MA250 Probability and Statistics Nazar Khan PUCIT Lecture

MA-250 Probability and Statistics Nazar Khan PUCIT Lecture 5

Measurement Error • In an ideal world, if the same thing is measured several times, the same result would be obtained each time. • In reality, there are differences. – Each result is thrown off by chance error. Individual measurement = exact value + chance error

Measurement Error • No matter how carefully it is made, a measurement could have been different than it is. • If repeated, it will be different. • But how much different? – Simple answer: • Repeat the measurements. • Consider the SD

Measurement Error • Variability in measurements reflects the variability in the chance errors Individual measurement = exact value + chance error SD(Measurements) = exact value + SD(chance error)

Measurement Error • An outlier can affect the – Mean – Standard Deviation • What if the majority data follows a normal curve? – The outliers will affect the mean and SD such that the 68 -95 -99 rule might not be followed. • Solution: remove the outliers and then do the normal approximation.

Outliers 1 SD is covering ~86% of the data, so the normal approximation cannot be used. Outliers

Outliers 1 SD is covering ~68% of the data, so the normal approximation can be used now. Outliers Removed

Bias • Chance error changes from measurement to measurement – sometimes positive and sometimes negative. • Bias affects all measurements in the same way. Individual measurement = exact value + chance error + bias

below.

Dealing with bi-variate data • So far, we have dealt with uni-variate data – One variable only – Age, Height, Income, Family Size, etc. • How can we study relationships between 2 variables? – Relationship between height of father and height of son – Relationship between income and education • Answer: scatter diagrams

Can we summarize the scatter diagram?

Summarizing a Scatter Diagram • Mean • Horizontal SD • Vertical SD Same mean and horizontal and vertical SDs but the left figure shows more association between the 2 variables. • But these statistics do not measure the strength of the association between the 2 variables. • How can we summarize the strength of association?

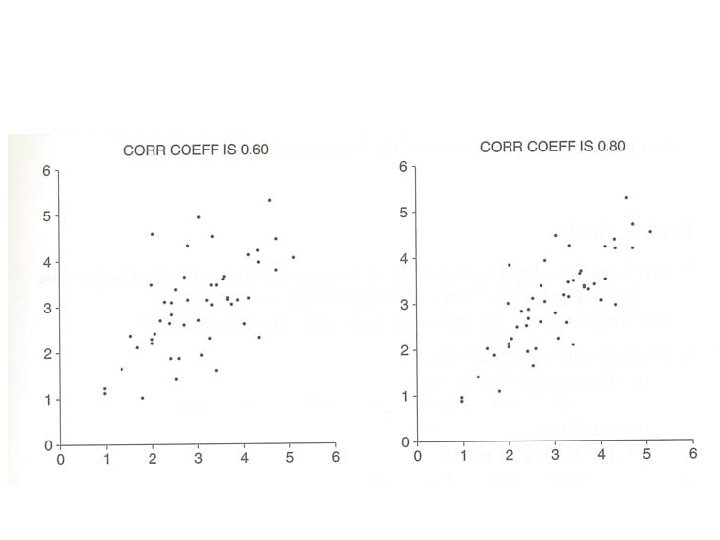
Correlation • Correlation measures the strength of association between 2 variables – As one increases, what happens to the other? • Denoted by r • r=average(x in standard units* y in standard units) Average = 0. 4

How does r measure association strength? • r=average(x in standard units* y in standard units) • When both x and y are simultaneously above or below their means, their product in standard units is +ve. • When +ve products dominate, the average of products is +ve (i. e. , correlation r is +ve). • Similarly for –ve products.

Correlation • r is always between 1 and -1. • r=0 implies no association between x and y. • |r|=1 implies strong linear association. – r=1 implies perfectly linear, positive association. – r=-1 implies perfectly linear, negative association.

Very hard to predict y from x

Easy to predict y from x

Negative association between x and y
 –")
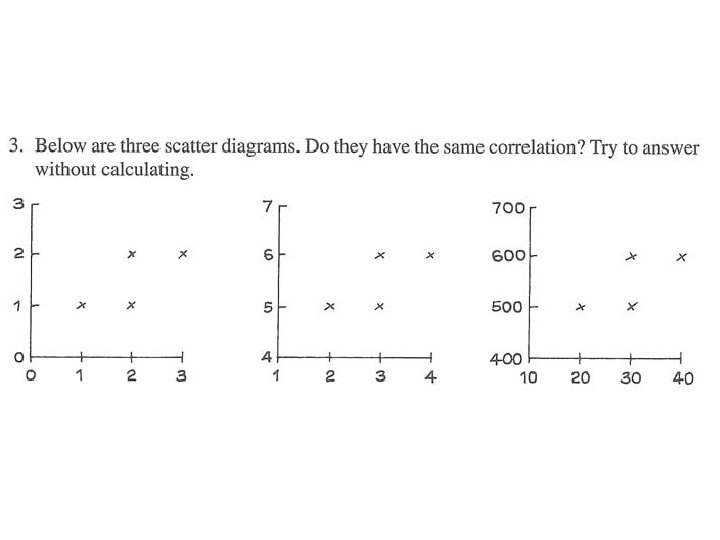
Some Properties of the Correlation Coefficient • r has no units. (Why? ) – The correlation between June temperatures for Lahore and Karachi will be the same in Celcius and Fahrenheit. • r(x, y)=r(y, x) (Why? )

Exceptions! Strong linear association without outlier brings r down to almost 0 r measures linear association only, not all kinds of association.

Association is not Causation! • Correlation measures association but association is not causation. – In kids, shoe-size and reading skills have a strong positive linear association. Does a larger foot improve your reading skills?
 = SD(measurements)")
Summary • Measurement Errors – Chance Error – Bias • SD(chance errors) = SD(measurements) • Let’s us determine if an error is by chance or not. • Correlation measures strength of linear association between 2 variables. – Between -1 and 1 • Not useful for summarizing scatter diagrams with – Outliers, or – Non-linear association. • Association is not causation.
- Slides: 24