Lenguajes Libres de Contexto Curso de Compiladores Preparado

Lenguajes Libres de Contexto Curso de Compiladores Preparado por Manuel E. Bermúdez, Ph. D. Profesor Asociado University of Florida
 es una")
Gramáticas Libres de Contexto • Definición: Una gramática libre de contexto (GLC) es una tupla G = ( , , P, S), donde todas las producciones son de la forma A , donde A � y � u ( )*. • Derivación Izquierda: En cada paso, el símbolo no-terminal más a la izquierda es el que se re-escribe. • Derivación Derecha: En cada paso, el símbolo no-terminal más a la derecha es el que se re-escribe.


Árboles de Derivación Un árbol de derivación describe las reescrituras, en forma independiente del orden (izquierdo o derecho). • Cada rama del árbol corresponde a una producción en la gramática.

 Hojas en el árbol son símbolos terminales. 2) El")
Árboles de Derivación Notas: 1) Hojas en el árbol son símbolos terminales. 2) El “contorno” inferior es la sentencia. 3) Recursividad izquierda causa ramificación a la izquierda. 4) Recursividad derecha causa ramificación a la derecha.

Metas del Análisis Sintáctico • Examinar la hilera de entrada , y determinar si es legal o no en el lenguaje, i. e. si S =>* . • Esto es equivalente a (intentar) construir el árbol de derivación. • Beneficio adicional: si el inento es exitoso, el árbol refleja la estructura sintáctica de la hilera de entrada. • Por lo tanto, el árbol debiera ser único (para una hilera dada).

Ambigüedad en Gramáticas • Definición: Una GLC es ambigua si existen dos derivaciones derechas (o izquierdas, pero no ambas) para alguna sentencia z. • Definición (equivalente) : Una GLC es ambigua si existen dos árboles de derivación diferentes, para alguna sentencia z.
: – Recursividad")
Ambigüedad en Gramáticas Dos ambigüedades clásicas (al menos en lenguajes de programación): – Recursividad simultánea izquierda/derecha: E→E+E – Problema del “else colgante”: S → if E then S else S
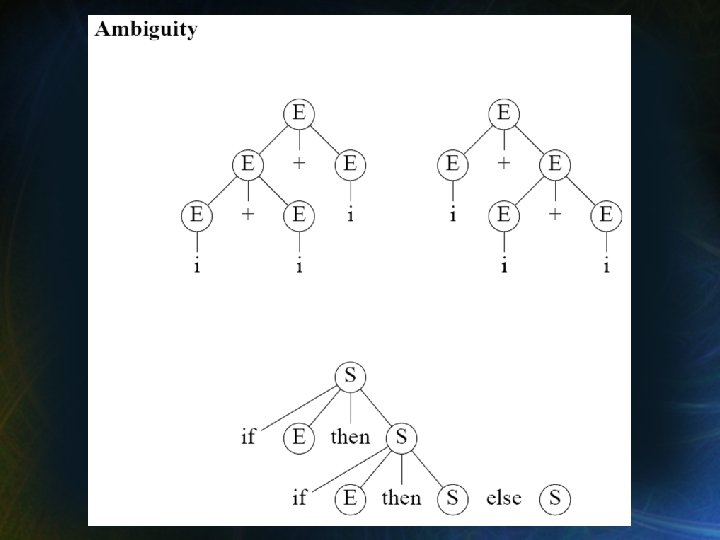

Reducción de Gramáticas ¿ Qué lenguaje genera esta gramática ? S→a A → BCDEF B → ASDFA C → DDCF Respuesta: D → EDBC E → CBA F→S L(G) = {a} Problema: Algunos no-terminales (y producciones) son “inútiles”: no se pueden usar en la generación de ninguna sentencia.
")
Reducción de Gramáticas Definición: Una GLC es reducida sii para todo A Ф, a) S =>* αAβ, para algunos α, β V*, (decimos que A es generable), y b) A =>* z, para algún z Σ* (decimos que A es terminable) G es reducida sii todo símbolo no-terminal A es generable y también terminable.

Reducción de Gramáticas Ejemplo: S → BB B → b. B A → a. A →a B no es terminable, porque B =>* z, para ningún z Σ*. A no es generable, porque S =>* αAβ, para ningunos α, β V*.

Reducción de Gramáticas Para encontrar cuáles no-terminales son generables: 1. Construir el grafo (Ф, δ), donde (A, B) δ sii A → αBβ es una producción. 2. Verificar que todos los nodos son alcanzables desde S.

Reducción de Gramáticas Ejemplo: S → BB B → b. B S B A A → a. A →a A no es generable, porque no es alcanzable desde S.
")
Reducción de Gramáticas Algoritmo 1: Calcular no-terminales generables Generable : = {S} while(Generable cambia) do para cada A → Bβ do if A Generable then Generable : = Generable U {B} od { Ahora, Generable contiene los no-terminales que son generables }

Reducción de Gramáticas Para encontrar cuáles no-terminales son terminables: 1. Construir el grafo (2 Ф, δ), donde (N, N U {A}) δ sii A → X 1 … Xn es una producción, y para todo i, Xi Σ o bien Xi N. 2. Verificar que el nodo Ф (todos los no-terminales) es alcanzable desde el nodo ø (vacío).

Reducción de Gramáticas Ejemplo: S → BB B → b. B A → a. A →a ø {B} {A, B} {A} {S} {B, S} {A, S, B} no es alcanzable desde ø ! Solo {A} es alcanzable desde ø. Conclusión: S y B no son terminables.

Reducción de Gramáticas Algoritmo 2: Calcular no-terminales terminables: Terminable : = { }; while (Terminable cambia) do para cada A → X 1…Xn do if todo no-terminal entre los X’s está en Terminable then Terminable : = Terminable U {A} od { Ahora, Terminable contiene los no-terminales que son terminables. }

Reducción de Gramáticas Algorithmo 3: Reducción de una gramática: 1. Encontrar todos los no-terminales generables. 2. Encontrar todos los no-terminales terminables. 3. Eliminar cualquier producción A → X 1 … Xn si a) A is not generable o si b) algún Xi no es terminable. 4. Si la nueva gramática no es reducida, repetir el proceso.

Reducción de Gramáticas Ejemplo: E→E+T →T T→F*T →P F → not F Q→P/Q P → (E) →i Generable: {E, T, F, P}, no Generable: {Q} Terminable: {P, T, E}, no Terminable: {F, Q} Entonces, se elimina toda producción para Q, y toda producción cuya parte derecha contiene F ó Q.
 →i Generable: {E")
Reducción de Gramáticas Nueva Gramática: E→E+T →T T→P P → (E) →i Generable: {E , T, P} Terminable: {P, T, E} Ahora, la gramática está reducida.

