Machine Learning in R and its use in


 Artificial Intelegence (AI)")


![R and R packages > classifier <- naive. Bayes(iris[, 1: 4], iris[, 5]) >](https://slidetodoc.com/presentation_image_h/9c896f19b2357b6e5859e16590ff46f0/image-7.jpg "R and R packages > classifier <- naive. Bayes(iris[, 1: 4], iris[, 5]) >")






 1. C 4. 5")



- Slides: 17
Machine Learning in R and its use in the statistical offices stat. unido. org v. todorov@unido. org 1
Outline 1. Machine learning and R 2. R packages 3. Machine learning in official statistics 4. Top 10 algorithms 5. References 2
What I talk about when I talk about Machine Learning (ML) Artificial Intelegence (AI) Data Mining (DM) Statistics 3
R and R packages • What makes R so useful? – • • The users can extend and improve the software or write variations for specific tasks. The R package mechanism allows packages written for R to add advanced algorithms, graphs, machine learning and mining techniques Each R package provides a structured standard documentation including code application examples
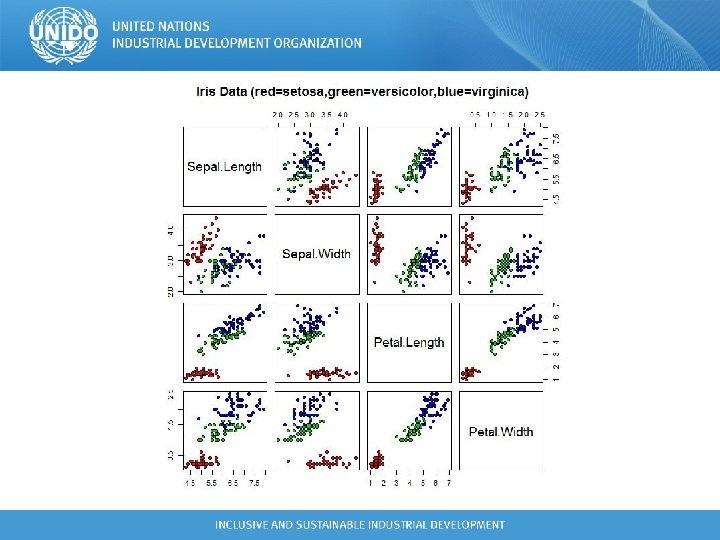
R and R packages ## Naive Bayes example > install. packages('e 1071', dependencies = TRUE) > library(class) > library(e 1071) > data(iris) > pairs(iris[1: 4], main = "Iris Data (red=setosa, green=versicolor, blue=virgini ca)", pch = 21, bg = c("red", "green 3", "blue")[unclass(iris$Species)])
R and R packages > classifier <- naive. Bayes(iris[, 1: 4], iris[, 5]) > table(predict(classifier, iris[, -5]), iris[, 5]) setosa versicolor virginica setosa 50 0 0 versicolor 0 47 3 virginica 0 3 47
Machine Learning for Official Statistics I. III. IV. Automatic Coding Editing and Imputation Record Linkage Other Methods
Automatic coding A. Automatic coding via Bayesian classifier: caret, kla. R B. Automatic occupation coding via CASCOT: algorithm not described C. Automatic coding via open-source indexing utility: ? D. Automatic coding of census variables via SVM: e 1071 (interface to libsvm)
Editing and Imputation A. Categorical data imputation via neural networks and Bayesian networks: neuralnet, g. Rain, bnlearn, deal B. Identification of error-containing records via classification trees: rpart, tree, caret C. Imputation donor pool screening via cluster analysis: class, kla. R, cluster, kmeans(), hclust() D. Imputation via Classification and Regression Trees (CART): rpart, caret, RWeka E. Determination of imputation matching variables via Random Forests: random. Forest F. Creation of homogeneous imputation classes via CART: rpart G. Derivation of edit rules via association analysis: arules
Record Linkage • Weighting vector classification: – The last major step in record linkage or record de-duplication – could be understood as a classification problem • In R: rpart, bagging() in package ipred, ada, functions svm() and nnet() in package e 1071
Other Methods A. B. C. D. E. F. G. Questionnaire consolidation via cluster analysis: class, kla. R, cluster. . . Forming non-response weighting groups via classification trees: rpart, tree, caret Non-respondent prediction via classification trees: rpart, tree, caret Analysis of reporting errors via classification trees: rpart, tree, caret Substitutes for surveys via internet scraping: scrape. R, rvest Tax evader detection via k-nearest neighbours: class, kknn Crop yield estimation via image processing on satellite imaging data: is this ML?
Do we Need Hundreds of Classiers to Solve Real World Classication Problems? • • Fernandez-Delgado, Cernadas, Barro (2014) Evaluate 179 classifiers arising from 17 families on 121 data sets By far best are random forests and SVM with Gaussian kernel Most of the best classiffiers are implemented in R and tuned using caret • seems the best alternative to select a classier implementation
Top 10 ML/DM Algorithms Xindong Wu and Vipin Kumar (2009) 1. C 4. 5 – generates classifiers expressed as decision trees or ruleset form 2. K-Means – simple iterative method to partition a given dataset into a userspecified number of clusters, k 3. SVM – support vector machines 4. Apriori - derive association rules 5. EM - Expectation–Maximization algorithm 6. Page. Rank - produces a static ranking of Web pages 7. Ada. Boost – Ensemble learning 8. k. NN - k-nearest neighbor classification 9. Naive Bayes – simple classifier, applying the Bayes‘ theorem with independence assumptions between the features 10. CART - Classification and Regression Trees
The best R packages for ML 1. 2. 3. 4. 5. 6. 7. e 1071: Naive Bayes, SVM, latent class analysis rpart: regression trees Random. Forest: RF gbm: generalized boosting models kernlab: SVM caret: Classification and Regression Training neuralnet: neural networks CRAN Task View: Machine Learning & Statistical Learning
Machine learning books
17