Machine Learning Based Applications Classification Technologies All rights

Machine Learning Based Applications Classification Technologies Ó All rights reserved. No part of this publication and file may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission of Professor Nen-Fu Huang (E-mail: nfhuang@cs. nthu. edu. tw). ML-1

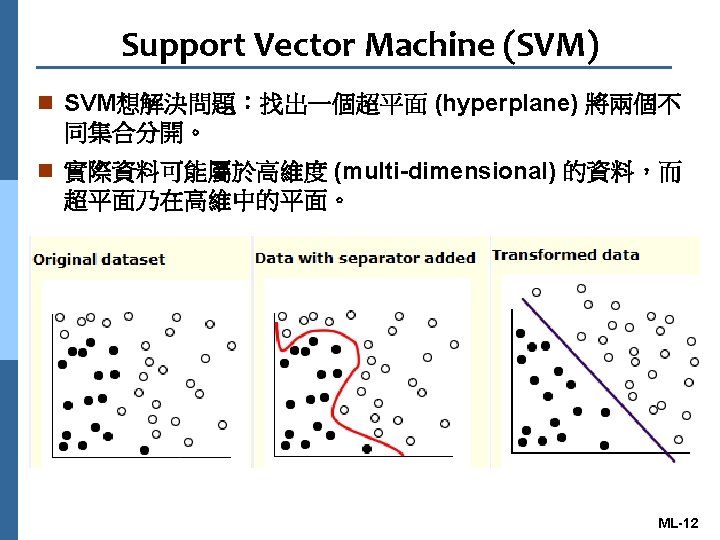
Agenda n Introduction to Applications identification n Machine Learning Based Technologies n Machine Learning based Applications Identification Technologies ML-2
 issues are focused in recently years since: The introducing")
Application Traffic identification(or traffic classification) issues are focused in recently years since: The introducing of P 2 P application greatly impacts the network management task. l Port number is not the best and efficient discriminator to identify these prevalent traffics. l l How about string matching method? Accurate! But… 4 It cannot identify the encrypted traffic. 4 High cost on manually maintenance work for protocol signatures. 4 High cost to match string in very high speed network. 4 Privacy issue is under debating. ML-3

Application Traffic Identification n Identification at different levels Category level or Qo. S class (Bulk data transfer FTP&P 2 P, interactive, mail, web, streaming) l Protocol level (Kazza, e. Mule/e. Donkey, Bittorrent, MSN, FTP, POP 3, SMTP, HTTP, Skype, Winny, Share, …. ) l Behavior level (FTP control, FTP data, MSN file transfer, MSN message chatting, MSN voip, Skype Chatting, Skype voip, Skype File transfer, Skype Video conference, …) l Most existing researches focus on classification in protocol or category level. l ML-4

Application Traffic Identification n Utilization target l Offline based: 4 traffic trend analysis. l Online based: 4 traffic shaping, 4 traffic engineering, 4 security management. ML-5
 l Based on some intrinsically different")
How to resolve the problem? n Heuristics methods(2004~2005) l Based on some intrinsically different behavior, some rule can be constructed. 4 E. g. # dest IPs = # of dest ports the host is running P 2 P. l To differentiate P 2 P or non-P 2 P traffic. n Machine learning based techniques: (2004 ~ ) l To construct the “statistical signatures” for different categories/application protocols. l Most machine learning techniques are directly employed to construct traffic signature. ML-6

The Milestone of Researches on Application Traffic Identification n Before 2003: String matching and port number. n 2003~2005: l Heuristics l Machine learning method. n 2006~ : Machine learning method for real-time based traffic classification. l First k data packet sizes and direction of TCP connection. l Stage-based classification(Statistical data in each stage) ML-7