Reducción de Gramáticas Ejemplo: Resultado: S→ → A→ B→ S→a B→b AB a a. A b Generable: {S, A, B} no Terminable: {A} Generable: {S} Terminable: {S, B} Se elimina B → b Se elimina toda producción Resultado final: que contiene A. S→a
 para")
Precedencia y Asociatividad de Operadores • Construyamos una GLC (gramática libre de contexto) para expresiones, que consista de: • El identificador i. • + , - (operadores binarios) con baja precedencia y asociativos por la izquierda. • * , / (operadores binarios) con precedencia media, y asociativos por la derecha. • + y - (operadores unarios) con la más alta precedencia, y asociativos por la derecha.

Gramática para Expresiones E T F P → → → E E T F F F + P ( i + T - T E consiste de T's, separados por –’s y +'s, asociativos a la izquierda, con precedencia baja. * T / T T consiste de F's, separados por *'s y /'s, asociativos a la derecha, con precedencia media. F F F consiste de un solo P, precedido por +'s y -'s, asociativos a la derecha, con precedencia alta. E ) P consiste de una E entre paréntesis, o una i.

Precedencia y Asociatividad de Operadores • Precedencia: – Cuanto más abajo en la gramática, más alta la precedencia. • Asociatividad: – Recursividad izquierda en la gramática, causa asociatividad izquierda del operador, y causa ramificación izquierda en el árbol. – Recursividad derecha en la gramática cause asociatividad derecha del operador, y causa ramificación derecha en el árbol.

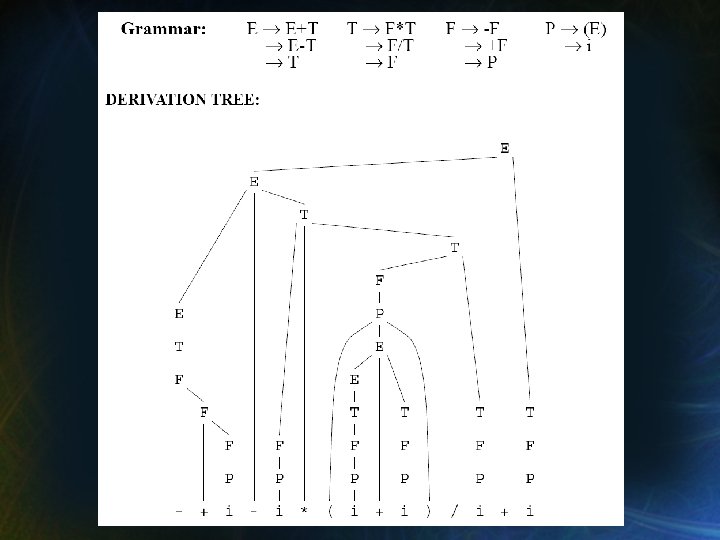
Árboles de Derivación Hilera de Entrada: - + i - i * ( i + i ) / i + i • Construcción (humana) del árbol de derivación: • Método Ascendente. • En cada pasada se procesan los operadores de mayor precedencia. • Los operadores de baja precedencia son los últimos, en la parte superior del árbol.

Precedencia y Asociatividad de Operadores Ejercicio: Escribir una gramática para expresiones: • El identificador i. • ‘&’, ‘¢’, ‘*’ (operadores binarios) con baja precedencia y asociativos por la izquierda. • ‘%’, ‘#’ (operadores binarios) con precedencia media, y asociativos por la derecha. • ‘@’, ‘!’ (operadores binarios) con la más alta precedencia, y asociativos por la izquierda. • Paréntesis sobrellevan la precedencia y la associatividad.

Precedencia y Asociatividad de Operadores Gramática: E 0 → E 0 & E 1 → E 0 ¢ E 1 → E 0 * E 1 → E 2 % E 1 → E 2 # E 1 → E 2 @ E 3 → E 2 ! E 3 → (E 0) →i

Precedencia y Asociatividad de Operadores Ejemplo: Construir el árbol de derivación para: i & i @ i # i ¢ ( i * i & i ! i) % ( i & i ) # i @ i

Árbol de Derivación

Gramáticas de Traducción Definición: Una gramática de traducción (o esquema de traducción dirigido por sintaxis) es como una GLC, pero con la siguiente generalización: Cada producción es una tupla (A, β, ω) Ф x V*, llamada una regla de traducción, denotada A → β => ω, donde A es la parte izquierda, β es la parte derecha, y ω es la parte de traducción.

Gramáticas de Traducción Ejemplo: Traducción de infijo a postfijo para expresiones. E→E+T →T T→P*T →P P → (E) →i => => => ET+ T PT* P E Nota: ()’s se eliminan i La parte de traducción describe cómo se genera la salida, conforme se deriva la entrada.
, donde y β son")
Gramáticas de Traducción Se deriva un par ( , β), donde y β son las formas sentenciales de la entrada y salida. => => ( ( ( ( E, E + T + P + i + i + T, T, P * T, i * i, E E T P i i ) T T P + + T i i ) ) * + ) T * + ) i * + )

Traducción de Hileras a Árboles Notación: < N t 1 … tn > denota N t 1 … tn Gramática de traducción de hileras a árboles: E→E+T →T T→P*T →P P → (E) →i => => => <+ET> T <*PT> P E i
 (E + T, (T")
Traducción de Hileras a Árboles Ejemplo: => => (E, E) (E + T, (T + T, (P + T, (i + P * (i + i * + T, T, P, i, < < < < + + + + E T P i i i T T < < >) i * >) >) i i >) * P T > >) * i P > >) * i i > >)

Gramáticas de Traducción Definición: Una gramática de traducción es simple si para cada regla A → => β, la secuencia de noterminales en es idéntica a la secuencia que aparece en β. Ejemplo: E→E+T →T T→P*T →P P → (E) →i => => => <+ET> T <*PT> P E i

Traducción de Hileras a Árboles Si la gramática es simple, eliminamos los noterminales y la notación de árboles en las partes de traducción: E → E + T => + →T T → P * T => * →P P → (E) →i => i Suena familiar ? Notación del TWS

Árboles de Sintaxis Abstracta • ASA es una versión condensada del árbol de derivación. • Sin “ruido” (nodos intermedios). • Es el resultado de usar una gramática de traducción de hilera-a-árbol. • Reglas de la forma A → ω => 's'. • Se construye un nodo 's', con un hijo por cada símbolo no-terminal en ω. • Traducimos del vocabulario de entrada (símbolos en ω), al vocabulario de nombres de nodos del árbol (e. g. ‘s’)

Ejemplo de ASA Entrada: : - + i - i * ( i + i ) / i + i Árbol de Derivación ASA: G:

