Lectures for 3 rd Edition Note these lectures


 — conventions define relationship")



 0111 0110")

 occurs – Control jumps to")



 • We need a way to represent – numbers")


 • In addition")




 — How long does it take")



 you can")



















 • Let's build an ALU to support the andi")



 ? • • Two's complement approach: just negate")

")














 –")







 • Controlling the")


 Ó 2004 Morgan Kaufmann Publishers 78")






![Breaking down an instruction • ISA definition of arithmetic: Reg[Memory[PC][15: 11]] <= Reg[Memory[PC][25: 21]]](https://slidetodoc.com/presentation_image/43c3557bce0e877efdee5895e045c0ff/image-85.jpg "Breaking down an instruction • ISA definition of arithmetic: Reg[Memory[PC][15: 11]] <= Reg[Memory[PC][25: 21]]")




 • ALU is performing one of three functions, based on")
![Step 4 (R-type or memory-access) • Loads and stores access memory MDR <= Memory[ALUOut];](https://slidetodoc.com/presentation_image/43c3557bce0e877efdee5895e045c0ff/image-91.jpg "Step 4 (R-type or memory-access) • Loads and stores access memory MDR <= Memory[ALUOut];")
![Write-back step • Reg[IR[20: 16]] <= MDR; Which instruction needs this? Ó 2004 Morgan](https://slidetodoc.com/presentation_image/43c3557bce0e877efdee5895e045c0ff/image-92.jpg "Write-back step • Reg[IR[20: 16]] <= MDR; Which instruction needs this? Ó 2004 Morgan")



















")


