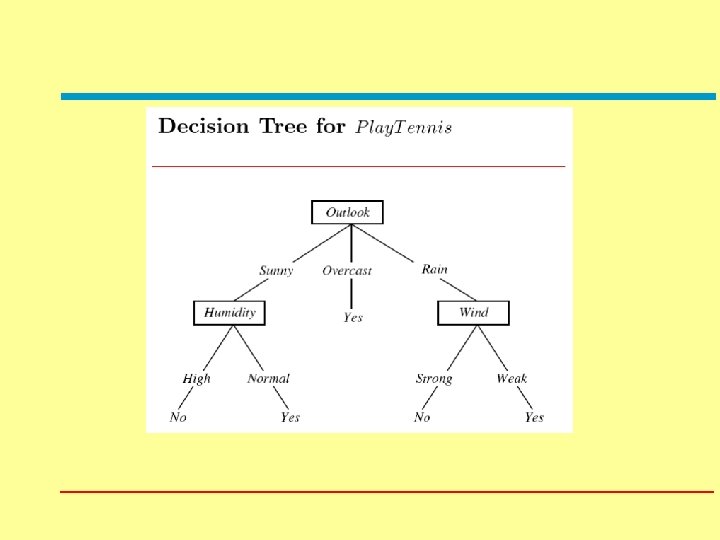
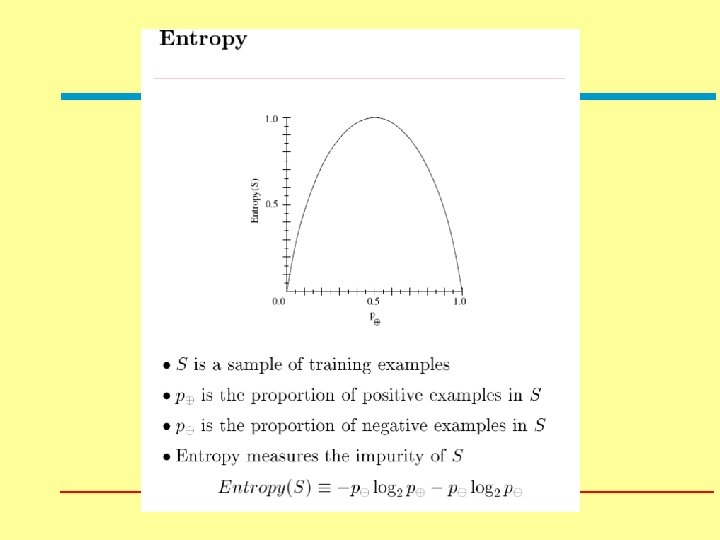
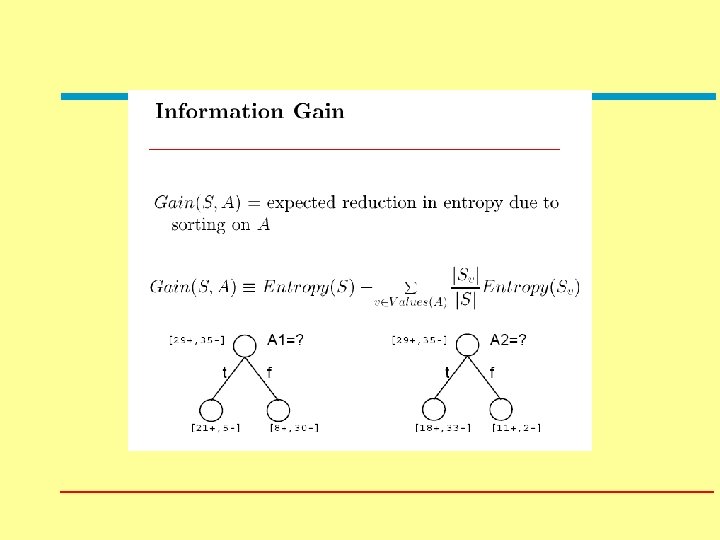
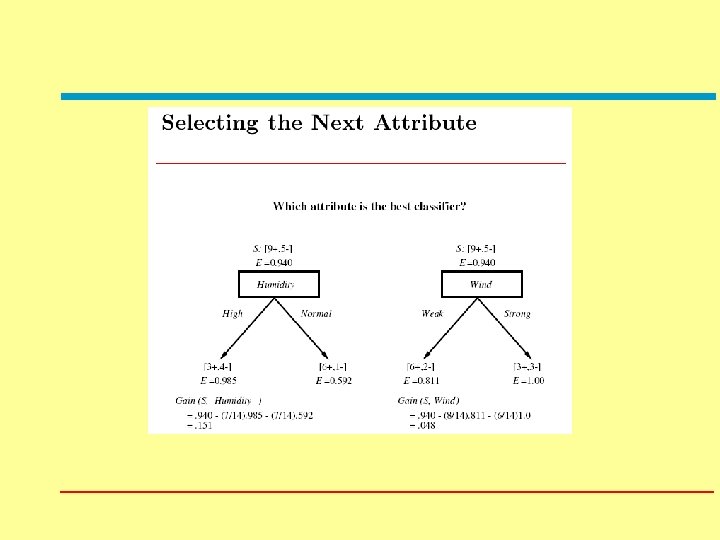
Machine Learning Lecture 1 Intro Decision Trees Moshe

 q Most slides adapted")





) of some unknown function f q Find:")




: The true function f : X {1, 2,")

 = sgn {x ¢ w - } = sgn{ i=1 n wi")
 q q (x 1 Æ x 2) Ç (: {x 1} Æ")