El Juego de Dominó Sintáctico • La gramática: E → E+T → T T → P*T → P P → (E) →i • Las piezas de juego: Una cantidad ilimitada de cada pieza. Una pieza por cada regla en la gramática. • El tablero de juego: • El dominó inicial arriba. • Los dominós abajo son la hilera de entrada.
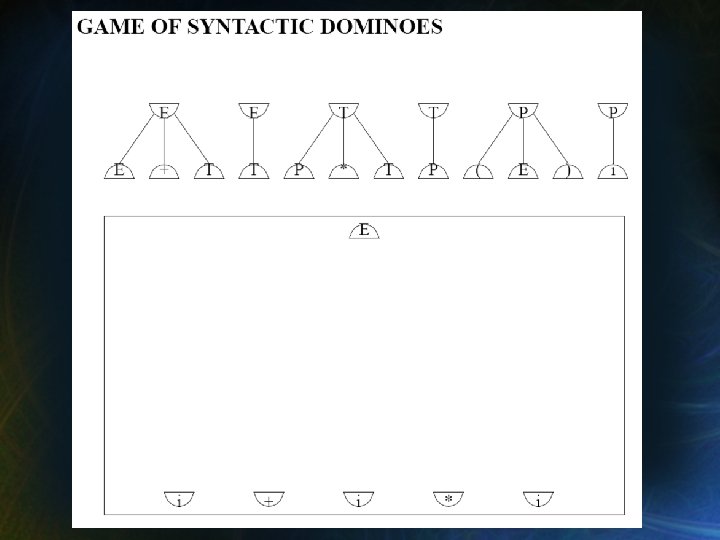

El Juego de Dominó Sintáctico • Reglas del juego: – Se agregan piezas al tablero. – Deben coincidir las partes planas, y los símbolos. – Las líneas son infinitamente elásticas, pero no se pueden cruzar. • Objetivo del juego: – Conectar el dominó de inicio con los dominós de entrada. – Que no sobren partes.

Estrategias de Análisis Sintáctico • Las mismas que para el juego de dominó sintáctico. – Descendente (“top-down”): se comienza con el dominó inicial, se trabaja hacia la hilera de entrada. – Ascendente (“bottom-up”): se comienza con la hilera de entrada, se trabaja hacia el dominó inicial. • En ambas estrategias, se puede procesar la entrada de izquierda-a-derecha , o de derecha-a-izquierda .

Análisis Sintáctico Descendente • Se intenta una derivación izquierda, prediciendo la regla que hará coincidir lo queda de la hilera de entrada. • Se usa una hilera (una pila, en realidad) de la cual se pretende derivar la hilera de entrada.

Análisis Sintáctico Descendente • Se comienza con S en la pila. • A cada paso, dos alternativas: 1) (la pila) comienza con un símbolo terminal t. Debe coincidir con el siguiente símbolo de entrada. 2) comienza con un símbolo no-terminal A. Se consulta con un oráculo FOP (Función Omnisciente de Parsing) para determinar cuál producción de A llevaría a coincidir con el siguiente símbolo de entrada. • La FOP es la parte “predictiva” del analizador.

; while not Empty (Stack) do")
Algoritmo Clásico de Análisis Sintáctico Descendente Push (Stack, S); while not Empty (Stack) do if Top(Stack) then if Top(Stack) = Head(input) then input : = tail(input) Pop(Stack) else error (Stack, input) else P: = OPF (Stack, input) Push (Pop(Stack), RHS(P)) od if (not empty(input)) then error

Análisis Sintáctico Descendente • La mayoría de los métodos imponen cotas al número de símbolos de la pila y de la hilera de entrada, que se usan para escoger la producción. Para los lenguajes de programación, la escogencia común es (1, 1). • Debemos definir FOP (A, t), donde A es el primer símbolo en la pila, y t es el primer símbolo de la entrada. • Requerimientos de almacenamiento: O(n 2), donde n es el tamaño del vocabulario de la gramática, ≈ O(1002).
 = A → ω si")
Análisis Sintáctico Descendente A… ω t… FOP (A, t) = A → ω si 1. ω =>* t , para algún , 2. ω =>* ε, y S =>* A t , para algunos ó , , donde =>* ε.
: S→A A → BAd →C B→b C→c FOP")
Análisis Sintáctico Descendente Ejemplo (ilustrando 1): S→A A → BAd →C B→b C→c FOP b c B→b C→c S→A A→C d B→b C→c S→A ? ? ? B C S A B→b C→c S→A A → BAd Elementos de color café son opcionales. También el elemento ? ? ? OPF (A, b) = A → BAd porque BAd =>* b. Ad OPF (A, c) = A → C porque C =>* c i. e. , B comienza con b, y C comienza con c.
: OPF b S A S→A A → b.")
Análisis Sintáctico Descendente Ejemplo (ilustrando 2): OPF b S A S→A A → b. Ad S→A d A→ S→A A→ A → b. Ad → OPF (S, b) = S → A , porque A =>* b. Ad OPF (S, d) = -------, porque S =>* αS dβ OPF (S, ) = S → A , porque S es legal OPF (A, b) = A → b. Ad , porque A =>* b. Ad OPF (A, d) = A → , porque S =>* b. Ad OPF (A, ) = A → , porque S =>*A
 = {t / A =>* t , para")
Análisis Sintáctico Descendente Definición: First (A) = {t / A =>* t , para algún } Follow (A) = {t / S =>* Atβ, para algún , β} Cálculo de Conjuntos First: 1. Construir grafo (Ф, δ), donde (A, B) δ si B → A , =>* ε (i. e. First(A) First(B)) 2. Agregar a cada nodo un conjunto vacío de terminales. 3. Agregar t a First(A) si A → t , =>* ε. 4. Propagar los elementos de los conjuntos a lo largo de las aristas del grafo.

Análisis Sintáctico Descendente Ejemplo: {a, b} S → ABCD A → CDA B → BC →a →b → S B {b} C→A D → AC Anulables = {A, C, D} Paso 1: Grafo {a} A C {a} Paso 2: Conjuntos { } Paso 3: Agregar t D {a} Paso 4: Propagar
, donde (A,")
Análisis Sintáctico Descendente Cálculo de Conjuntos Follow: 1. Construir grafo (Ф, δ), donde (A, B) δ si A → B , =>* ε. Follow(A) Follow(B), porque cualquier símbolo X que sigue después de A, también sigue después de B, porque A puede terminar en B. A α B X ε

Análisis Sintáctico Descendente 2. Agregar a cada nodo un conjunto vacío de terminales. Agregar a Follow(S). 3. Agregar First(X) a Follow(A) si B → A X , =>* ε. Nota: First(t)={t}. 4. Propagar los elementos de los conjuntos a lo largo de las aristas del grafo.