- Slides: 115
Lectures for 3 rd Edition Note: these lectures are often supplemented with other materials and also problems from the text worked out on the blackboard. You’ll want to customize these lectures for your class. The student audience for these lectures have had exposure to logic design and attend a hands-on assembly language programming lab that does not follow a typical lecture format. Ó 2004 Morgan Kaufmann Publishers 1
Chapter Three Ó 2004 Morgan Kaufmann Publishers 2
Numbers • • Bits are just bits (no inherent meaning) — conventions define relationship between bits and numbers Binary numbers (base 2) 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001. . . decimal: 0. . . 2 n-1 Of course it gets more complicated: numbers are finite (overflow) fractions and real numbers negative numbers e. g. , no MIPS subi instruction; addi can add a negative number How do we represent negative numbers? i. e. , which bit patterns will represent which numbers? Ó 2004 Morgan Kaufmann Publishers 3
Possible Representations • Sign Magnitude: 000 = +0 001 = +1 010 = +2 011 = +3 100 = -0 101 = -1 110 = -2 111 = -3 • • One's Complement Two's Complement 000 = +0 001 = +1 010 = +2 011 = +3 100 = -3 101 = -2 110 = -1 111 = -0 000 = +0 001 = +1 010 = +2 011 = +3 100 = -4 101 = -3 110 = -2 111 = -1 Issues: balance, number of zeros, ease of operations Which one is best? Why? Ó 2004 Morgan Kaufmann Publishers 4
MIPS • 32 bit signed numbers: 0000 0000 two = 0 ten 0000 0000 0001 two = + 1 ten 0000 0000 0010 two = + 2 ten. . . 0111 1111 1111 1110 two = + 2, 147, 483, 646 ten 0111 1111 1111 two = + 2, 147, 483, 647 ten 1000 0000 0000 two = – 2, 147, 483, 648 ten 1000 0000 0000 0001 two = – 2, 147, 483, 647 ten 1000 0000 0000 0010 two = – 2, 147, 483, 646 ten. . . 1111 1111 1101 two = – 3 ten 1111 1111 1110 two = – 2 ten 1111 1111 two = – 1 ten maxint minint Ó 2004 Morgan Kaufmann Publishers 5
Two's Complement Operations • Negating a two's complement number: invert all bits and add 1 – remember: “negate” and “invert” are quite different! • Converting n bit numbers into numbers with more than n bits: – MIPS 16 bit immediate gets converted to 32 bits for arithmetic – copy the most significant bit (the sign bit) into the other bits 0010 -> 0000 0010 1010 -> 1111 1010 – "sign extension" (lbu vs. lb) Ó 2004 Morgan Kaufmann Publishers 6
Addition & Subtraction • Just like in grade school (carry/borrow 1 s) 0111 0110 + 0110 - 0101 • Two's complement operations easy – subtraction using addition of negative numbers 0111 + 1010 • Overflow (result too large for finite computer word): – e. g. , adding two n-bit numbers does not yield an n-bit number 0111 + 0001 note that overflow term is somewhat misleading, 1000 it does not mean a carry “overflowed” Ó 2004 Morgan Kaufmann Publishers 7
Detecting Overflow • • No overflow when adding a positive and a negative number No overflow when signs are the same for subtraction Overflow occurs when the value affects the sign: – overflow when adding two positives yields a negative – or, adding two negatives gives a positive – or, subtract a negative from a positive and get a negative – or, subtract a positive from a negative and get a positive Consider the operations A + B, and A – B – Can overflow occur if B is 0 ? – Can overflow occur if A is 0 ? Ó 2004 Morgan Kaufmann Publishers 8
Effects of Overflow • • • An exception (interrupt) occurs – Control jumps to predefined address for exception – Interrupted address is saved for possible resumption Details based on software system / language – example: flight control vs. homework assignment Don't always want to detect overflow — new MIPS instructions: addu, addiu, subu note: addiu still sign-extends! note: sltu, sltiu for unsigned comparisons Ó 2004 Morgan Kaufmann Publishers 9
Multiplication • • • More complicated than addition – accomplished via shifting and addition More time and more area Let's look at 3 versions based on a gradeschool algorithm 0010 __x_1011 • (multiplicand) (multiplier) Negative numbers: convert and multiply – there are better techniques, we won’t look at them Ó 2004 Morgan Kaufmann Publishers 10
Multiplication: Implementation Datapath Control Ó 2004 Morgan Kaufmann Publishers 11
Final Version • Multiplier starts in right half of product What goes here? Ó 2004 Morgan Kaufmann Publishers 12
Floating Point (a brief look) • We need a way to represent – numbers with fractions, e. g. , 3. 1416 – very small numbers, e. g. , . 00001 – very large numbers, e. g. , 3. 15576 ´ 109 • Representation: – sign, exponent, significand: (– 1)sign ´ significand ´ 2 exponent – more bits for significand gives more accuracy – more bits for exponent increases range • IEEE 754 floating point standard: – single precision: 8 bit exponent, 23 bit significand – double precision: 11 bit exponent, 52 bit significand Ó 2004 Morgan Kaufmann Publishers 13
IEEE 754 floating-point standard • Leading “ 1” bit of significand is implicit • Exponent is “biased” to make sorting easier – all 0 s is smallest exponent all 1 s is largest – bias of 127 for single precision and 1023 for double precision – summary: (– 1)sign ´ (1+significand) ´ 2 exponent – bias • Example: – decimal: -. 75 = - ( ½ + ¼ ) – binary: -. 11 = -1. 1 x 2 -1 – floating point: exponent = 126 = 01111110 – IEEE single precision: 101111110100000000000 Ó 2004 Morgan Kaufmann Publishers 14
Floating point addition • Ó 2004 Morgan Kaufmann Publishers 15
Floating Point Complexities • Operations are somewhat more complicated (see text) • In addition to overflow we can have “underflow” • Accuracy can be a big problem – IEEE 754 keeps two extra bits, guard and round – four rounding modes – positive divided by zero yields “infinity” – zero divide by zero yields “not a number” • • – other complexities Implementing the standard can be tricky Not using the standard can be even worse – see text for description of 80 x 86 and Pentium bug! Ó 2004 Morgan Kaufmann Publishers 16
