Linear SVM Hsueh HueyMiin Department of Statistics National







 classifier is • A")
























 Support-Vector Networks, Machine Learning, 20, 273")
- Slides: 34
Linear SVM Hsueh, Huey-Miin Department of Statistics National Cheng. Chi University 2018 -07 -30 1
OUTLINE • Applications • A linear separable data set • Find the best separating hyperplane • Constraint optimization problem • Constraints: It is a separating hyperplane • Objective function: It is the best! 2
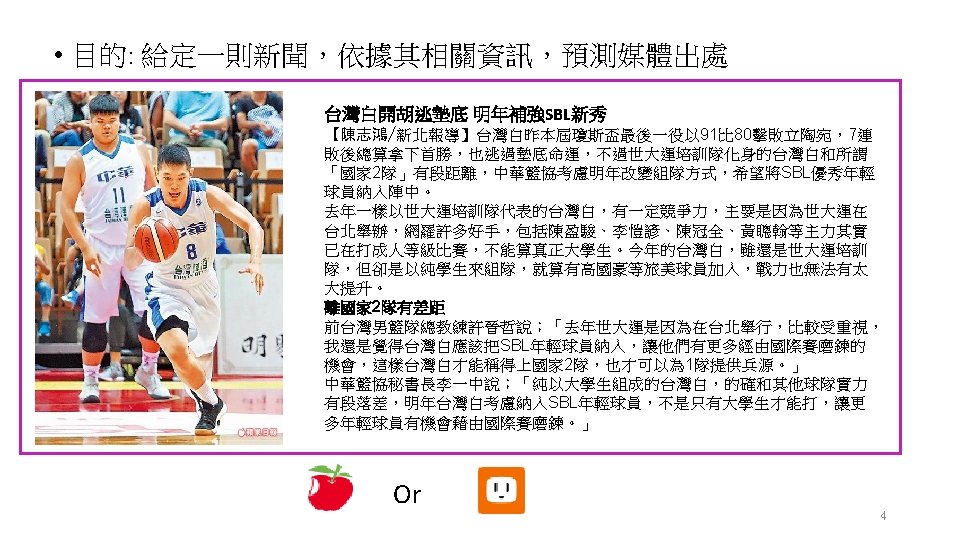
• https: //en. wikipedia. org/wiki/Statistical_learning_theory • Supervised learning involves learning from a training set of data. Every point in the training is an input-output pair, where the input maps to an output. • The learning problem consists of inferring the function that maps the input to the output, such that the learned function can be used to predict output from future input. • In previous example, • the input variables = relevant information of a news • Output = media 5
A supervised learning: Problem formulation • Suppose a training data set formed of n observations. • Each observation includes p input variables and one binary class label. • For the i-th observation, the input variables are denoted by ; and the binary class label is denoted by • The data matrix is given below Input variables label Observations h(x) 6
• Assume the data is linear separable. 7
• Assume the data is linear separable. • The goal is finding a good separating hyperplane. • The hyperplane is called a decision boundary. 8
• A linear hyperplane is • A linear (hyperplane) classifier is • A separating hyperplane should satisfies that for i=1, …, n, • H 1 is not a separating hyperplane, H 2, H 3 are. 9
• Separating hyperplanes are not unique. • H 2 and H 3 are separating hyperplanes. • A good separating hyperplane? • H 3 seems to be better, since it is further away all the observations than H 2. • Distance between a set of points and a hyperplane? 10
• The best separating hyperplane maximizes the minimal distance between the observations and the hyperplane. • Minimal distance = margin • Maximum margin classifier. 11
• A fatter separating hyperplane tolerates more noise on future observations. • More robust! • Fatness=margin=minimal distance. • Distance between a point to a plane? ? H. -T. Lin. Slide 8 of Lecture one of Machine Learning Techniques 12
• Distance of a point to the hyperplane is • Hint: • is a normal vector of the hyperplane, i. e. • The distance of to the hyperplane is the norm of the projection of on the normal vector, where is any point on the hyperplane. • The projection is 13 https: //www. youtube. com/watch? v=HW 3 LYLLc 60 I
14
Point x 1 x 2 x 3 Distance to the plane 15
Start with two points. 16
17
18
• The margin is the minimal distance of the observations to the hyperplane. 19
• The best separating hyperplane can be found by solving the following constraint optimization problem: 20
• Moreover, since and hence, Therefore, 21
• Further, if is the optimal solution, so is for any c>0. • Consider the following restriction, 22
• Consequently, with the additional constraint • The objective function becomes • The restrictions become 23
• The best separating hyperplane is found by the following constraint optimization problem: • Equivalently, 24
• By the method of Lagrange multipliers, we found the optimal solution where are the Lagrange multipliers and • That is, only data points satisfying have an effective contribution to the solution. They are called support-vectors. 25
26
27
Example • Goal: Build a classifier to predict the source of a sport news. • Data: • Observations: 2, 376 sport news • Source: UDN 1, 774 news; Apple Daily: 602 news. • December of 2017 • Class label: y=-1 UDN; y=1, Apple Daily. • Input variables: ? 28
• Input variables Variables Description Outcome space Id Class label apple, udn titlenchar No. of characters in the title N contnchar No. of characters in the content N img No. of images N∪{0} width. W Is the width of any image equal to W? W=600, 640, 656, 1048 or 1049 pixels. 0, 1 height. H Is the height of any image equal to H? H=437, 600, 640, 698, 699 pixels. 0, 1 Different words used/Total words (0, 1) 分享 Does 分享 appear in the news? 0, 1 記者 Does 記者 appear in the news? 0, 1 報導 Does 報導 appear in the news? 0, 1 wordratio 30
• Method: Linear SVM • R package: e 1071 • Performance • 10 -fold cross-validation accuracy on testing data: 99. 87% (0. 20%) • Confusion matrix True Predict apple udn 60. 9 0. 0 0. 1 178. 0 • Findings: • Even a simple linear classifier of few input features can have good performance. • The styles of sport news of two medias are different. 31
Practice • Find a data set and initiate a binary classification problem. • Finish a simple 1 -2 brief report, which should include • Title, author(s)’s name • Aim and goal • Data: Input variables and class label; how the data were collected. • Method: SVM (tunning parameters determination) • Results: Performance and findings • Table and graphs are strongly suggested. 32
Discussion • Key points of linear SVM: • Solution: Classifier • Constraints: • Objective function: • More… • Extreme unbalanced classes • Missing data • Data preprocessing: Input variables standardization 33
Reference • Cortes, C. and Vapnik, V. (1995) Support-Vector Networks, Machine Learning, 20, 273 -297. • Lin, H. -T. Machine Learning Techniques, Lecture 1. 34