Análisis Sintáctico Descendente Ejemplo: S → ABCD B → BC →b A → CDA C→A → a. D → AC → Nullable = {A, C, D} {┴ } S B {a , ┴ } A C {a , b, ┴ } {a, b, ┴ } D {a , b, ┴} First(S) = {a, b} First(C) = {a} First(A) = {a} First(D) = {a} First(B) = {b} Blanco: Paso 3 Café: Paso 4
 = { } Follow(A) = Follow(C) = Follow(D) =")
Análisis Sintáctico Descendente Resumiendo, Follow(S) = { } Follow(A) = Follow(C) = Follow(D) = {a, b, } Follow(B) = {a, }
 = A")
Análisis Sintáctico Descendente Regresando al análisis sintáctico … Deseamos que OPF(A, t) = A → ω si 1. t First(ω), i. e. ω =>* tβ Aα ω ó 2. ω =>* ε and t Follow(A), i. e. S =>* A => * Atβ t β Aα ω ε t β
 = First(ω) U if ω =>* ε")
Análisis Sintáctico Descendente Definición: Select (A→ ω) = First(ω) U if ω =>* ε then Follow(A) else ø Así, PT(A, t) = A → ω si t Select(A → ω) “Parse Table” (PT), en lugar de FOP, porque ya no es omnisciente.
 = {a, b} (A) = {a} (B)")
Análisis Sintáctico Descendente Ejemplo: First First (S) = {a, b} (A) = {a} (B) = {b} (C) = {a} (D) = {a} Follow (S) Follow(A) Follow(B) Follow (C) Follow(D) Gramática Conjuntos Select S → ABCD B → BC →b A → CDA →a → C→A D → AC {a, b} {b} {a, b, } {a, b, } = {a, b, } = {a, b, } No disjuntos por parejas Gramática NO es LL(1)
: elementos múltiples en PT. S → ABCD B →")
Análisis Sintáctico Descendente Gramática no-LL(1): elementos múltiples en PT. S → ABCD B → BC →b A → CDA →a → S A B C D {a, b} {b} {a, b, } a S → ABCD A → CDA, A→ a, A → C→A D → AC C → A {a, b, } D → AC {a, b, } b S → ABCD A → CDA, A → BC, B → b C→A D → AC ┴ A → CDA, A → C→A D → AC
 • Definición: Una GLC G es LL(1) ( Left-to-right, Left-most, (1)-symbol lookahead)")
Gramáticas LL(1) • Definición: Una GLC G es LL(1) ( Left-to-right, Left-most, (1)-symbol lookahead) sii pata todo A�Ф, y para todo par de producciones A→ , A → con , Select (A → ) ∩ Select (A → ) = • Ejemplo previo: gramática no es LL(1). • Qué hacer ? Más tarde.
 S→A {b, } A → b. Ad {b} → {d,")
Ejemplo de gramática LL(1) S→A {b, } A → b. Ad {b} → {d, } d S A A→ Disjuntos! Gramática es LL(1) ! b S→ A S→A A → b. Ad A→ A lo sumo una producción en cada posición de la tabla.

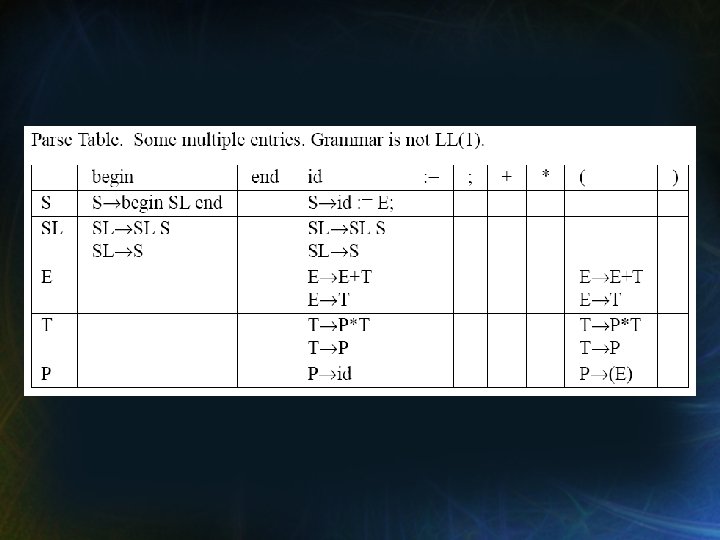
Ejemplo • Construir la tabla de análisis sintáctico para la siguiente gramática. → → SL → → E → → T → → P → → S begin SL end {begin} id : = E; {id} SL S {begin, id} * S {begin, id} E+T {(, id} * T {(, id} P*T {(, id} * P {(, id} (E) {(} * No es LL(1) id {id}
 • Lemma: Rescursividad izquierda siempre produce una gramática no-LL(1) (e. g. ,")
Ejemplo (cont’d) • Lemma: Rescursividad izquierda siempre produce una gramática no-LL(1) (e. g. , SL, E) • Prueba: Considere A → A First ( ) or Follow (A) → First ( ) Follow (A)

Problemas con nuestra Gramática 1. SL tiene recursividad izquierda. 2. E tiene recursividad izquierda. 3. T → P * T comienzan con una → P secuencia en común (P).

Solución al Problema 3 • Cambiar: T → P * T → P { (, id } • a: { (, id } {*} { +, ; , ) } Follow(X) Follow(T) Follow(E) = { +, ; , ) } T→PX X→*T → Disjuntos! porque T → P X porque E → E+T , E → T porque E → E+T, S → id : = E ; y P → (E)
 • En general, cambiar A → 1 → 2.")
Solución al Problema 3 (cont’d) • En general, cambiar A → 1 → 2. . . → n a A→ X X → 1. . . → n Con suerte, todos los ’s comienzan con símbolos distintos
…) •")
Solución a los Problemas 1 y 2 • Queremos (…((( T + T)…) • En su lugar, (T) (+T) … (+T) Cambiar: a: E→E+T → T E→ TY Y→ +TY → Follow(Y) Follow(E) ={; , )} { (, id } {+} { ; , )} Ya no contiene ‘+’, porque eliminamos la producción E → E + T
 • En general, Cambiar: a A")
Solución a los Problemas 1 and 2 (cont’d) • En general, Cambiar: a A → A 1. . . → A n A→ 1. . . → m A → 1 X. . . → m X X → 1 X. . . → n X →
 • En nuestro ejemplo, Cambiar: a:")
Solución a los Problemas 1 and 2 (cont’d) • En nuestro ejemplo, Cambiar: a: SL → SL S { begin, id } → S { begin, id } SL → S Z Z→SZ → { begin, id } { end }

Gramática Modificada → → SL → Z → → E → Y → → T → X → → P → → S begin SL end id : = E ; S Z T Y + T Y P X * T (E) id {begin} {id} {begin, id} {end} (, id} {+} {; , )} {(, id} {*} {; , +, )} {(} {id} Disjuntos. La gramática es LL(1)


. • Una rutina")
Parsing de Descenso Recursivo • Estrategia descendente, apropiada para geramáticas LL(1). • Una rutina por cada no-terminal. • Contenido de pila embebido en la secuencia de llamadas recursivas. • Cada rutina escoge y recorre una producción, basado en el siguiente símbolo de entrada, y los conjuntos Select. • Buena técnica para escribir un analizador sintáctico a mano.

Parsing de Descenso Recursivo S; {S → begin SL end → id : = E; } “Read (T_X)” case Next_Token of verifica que el T_begin : Read(T_begin); siguiente token SL; es X, y lo Read (T_end); consume. T_id : Read(T_id); Read (T_: =); E; “Next_Token” Read (T_; ); es el siguiente otherwise Error; token. end; proc

Parsing de Descenso Recursivo proc SL; {SL → SZ} S; Técnicamente, debimos insistir que Z; Next_Token fuera T_begin o T_id, pero S hará eso de todas maneras. end; Revisión temprana ayuda en la recuperación de errores. proc E; {E → TY} T; Y; Lo mismo para T_( y T_id. end;

Parsing de Descenso Recursivo proc Z; {Z → SZ → } case Next Token of T_begin, T_id: S; Z; T_end: ; otherwise Error; end;

Parsing de Descenso Recursivo proc Y; {Y → +TY Se puede usar un ‘case’ → } if Next Token = T_+ then Read (T_+) T; Y; end; proc T; {T P; X end; → PX} Se pudo haber insistido que Next_Token fuera T_( o T_id.