The Classes of Applied Machine Learning Algorithms n Supervised-Machine learning The model of traffic characteristics is constructed from the training instances with previously defined class label. n Unsupervised-Machine learning (Clustering) l The model of traffic characteristics is constructed from the training instances without previously defined class label. n However, all the existing training set employed by both include pre-classified label. l Because each cluster would contain several different classes/protocols. l ML-8
 n The key issues for machine-learning based traffic identification are: l")
The Discriminators (Attributes) n The key issues for machine-learning based traffic identification are: l What are the most distinguishable characteristics (attributes/discriminators)? l How to remove the expensive cost on training? n Different discriminators: l From L 3/L 4 layer—packet inter-arrival time, total packet size, number of packets, …, etc. l Combination of L 3/L 4 attributes with different perspectives. e. g. upload/download size ratio. ML-9
")
Data Clustering Methods n Data Clustering or Partitioning Methods l Support Vector Machine (SVM) l Nearest Neighbor、 l Linear Discriminant Analysis (LDA) l K-means l Neural Networks、 l Decision Tree ML-10


Nearest Neighbor n To classify a data point x, let’s find the nearest neighbor! l The points with same property should be closely. l The class of the nearest neighbor will be assigned to the data point x. n K- Nearest Neighbor: l To find the k nearest neighbors and let them “vote”. ML-13

K-Nearest Neighbor X Stored training set patterns X input pattern for classification --- Euclidean distance measure to the nearest three patterns ML-14

K-Nearest Neighbor Algorithm Store all input data in the training set For each pattern in the test set Search for the K nearest patterns to the input pattern using a Euclidean distance measure For classification, compute the confidence for each class as Ci /K, (where Ci is the number of patterns among the K nearest patterns belonging to class i. ) The classification for the input pattern is the class with the highest confidence. ML-15
 n To find the good “projection” for original points. n")
Linear Discriminant Analysis (LDA) n To find the good “projection” for original points. n Linear discriminant analysis finds a linear transformation ("discriminant function") of the two predictors, X and Y, that yields a new set of transformed values that provides a more accurate discrimination than either predictor alone: Transformed Target = C 1*X + C 2*Y 3 features More information: http: //www. dtreg. com/lda. htm http: //neural. cs. nthu. edu. tw/jang/books/dcpr/index. asp ML-16

Linear Discriminant Analysis 2 features More information: http: //www. dtreg. com/lda. htm http: //neural. cs. nthu. edu. tw/jang/books/dcpr/index. asp ML-17

LDA Evaluation Example n Attributes for this evaluation: the average packet size, flow duration, bytes per flow, packets per flow, and Root Mean Square (RMS) packet size. 18 ML-18

LDA Evaluation Example ML-19

K-means Clustering n For given number of clusters k, to iteratively find k centers of these k clusters and “partition” all the points into these k clusters until the nearest center does not change. n Each data point is expressed as a vector, and Euclidean distance is the most common distance computation function. ML-20

Decision trees n Decision trees are popular for pattern recognition because the models they produce are easier to understand. Root node A. Nodes of the tree C A B. Leaves (terminal nodes) of the tree A C. Branches (decision point) of the tree B B ML-21

Decision trees -Binary decision trees n Classification of an input vector is done by traversing the tree beginning at the root node, and ending the leaf. n Each node of the tree computes an inequality (ex. BMI<24, yes or no) based on a single input variable. n Each leaf is assigned to a particular class. BMI<24 No Yes Yes No ML-22

A High Accurate Machine-Learning Algorithm for Identifying Application Traffic in Early Stage Nen-Fu Huang+ , Gin-Yuan Jai+, and Han-Chieh Chao 1 +Department of Computer Science, National Tsing Hua University, Taiwan 1 National Ilan University, Taiwan IEEE ICC 2008, Information Sciences, 2013 (SCI)

Application Rounds-Example ML-24

Application Rounds-Concepts n Talk block Tij n Round Ii ML-25

Attributes-Interaction Round Discriminators Inter-arrival time between In and In+1 ith Interaction Response time between Ti. A and Ti. B of Ii Round Ii Number of total bytes/packets sent during Ii Data throughput of bytes/packets during Ii ML-26

Attributes-TALK block Discriminators Average inter-arrival time of packets of Tij TALK block Tij of Interaction Round Ii ( j = A or B ) Number of total bytes/packets sent during Tij Elapsed time of Tij Data throughput of bytes/packets during Tij ML-27

