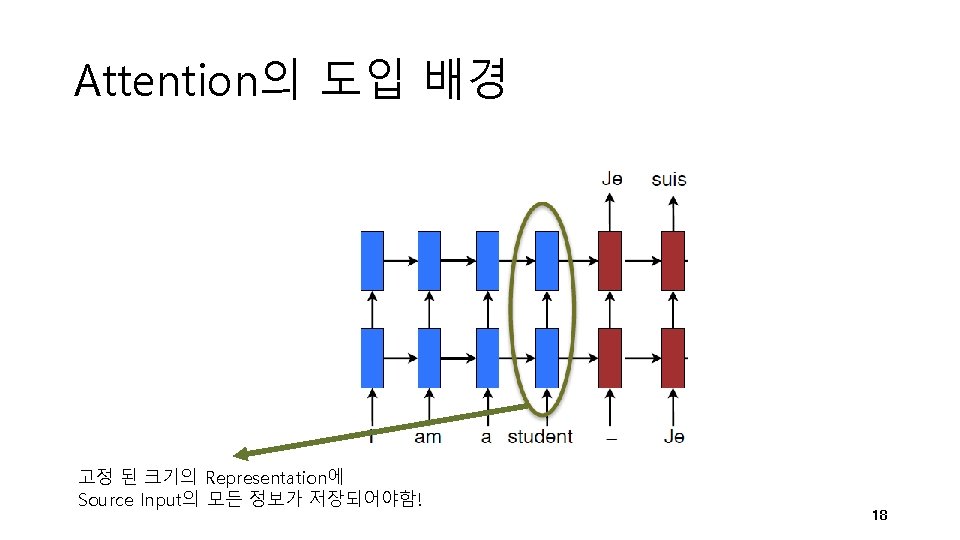
Attention Mechanism Attention을 통해 생성 된 가중치 벡터 19
Gloval vs Local 20
Word alignment 별도로 구축해야하는 작업 End-to-End Training 21
Effective Attention Score Function - 1 Dot Product(Luong et al. 2015) Bilinear (Luong et al. 2015) (NMT에서 가장 많이 사용) Multi-layer Perceptron(Bahdanau et al. 2015) 1 레이어의 Feedforward Neural Network이며, 여러 레이어를 쌓는 모델도 존재한다 22
Effective Attention Score Function - 2 Multiplicative 방식 Additive 방식의 Multi-layer Perceptron Attention (성능은 더 좋다고 알려져 있지만, 병렬 연산의 측면에서 불리함) 23
Effective Attention Score Function - 3 Dot Product Attention 굳이 Perceptron을 두지 않아도 Context Representation만으로 Attention의 비교가 충분하다 Scaled Dot Product (Vaswani et al. 2017) 평균은 0, 분산은 1로 조정함으로써 Overflow나 Underflow를 방지 24
Effective Attention Score Function - 3 Dot Product Attention 굳이 Perceptron을 두지 않아도 Context Representation만으로 Attention의 비교가 충분하다 Scaled Dot Product (Vaswani et al. 2017) 평균은 0, 분산은 1로 조정함으로써 Overflow나 Underflow를 방지 Transformer, BERT에서 사용 25
More about Attention 이미지 캡션 Self-Attention 26
Effectiveness of Attention 27
Effectiveness of Attention 29
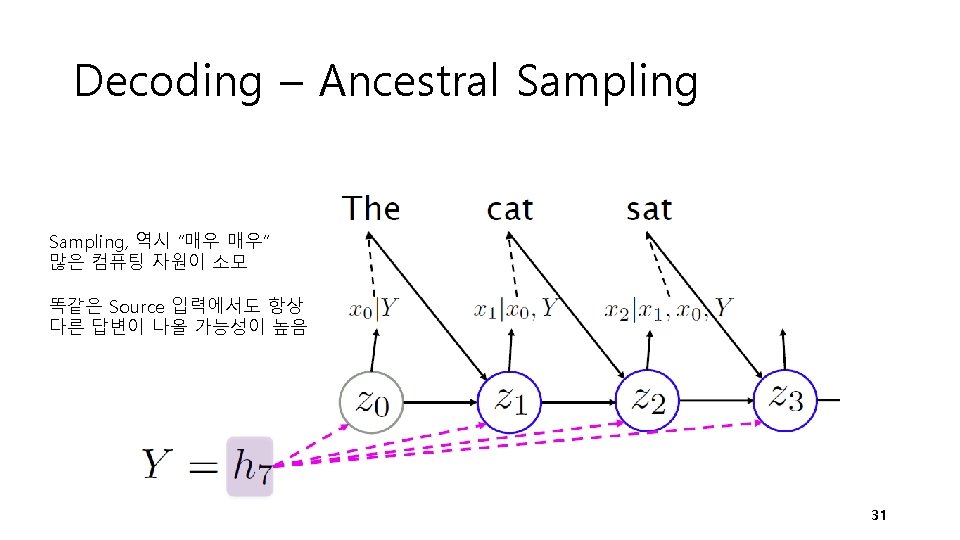
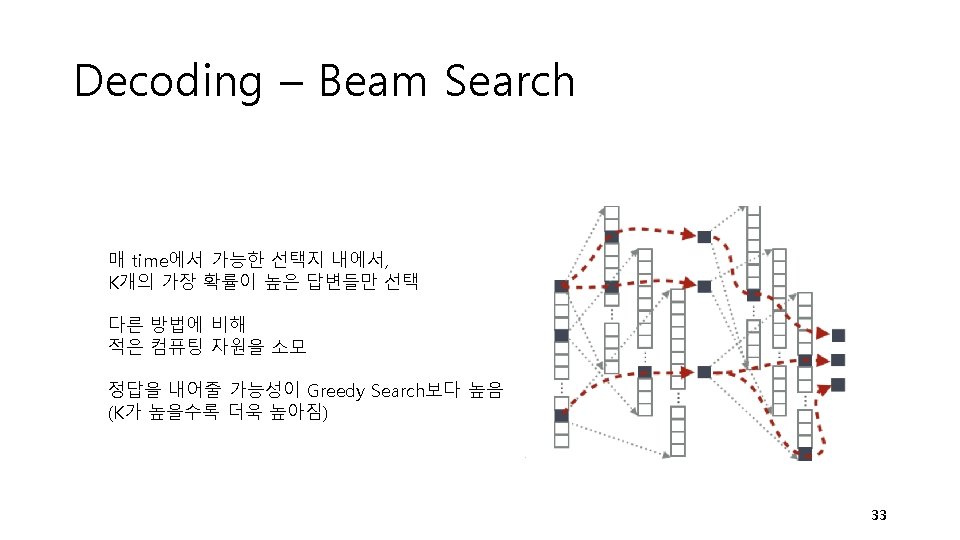
Decoding – Exhaustive Search Perhaps with quantum computer and quantum annealing? 30
Four big wins of Neural MT 1. End-to-End training 2. Distributed representation 3. Better exploitation of context 4. More fluent text generation 34