Parsing de Descenso Recursivo proc X; {X → *T → } if Next Token = T_* then Read (T_*); T; end;
 → id } case Next Token of T_(: Read")
Parsing de Descenso Recursivo →(E) → id } case Next Token of T_(: Read (T_(); E; Read (T_)); T_id: Read (T_id); otherwise Error; end; proc P; {P

Traducción hilera-a-árbol • Podemos obtener el árbol de derivación o el ASA. • El árbol puede ser generado en forma ascendente o descendente. • Mostraremos cómo obtener 1. Árbol de derivación en forma descendente. 2. ASA para la gramática original, en forma ascendente.

Generación Descendente del AD • En cada rutina, y para cada alternativa, escribir la producción escogida EN CUANTO HAYA SIDO ESCOGIDA.

Generación Descendente del AD {S → begin SL end → id : = E; } case Next_Token of T_begin : Write(S → begin SL end); Read(T_begin); SL; Read(T_end); T_id : Write(S → id : =E; ); Read(T_id); Read (T_: =); E; Read (T_; ); otherwise Error end; proc S;
; S; Z;")
Generación Descendente del AD proc SL; {SL → SZ} Write(SL → SZ); S; Z; end; proc E; {E → TY} Write(E → TY); T; Y; end;

Generación Descendente del AD proc Z; {Z → SZ → } case Next_Token of T_begin, T_id: Write(Z → SZ); S; Z; T_end: Write(Z → ); otherwise Error; end;

Generación Descendente del AD proc Y; {Y → +TY → } if Next_Token = T_+ then Write (Y → +TY); Read (T_+); T; Y; else Write (Y → ); end; proc T; {T → PX} Write (T → PX); P; X end;

Generación Descendente del AD proc X; {X → *T → } if Next_Token = T_* then Write (X → *T); Read (T_*); T; else Write (X → ); end;
 → id } case Next_Token")
Generación Descendente del AD proc P; {P → (E) → id } case Next_Token of T_(: Write (P → (E)); Read (T_(); E; Read (T_)); T_id: Write (P → id); Read (T_id); otherwise Error; end;

Notas • La colocación de las instrucciones Write es obvia precisamente porque la gramática es LL(1). • El árbol puede ser construido conforme procede el algoritmo, o puede ser construido por un post-procesador.

Generación Ascendente del AD • Pudimos haber colocado las instrucciones Write al FINAL de cada frase, en lugar del principio. De ser así, generamos el árbol en forma ascendente. • En cada rutina, y para cada alternativa, escribimos la producción escogida A → DESPUÉS de reconocer .

Generación Ascendente del AD proc S; {S → begin SL end → id : = E; } case Next_Token of T_begin: Read (T_begin); SL; Read (T_end); Write (S → begin SL end); T_id: Read (T_id); Read (T_: =); E; Read (T_; ); Write (S → id: =E; ); otherwise Error; end;
;")
Generación Ascendente del AD proc SL; {SL → SZ} S; Z; Write(SL → SZ); end; proc E; {E → TY} T; Y; Write(E → TY); end;

Generación Ascendente del AD proc Z; {Z → SZ → } case Next_Token of T_begin, T_id: S; Z; Write(Z → SZ); T_end: Write(Z → ); otherwise Error; end;

Generación Ascendente del AD proc Y; {Y → +TY → } if Next_Token = T_+ then Read (T_+); T; Y; Write (Y → +TY); else Write (Y → ); end;

Generación Ascendente del AD proc T; {T P; X; → PX } Write (T → PX) end; proc X; {X → *T → } if Next_Token = T_* then Read (T_*); T; → *T); Write (X → ); Write (X else end
 → id } case Next_Token")
Generación Ascendente del AD proc P; {P → (E) → id } case Next_Token of T_(: Read (T_(); E; Read (T_)); Write (P → (E)); T_id: Read (T_id); Write (P → id); otherwise Error; end;

Notas • La colocación de las instrucciones Write sigue siendo obvia. • Las producciones se emiten conforme las rutinas terminan, en lugar de hacerlo al empezar. • Las producciones son emitidas en orden inverso, i. e. , la secuencia de producciones debe ser utilizada en orden inverso para producir una derivación derecha. • Nuevamente, el árbol puede ser construido conforme procede el algoritmo (usando una pila de árboles), o puede ser construido por un postprocesador.
 * id;")
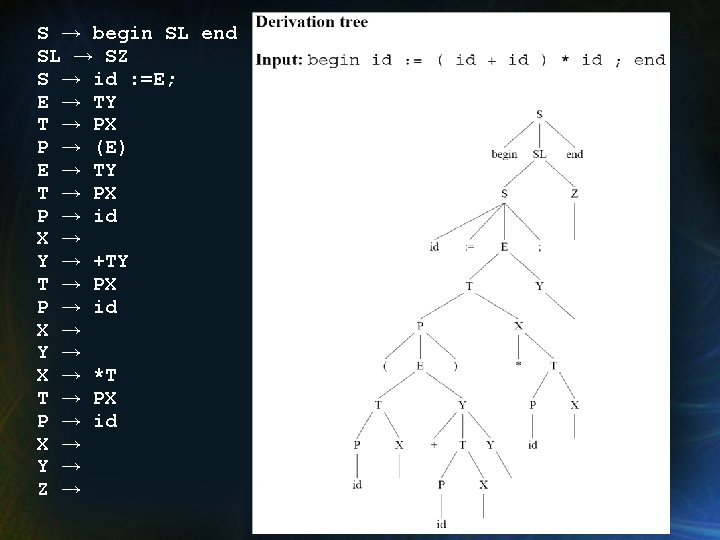
Ejemplo • Hilera de Entrada: begin id : = (id + id) * id; end • Salida: P X T Y Y E P → → → → → id P X +T Y ( E ) P → id X → T → PX X → *T T → PX Y → E → TY S → id: =E; Z → SL → SZ S → begin SL end

Recursividad vs. Iteración • No todos los símbolos no-terminales son necesarios. • La recursividad de SL, X, Y y Z se puede reemplazar con iteración.