Attributes-L 7 features Discriminators Number of total bytes/packets sent by L 7 layer features initializer or listener during first k rounds of a TCP/UDP Sum of elapsed time from T 1 A to Tk. A flow Sum of elapsed time from T 1 B to Tk. B Data throughput of bytes/packets during first k rounds (individually initializer or listener) Data throughput of bytes/packets during first k rounds (sum of initializer and listener) ML-28

Attributes-L 4 features Discriminators Initializer’s and Listener’s Port number Which side sends the first data packet L 4 layer features of a (the flag defines the initialize, can be TCP/UDP flow client or server) L 4 protocol (TCP or UDP) ML-29
 Protocol signature Result Flow Preprocessing Flow Sets Flow")
Experiment Architecture Traffic Dump (payload included) Protocol signature Result Flow Preprocessing Flow Sets Flow Sampling Random Split Average … … … Machine Learning Training Sets 10 Test Sets 1 … Training Sets 1 Result 10 Sample Set Test Sets 10 10 -fold cross validation ML-30

Traffic Traces n NIU Traffic: l 2007/01/30 13: 25 to 2007/01/31 13: 25 l Separated into two sub-traffic traces 4 NIU-1, NIU-2 n NTHU Traffic: l Captured at two PC rooms l Simulated user behaviors l CS 326: NTHU-1, 2008/11/18 15: 16 -17: 20 l CS 328: NTHU-2, 2008/11/18 15: 45 -17: 16 ML-31

Building the “Background Truth” n For evaluation purpose, the string and port matching methods are adopted to get the “real class” of each flow. l String pattern: 4 L 7 filter and some rules from testing and related works. l Port rule: 4 IANA port assignment: for traditional protocol 4 Specific server port number: MSN, Yahoo, etc. ML-32

Traffic Sampling n The proportion of sampled flows for each application l original ratio sampling: to reflect the original proportion l fixed-number sampling: to have a more balanced view for learning accuracy n The transport layer protocols considered for sampling l TCP+UDP, TCPonly, UDPonly n The number of first APPR rounds considered for traffic classification l R 1(first round), R 2(first two rounds), R 3, and R 4. ML-33

Overall Accuracy Several Machine Learning Algorithms ML-34

The Influence of Feature Selection Overall Accuracy ML-35
 ML-36")
The Influence of Feature Selection Model Building Time (Training) ML-36
 ML-37")
The Influence of Feature Selection Model Testing Time (Testing) ML-37
![Overall Accuracy Comparison n The supervised machine learning l SVM for [36]: icc 07](http://slidetodoc.com/presentation_image_h2/96aa8a789fbd17f670f7ff2cd17d82f3/image-38.jpg "Overall Accuracy Comparison n The supervised machine learning l SVM for [36]: icc 07")
Overall Accuracy Comparison n The supervised machine learning l SVM for [36]: icc 07 -svm n The unsupervised machine learning l Kmeans for [5]: acm 5 pkt-kmeans l GMM for [6]: conext-proto-Dominant, conext- proto-Port n The semi-supervised machine learning l Kmeans for [17]: jeff. L 0 -kmeans, jeff. L 1 -kmeans ML-38

Overall Accuracy Compared with Other Related Works ML-39

Overall Accuracy Compared with Other Related Works ML-40

Conclusions n The proposed classifier achieved high accuracy for J 48, PART, and Bayesian network algorithms. n The combined selected attributes, including port number, transport layer protocol id, and size information, offers an acceptable test time and overall accuracy. ML-41

Conclusions n Machine learning based techniques to identify the Network Applications are more and more important. n Focus on real-time based, protocol level requirement of application traffic classification. n No existing common traffic traces provided for comparing the performance in the same base line. n Expensive training is still a problem. n Identifying encrypted traffic (e. g. Skype, Winny, Encrypted BT) is a new challenge. n Identifying detailed behaviors of encrypted traffic is even a big challenge. ML-42
- Slides: 42