Four big wins of Neural MT 1. End-to-End training 2. Distributed representation 3. Better exploitation of context 4. More fluent text generation 35
Four big wins of Neural MT 1. End-to-End training 2. Distributed representation 3. Better exploitation of context 4. More fluent text generation 36
Four big wins of Neural MT 1. End-to-End training 2. Distributed representation 3. Better exploitation of context 4. More fluent text generation 37
Four big wins of Neural MT 1. End-to-End training 2. Distributed representation 3. Better exploitation of context 4. More fluent text generation 38
Recent Trends in NMT - 1 • 기존의 RNN 기반의 Encoder/Decoder Model이 아닌 대부분의 SOTA 모델들은 Transformer 기반의 모델을 사용 (혹은 Transformer + CNN) WMT English-French Leader Board 39
참고문헌 [1] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based neural machine translation. " ar. Xiv preprint ar. Xiv: 1508. 04025 (2015). [2] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks. " Advances in neural information processing systems. 2014. [3] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate. " ar. Xiv preprint ar. Xiv: 1409. 0473 (2014). [4] Johnson, Melvin, et al. "Google’s multilingual neural machine translation system: Enabling zero-shot translation. " Transactions of the Association for Computational Linguistics 5 (2017): 339 -351. [5] Vaswani, Ashish, et al. "Attention is all you need. " Advances in Neural Information Processing Systems. 2017. 42