Recursividad vs. Iteración proc S; {S → begin SL end SL →SLS Z → id : = E; Z → S Z → } case Next_Token of T_begin : Read(T_begin); repeat Reemplaza S; until Next_Token {T_begin, T_id}; llamado a SL. Read(T_end); T_id : Read(T_id); Read (T_: =); E; Reemplaza Read (T_; ); recursividad otherwise Error; end de Z, porque end; L(Z)=S*
=(+T)*. T; while Next_Token = T_+")
Recursividad vs. Iteración Reemplaza recursividad de Y, porque L(Y)=(+T)*. T; while Next_Token = T_+ do Read (T_+); T; proc E; od end; {E → TY Y → +TY → }

Recursividad vs. Iteración proc T; {T → PX X → *T → } P; if Next_Token = T_* then Read (T_*); T; end; Reemplaza llamado a X, porque L(X)=(*T)? No hay iteración, porque X no es recursivo.
 → id } case Next_Token of")
Recursividad vs. Iteración proc P; {P → (E) → id } case Next_Token of T_(: Read (T_(); E; Read (T_)); T_id: Read (T_id); otherwise Error; end;
S → begin")
Construcción Ascendente del AD, para la gramática original proc S; { (1)S → begin SL end (2)S → begin SL end → id : = E; SL → SZ SL → SL S Z → S → } case Next_Token of T_begin: Read(T_begin); S; Write(SL → S); while Next_Token in {T_begin, T_id} do S; Write(SL → SL S); od Read(T_end); Write(S → begin SL end); end; T_id: Read(T_id); Read (T_: =); E; Read (T_; ); Write(S → id : =E; ); otherwise Error;
E → TY (2)")
Construcción Ascendente del AD, para la gramática original proc E; {(1)E → TY (2) E → E+T Y → +TY → T → } T; Write (E → T); while Next_Token = T_+ do Read (T_+); T; Write (E → E+T); od end while, porque Y es recursivo
T → PX (2)")
Construcción Ascendente del AD, para la gramática original proc T; {(1)T → PX (2) T → P*T X → *T → P → } P; if Next_Token = T_* then Read (T_*); T; Write (T → P*T) else Write (T → P); end; if, porque X no es recursivo
P → (E) (2)P")
Construcción Ascendente del AD, para la gramática original proc P; {(1)P → (E) (2)P → (E) → id } // end; IGUAL QUE ANTES

P → id T → P E → T P → id T → P E → E+T P → (E) P → id T → P*T E → T S → id: =E; SL→ S S → begin SL end

Generación ascendente del ASA, para la gramática original proc S; { S → begin S+ end 'block' → id : = E; 'assign' var N: integer; case Next_Token of T_begin : Read(T_begin); S; Build Tree (‘x’, n) N: =1; saca n árboles de la while Next_Token in {T_begin, T_id} do S; pila, construye un N: =N+1; nodo ‘x’ como su od padre, y entra el Read(T_end); árbol resultante en Build Tree ('block', N); T_id : Read(T_id); la pila. Asumimos que se Read (T_: =); E; construye un nodo. Read (T_; ); Build Tree ('assign', 2); otherwise Error end;

Generación ascendente del ASA, para la gramática original proc E; {E → E+T '+' → T } T; while Next_Token = T_+ do Read (T_+) T; Build Tree ('+', 2); od end; Ramificación izquierda en el árbol !

Generación ascendente del ASA, para la gramática original proc T; {T → P*T '*' → P } P; if Next_Token = T_* then Read (T_*) T; Build Tree ('*', 2); end; Ramificación derecha en el árbol !
 →")
Generación ascendente del ASA, para la gramática original proc P; {P → (E) → id } // IGUAL QUE ANTES, // i. e. , no se construye árbol // encima de E o id. end;

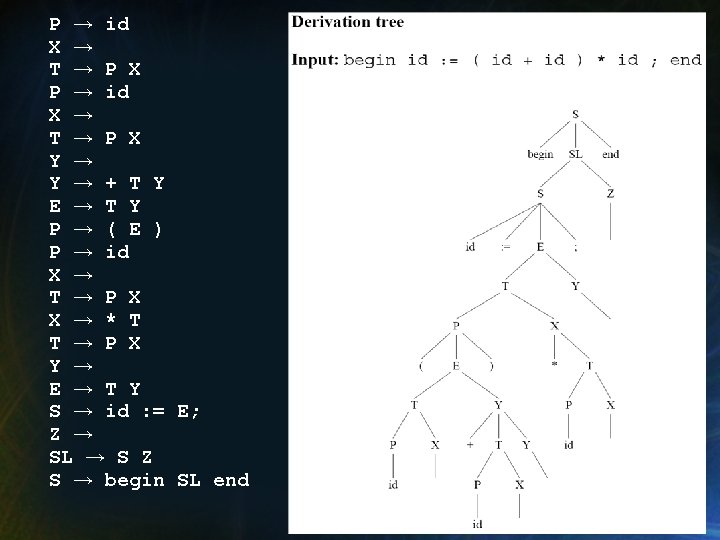
Ejemplo • Hilera de Entrada: begin id 1 : = (id 2 + id 3) * id 4; end • Secuencia de eventos: id 1 id 4 id 2 BT('*', 2) id 3 BT('assign', 2) BT('+', 2) BT('block', 1)


Resumen • Construcción ascendente o descendente del árbol deseado. • Gramática original o modificada. • Árbol de derivación, o árbol de sintaxis abstracta. • Técnica de escogencia: – Parser de descenso recursivo, – Construcción ascendente del ASA, para la gramática original.

Parsing LR • Las rutinas en el parser de descenso recursivo pueden ser “anotadas” con “items”. • Item: una producción con un marcador “. ” en la parte derecha. • Podemos usar los “items” para describir la operación del parser de descenso recursivo. • Existe un NFA (un estado por cada item) que describe todas las secuencias de llamadas en el código de descenso recursivo.

Parser de Descenso Recursivo con items Ejemplo: proc E; {E →. E + T, T E →. T} T T; {E → E. + T, E → T. } while Next_Token = T_+ do {E → E. + T} + Read(T_+); {E → E +. T } T; {E → E + T. } od {E → E + T. end; E → T. } T

NFA que conecta items NFA: M = (PP, V, , S’ →. S , { S’ → S. }) PP: conjunto de todos los items posibles (PP: producciones con punto), y se define tal que 1 A → α. Bβ B→. ω simula un llamado a B 2 A → α. Xβ X A→ X. β simula la ejecución de la rutina X, si X es no-terminal, o Read(X), si X es un terminal.
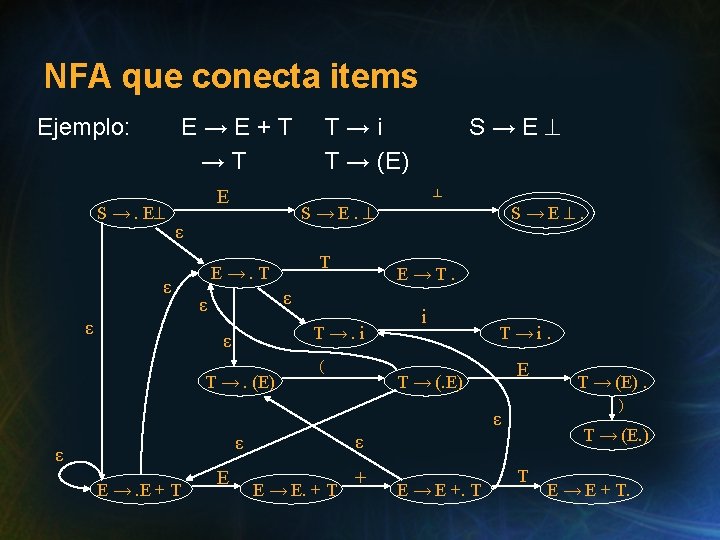