- Slides: 30
Machine Learning Lecture 1: Intro + Decision Trees Moshe Koppel Slides adapted from Tom Mitchell and from Dan Roth
Administrative Stuff q Textbook: Machine Learning by Tom Mitchell (optional) q Most slides adapted from Mitchell q Slides q Grade: will be posted (possibly only after lecture) 50% final exam; 50% HW (mostly final)
What’s it all about? q Very loosely: We have lots of data and wish to automatically learn concept definitions in order to determine if new examples belong to the concept or not.
Supervised Learning Given: Examples (x, f (x)) of some unknown function f q Find: A good approximation of f q q x provides some representation of the input q The process of mapping a domain element into a representation is called Feature Extraction. (Hard; ill-understood; important) qx 2 {0, 1}n or x 2 <n q The target function (label) q f(x) 2 {-1, +1} Binary Classification q f(x) 2 {1, 2, 3, . , k-1} Multi-classification q f(x) 2 < Regression INTRODUCTION CS 446 -Fall 10 8
Supervised Learning : Examples q Disease diagnosis q q q Part-of-Speech tagging q q q x: An English sentence (e. g. , The can will rust) f : The part of speech of a word in the sentence Face recognition q q q x: Properties of patient (symptoms, lab tests) f : Disease (or maybe: recommended therapy) x: Bitmap picture of person’s face f : Name the person (or maybe: a property of) Automatic Steering q q x: Bitmap picture of road surface in front of car f : Degrees to turn the steering wheel INTRODUCTION CS 446 -Fall 10 9
A Learning Problem x 1 x 2 x 3 x 4 Unknown function Example INTRODUCTION y = f (x 1, x 2, x 3, x 4) x 1 x 2 x 3 x 4 y 1 0 0 2 0 1 0 0 0 Can you learn this function? 3 0 0 1 1 1 What is it? 4 1 0 0 1 1 5 0 1 1 0 0 6 1 1 0 0 0 7 0 1 1 0 CS 446 -Fall 10 0 10
Hypothesis Space Example Complete Ignorance: There are 216 = 65536 possible functions over four input features. We can’t figure out which one is correct until we’ve seen every possible input-output pair. After seven examples we still have 29 possibilities for f Is Learning Possible? INTRODUCTION CS 446 -Fall 10 x 1 x 2 x 3 x 4 y 0 0 0 0 1 1 1 1 11 0 0 1 1 0 1 0 1 ? ? 0 1 0 0 0 ? ? 1 ? ? 0 ? ? ?
General strategies for Machine Learning q Develop limited hypothesis spaces Serve to limit the expressivity of the target models q Decide (possibly unfairly) that not every function is possible. q q Develop algorithms for finding a hypothesis in our hypothesis space, that fits the data q And hope that they will generalize well INTRODUCTION CS 446 -Fall 10 12
Terminology q q Target function (concept): The true function f : X {1, 2, …K}. The possible value of f: {1, 2, …K} are the classes or class labels. Concept: Boolean function. Example for which f (x)= 1 are positive examples; those for which f (x)= 0 are negative examples (instances) q Hypothesis: A proposed function h, believed to be similar to f. Hypothesis space: The space of all hypotheses that can, in principle, be output by the learning algorithm. q Classifier: A function f. The output of our learning algorithm. q Training examples: A set of examples of the form {(x, f (x))} q INTRODUCTION CS 446 -Fall 10 13
Representation Step: What’s Good? Learning problem: Find a function that best separates the data q What function? q What’s best? q (How to find it? ) q Linear = linear in the instance space x= data representation; w = the classifier Y = sgn {w. Tx} q A possibility: Define the learning problem to be: Find a (linear) function that best separates the data INTRODUCTION CS 446 -Fall 10 14
Expressivity f(x) = sgn {x ¢ w - } = sgn{ i=1 n wi xi - } q Many functions are Linear Conjunctions: q y = x 1 Æ x 3 Æ x 5 q y = sgn{1 ¢ x 1 + 1 ¢ x 3 + 1 ¢ x 5 - 3} q At least m of n: q y = at least 2 of {x 1 , x 3, x 5 } q y = sgn{1 ¢ x 1 + 1 ¢ x 3 + 1 ¢ x 5 - 2} q q Many functions are not Xor: y = x 1 Æ x 2 Ç : x 1 Æ : x 2 q Non trivial DNF: y = x 1 Æ x 2 Ç x 3 Æ x 4 q INTRODUCTION CS 446 -Fall 10 15
Exclusive-OR (XOR) q q (x 1 Æ x 2) Ç (: {x 1} Æ : {x 2}) In general: a parity function. x 2 xi 2 {0, 1} f(x 1, x 2, …, xn) = 1 iff xi is even This function is not linearly separable. x 1 INTRODUCTION CS 446 -Fall 10 16
A General Framework for Learning q Goal: predict an unobserved output value y 2 Y based on an observed input vector x 2 X q Estimate a functional relationship y~f(x) from a set {(x, y)i}i=1, n q Most relevant - Classification: y {0, 1} (or y {1, 2, …k} ) q q (But, within the same framework can also talk about Regression, y 2 < What do we want f(x) to satisfy? q q Simply: # of mistakes […] is a indicator function We want to minimize the Loss (Risk): L(f()) = E X, Y( [f(x) y] ) Where: E X, Y denotes the expectation with respect to the true distribution. INTRODUCTION CS 446 -Fall 10 17
Summary: Key Issues in Machine Learning q Modeling How to formulate application problems as machine learning problems ? How to represent the data? q Learning Protocols (where is the data & labels coming from? ) q q Representation: q q q What are good hypothesis spaces ? Any rigorous way to find these? Any general approach? Algorithms: q q What are good algorithms? How do we define success? Generalization Vs. over fitting The computational problem INTRODUCTION CS 446 -Fall 10 18