NFA que conecta items • Hay que usar esta máquina con una pila (la secuencia de llamadas recursivas). • Para “regresar” de A → ω. , retrocedemos |ω| + 1 estados, y avanzamos sobre A. • Problema de esta máquina: es no-determnística. No problem. Be happy . Transformémosla a una DFA !
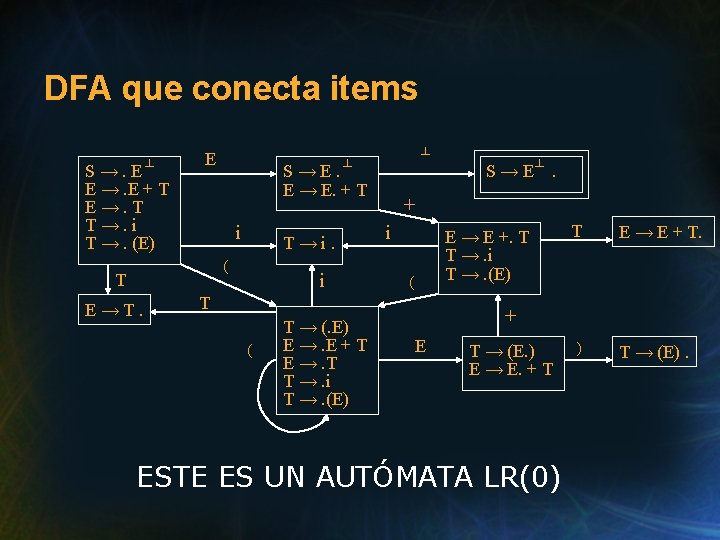

Parsing LR • LR significa “Left-to-Right, Right-most Derivation”. • Necesitamos una pila de estados para operar el parser. • Se requieren 0 símbolos de “look-ahead”, por lo que se denomina LR(0). • El DFA describe todas las posiciones posibles en el código de descenso recursivo. • Una vez construido el automáta, se pueden descartar los items (como siempre con NFA →DFA).

Parsing LR Operación de un parser LR Dos movimientos: “shift” y “reduce”. • Shift: Avanzar desde el estado actual sobre Next_Token, y agregar el estado nuevo a la pila. • Reduce: (sobre A → ω). Remover |ω| estados de la pila. Avanzar desde el nuevo estado, sobre A.

Parsing LR E→T T 1 3 ( E T i 2 + ┴ 4 T→i i 6 ( i 5 E ( 7 + 8 ) T 9 E → E+T 10 T → (E) Pila 1 14 13 12 12754 12753 1275874 1275879 12758 10 1279 12 126 Entrada i + (i + i) ┴ (i + i) ┴ + i) ┴ )┴ )┴ )┴ Árbol de. Derivación i+(i+i) T E E ┴ T ┴ ┴ ----- E T

Parsing LR Representación de Parsers LR Dos Tablas: • Acción: indexada por estado y símbolo terminal. Contiene los movimientos “shift” y “reduce”. • GOTO: indexada por estado y símbolo noterminal. Contiene las transiciones sobre símbolos no-terminales.

Parsing LR ACCIÓN Ejemplo: i E→T T 1 3 ( E 2 + ┴ ( 4 T→i i 6 5 i E ( 7 + 8 9 E → E+T 10 T → (E) ( ) ┴ S/5 S/7 R/E→T R/E→T 4 R/T→ i R/T→ i 5 S/4 6 Accept 7 S/4 9 10 S/5 Accept E T 2 3 8 3 S/6 3 8 ) T S/4 2 T i 1 + GOTO Accept S/5 S/7 9 S/10 R/ E →E+T R/ E →E+T R/ T → (E) R/ T → (E)
; while ACTION (Top(S), ) ≠ Accept do case")
Parsing LR Algoritmo Driver_LR: Push(Start_State, S); while ACTION (Top(S), ) ≠ Accept do case ACTION (Top(S), Next_Token) of Shift/r: Read(Next_Token); Push(r, S) Reduce/A → ω: Pop(S) |ω| veces; Push(GOTO (Top(S), A), S); empty: Error; end;
: • PT(G) = Closure({S’ →. S })")
Parsing LR Construcción Directa del Autómata LR(0): • PT(G) = Closure({S’ →. S }) U {Closure(P) | P Successors(P’), P’ PT(G)} • Closure(P) = P U {A →. w | B → α. Aβ Closure(P)} • Successors(P) = {Nucleus(P, X) | X V} • Nucleus(P, X) = {A → αX. β | A → α. Xβ P}
 S→E Construcción Directa del Autómata LR(0)")
E→E+T →T Parsing LR T→i T → (E) S→E Construcción Directa del Autómata LR(0) previo 1 S →. E ┴ E 2 E →. E + T E 2 E →. T T 3 T →. i i 4 T →. (E) ( 5 2 S → E. ┴ E → E. + T 3 E → T. 4 T → i. ┴ + 6 7 5 T → (. E) E 8 E →. E + T E 8 E →. T T 3 T →. i i 4 T →. (E) ( 5 6 S → E. 7 E → E +. T i T →. (E) T ( 9 4 5 8 9 T → (E. ) ) 10 E → E. + T + 7 E → E + T. 10 T → (E).
 porque no tiene “conflictos”. • Un")
Parsing LR Notas: • Esta gramática es LR(0) porque no tiene “conflictos”. • Un conflicto ocurre cuando un estado contiene a. Conflicto shift-reduce: un item final (A → ω. ) y un item no-final (A → α. β), o b. Conflicto reduce-reduce: Dos o más items finales (A → ω. y B → ω. ).


Parsing LR El conflicto aparece en la table ACCIÓN, como entradas múltiples. + 1 2 3 4 5 6 7 8 9 10 11 12 13 S/8 R/E→T R/T→P R/P→i * i S/5 ( S/6 ) S/7 S/9, R/T→P S/5 S/6 Accept S/8 R/E→E+T R/T→P*T R/P→(E) ┴ S/13 A C C I Ó N

Parsing LR Solución: Utilizar “lookahead”, tomando en cuenta el siguiente símbolo de entrada en la decisión de parsing. • En LL(1), lookahead se usa al principio de la producción. • En LR(1), lookahead se usa al final de la producción. Usaremos: SLR(1) – Simple LR(1) LALR(1) – Look. Ahead LR(1)
: Calculamos Follow(A) para cada producción A →ω que causa un conflicto.")
Parsing LR SLR(1): Calculamos Follow(A) para cada producción A →ω que causa un conflicto. Luego, se coloca “R/A → ω” en ACCIÓN[p, t] solo si t Follow(A). Aquí, Follow(T) Follow(E) = {+, ), }. + 4 (antes) R/T→P 4 (después) R/T→P * S/9, R/T→P S/9 i R/T→P ( R/T→P ) R/T→P Problema resuelto. La gramática es SLR(1) ┴ R/T→P

Parsing LR Ejemplo: 1 S’ →. S ┴ S →. a. Sb S→. S’ → S. ┴ 2 3 S → a. Sb S →. a. Sb S→. S’ → S ┴. 4 5 S → a. S. b 6 S → a. Sb → S 2 a 3 ┴ S a 4 1 {anbn/ n > 0} S S→ a 3 a ┴ 2 S b 5 6 S → a. Sb S→ 5 3 a 1 6 La gramática no es LR(0) S/3 R/S→ b 4 R/S→ S/4 S/3 R/S→ 5 R/S→ Accept 5 6 2 2 3 b 4 S/6 R/S→a. Sb
: Estado 1: Follow(S)={b, }. Ya que a Follow(S), el conflicto")
Parsing LR Análisis SLR(1): Estado 1: Follow(S)={b, }. Ya que a Follow(S), el conflicto shift/reduce queda resuelto. Estado 3: La misma historia. Las filas 1 y 3 resultantes: 1 3 a b ┴ S S/3 R/S → 2 5 Conflictos resueltos. La gramática es SLR(1).
 Ejemplo: Autómata LR(0): S 1 A S → Ab. Aa")
Parsing LR Gramáticas LALR(1) Ejemplo: Autómata LR(0): S 1 A S → Ab. Aa → Ba 2 6 3 b 7 a A B 4 a a 5 A→a B→a 8 10 9 A→a B→ a A→a a 11 A → Ab. Aa S → Ba Conflicto reduce-reduce. La gramática no es LR(0).
: a b ┴ 5 R/A→a, R/B→a La gramática no es")
Parsing LR Análisis LR(0): a b ┴ 5 R/A→a, R/B→a La gramática no es LR(0). Análisis SLR(1): Follow(A)={a, b}, Follow(B)={a} 5 a R/A→a, R/B→a No disjuntos. Conflicto no resuelto. b R/A→a La gramática no es SLR(1). ┴
: I. Para cada reducción conflictiva A → ω en cada")
Parsing LR Técnica LALR(1): I. Para cada reducción conflictiva A → ω en cada estado inconsistent q, hayar todas las transiciones no-terminales (pi, A) tales que p 1 ω A q A→ω pn II. Calcular Follow(pi, A) (ver abajo), para todo i, y unir los resultados. El conjunto que resulta es el conjunto de “lookahead” LALR(1) para la reducción A → ω en q.
: Es el cálculo ordinario Follow, en otra gramática,")
Parsing LR Cálculo de Follow(p, A): Es el cálculo ordinario Follow, en otra gramática, llamada G’. Para cada transición (p, A), y cada producción A→w 1 w 2…wn, tenemos p A w 1 p 2 w 2 p 3 Wn W … n-1 p n A → w 1…wn En esta situación, G’ contiene esta producción: (p, A) → (p, w 1)(p 2, w 2)…(pn, wn) G’: Consiste de las transiciones en el autómata LR(0). Refleja la estructura de G, y la del autómata LR(0).

Parsing LR En nuestro ejemplo: S 1 A 2 3 G: S → Ab. Aa A → a → Ba B→a 6 b a 7 A B 4 a a 5 A→a B→a Estos se separaron 8 ! 10 9 A→a a 11 A → Ab. Aa S → Ba G’: (1, S) → (1, A)(3, b)(7, A)(9, a) → (1, B)(4, a) (1, A) → (1, a) (7, A) → (7, A) (1, B) → (1, a)
 = {(3,")
Parsing LR Para el conflicto en el estado 5, necesitamos Follow(1, A) = {(3, b)} Follow(1, B) = {(4, a)}. Se extraen los símbolos terminales: a a 5 R/B → a b R/A → a 5 A → a {b} B → a {a} ┴ Conflicto resuelto. La gramática es LALR(1).

Parsing LR Ejemplo: S → b. Bb → a. Ba → acb 1 Autómata LR(0): S b a 2 3 4 B→A A→c 5 c B A A B c Estado 10 es inconsistente (conflicto shift-reduce). 8 6 7 9 10 A→c b 11 S → b. Bb 12 13 S → a. Ba B→A A→c a b S → acb La gramática no es LR(0)
, estado 10: Follow(A) Follow(B) ={a, b}. La gramática no es")
Parsing LR Análisis SLR(1), estado 10: Follow(A) Follow(B) ={a, b}. La gramática no es SLR(1). Análisis LALR(1): Se necesita Follow(4, A). G’: (1, S) → (1, b)(3, B)(6, b) → (1, a)(4, B)(9, a) → (1, a)(4, c)(10, b) (3, (4, B) B) B) A) → → (3, (4, A) A) c) c) Así, Follow(4, A) Follow(4, B) = {(9, a)}. El conjunto lookahead es {a}. La gramática es LALR(1).
: • Escrito a mano o dirigido por tabla: LL(1)")
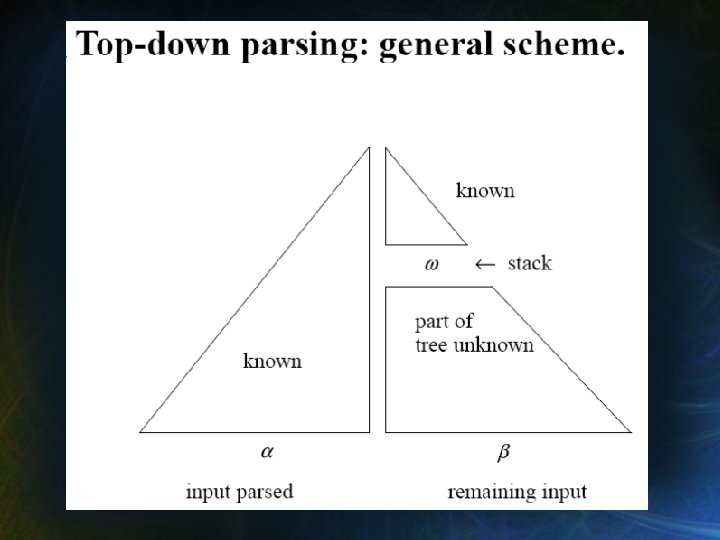
Resumen de Parsing Descendente (top-down): • Escrito a mano o dirigido por tabla: LL(1) S Parte conocida pila w Parte por predecir α β Entrada procesada Entrada por procesar
: • Dirigida por tabla: LR(0), SLR(1), LALR(1). S Parte")
Resumen de Parsing Ascendente (bottom-up): • Dirigida por tabla: LR(0), SLR(1), LALR(1). S Parte conocida pila Parte desconocida w Parte conocida α β Entrada procesada Entrada por procesar

Lenguajes Libres de Contexto Curso de Compiladores Preparado por Manuel E. Bermúdez, Ph. D. Profesor Asociado University of Florida
- Slides: 154