Chapter Three Summary • Computer arithmetic is constrained by limited precision • Bit patterns have no inherent meaning but standards do exist – two’s complement – IEEE 754 floating point • Computer instructions determine “meaning” of the bit patterns • Performance and accuracy are important so there are many complexities in real machines • Algorithm choice is important and may lead to hardware optimizations for both space and time (e. g. , multiplication) • You may want to look back (Section 3. 10 is great reading!) Ó 2004 Morgan Kaufmann Publishers 17
Chapter 4 Ó 2004 Morgan Kaufmann Publishers 18
Performance • • Measure, Report, and Summarize Make intelligent choices See through the marketing hype Key to understanding underlying organizational motivation Why is some hardware better than others for different programs? What factors of system performance are hardware related? (e. g. , Do we need a new machine, or a new operating system? ) How does the machine's instruction set affect performance? Ó 2004 Morgan Kaufmann Publishers 19
Which of these airplanes has the best performance? Airplane Passengers Boeing 737 -100 Boeing 747 BAC/Sud Concorde Douglas DC-8 -50 101 470 132 146 Range (mi) Speed (mph) 630 4150 4000 8720 598 610 1350 544 • How much faster is the Concorde compared to the 747? • How much bigger is the 747 than the Douglas DC-8? Ó 2004 Morgan Kaufmann Publishers 20
Computer Performance: TIME, TIME • Response Time (latency) — How long does it take for my job to run? — How long does it take to execute a job? — How long must I wait for the database query? • Throughput — How many jobs can the machine run at once? — What is the average execution rate? — How much work is getting done? • If we upgrade a machine with a new processor what do we increase? • If we add a new machine to the lab what do we increase? Ó 2004 Morgan Kaufmann Publishers 21
Execution Time • • • Elapsed Time – counts everything (disk and memory accesses, I/O , etc. ) – a useful number, but often not good for comparison purposes CPU time – doesn't count I/O or time spent running other programs – can be broken up into system time, and user time Our focus: user CPU time – time spent executing the lines of code that are "in" our program Ó 2004 Morgan Kaufmann Publishers 22
Book's Definition of Performance • For some program running on machine X, Performance. X = 1 / Execution time. X • "X is n times faster than Y" Performance. X / Performance. Y = n • Problem: – machine A runs a program in 20 seconds – machine B runs the same program in 25 seconds Ó 2004 Morgan Kaufmann Publishers 23
Clock Cycles • Instead of reporting execution time in seconds, we often use cycles • Clock “ticks” indicate when to start activities (one abstraction): time • • cycle time = time between ticks = seconds per cycle clock rate (frequency) = cycles per second (1 Hz. = 1 cycle/sec) A 4 Ghz. clock has a cycle time Ó 2004 Morgan Kaufmann Publishers 24
How to Improve Performance So, to improve performance (everything else being equal) you can either (increase or decrease? ) ____ the # of required cycles for a program, or ____ the clock cycle time or, said another way, ____ the clock rate. Ó 2004 Morgan Kaufmann Publishers 25
How many cycles are required for a program? . . . 6 th 5 th 4 th 3 rd instruction 2 nd instruction Could assume that number of cycles equals number of instructions 1 st instruction • time This assumption is incorrect, different instructions take different amounts of time on different machines. Why? hint: remember that these are machine instructions, not lines of C code Ó 2004 Morgan Kaufmann Publishers 26
Different numbers of cycles for different instructions time • Multiplication takes more time than addition • Floating point operations take longer than integer ones • Accessing memory takes more time than accessing registers • Important point: changing the cycle time often changes the number of cycles required for various instructions (more later) Ó 2004 Morgan Kaufmann Publishers 27
Example • Our favorite program runs in 10 seconds on computer A, which has a 4 GHz. clock. We are trying to help a computer designer build a new machine B, that will run this program in 6 seconds. The designer can use new (or perhaps more expensive) technology to substantially increase the clock rate, but has informed us that this increase will affect the rest of the CPU design, causing machine B to require 1. 2 times as many clock cycles as machine A for the same program. What clock rate should we tell the designer to target? " • Don't Panic, can easily work this out from basic principles Ó 2004 Morgan Kaufmann Publishers 28
Now that we understand cycles • A given program will require – some number of instructions (machine instructions) – some number of cycles – some number of seconds • We have a vocabulary that relates these quantities: – cycle time (seconds per cycle) – clock rate (cycles per second) – CPI (cycles per instruction) a floating point intensive application might have a higher CPI – MIPS (millions of instructions per second) this would be higher for a program using simple instructions Ó 2004 Morgan Kaufmann Publishers 29
Performance • • Performance is determined by execution time Do any of the other variables equal performance? – # of cycles to execute program? – # of instructions in program? – # of cycles per second? – average # of cycles per instruction? – average # of instructions per second? • Common pitfall: thinking one of the variables is indicative of performance when it really isn’t. Ó 2004 Morgan Kaufmann Publishers 30
CPI Example • Suppose we have two implementations of the same instruction set architecture (ISA). For some program, Machine A has a clock cycle time of 250 ps and a CPI of 2. 0 Machine B has a clock cycle time of 500 ps and a CPI of 1. 2 What machine is faster for this program, and by how much? • If two machines have the same ISA which of our quantities (e. g. , clock rate, CPI, execution time, # of instructions, MIPS) will always be identical? Ó 2004 Morgan Kaufmann Publishers 31
# of Instructions Example • A compiler designer is trying to decide between two code sequences for a particular machine. Based on the hardware implementation, there are three different classes of instructions: Class A, Class B, and Class C, and they require one, two, and three cycles (respectively). The first code sequence has 5 instructions: 2 of A, 1 of B, and 2 of C The second sequence has 6 instructions: 4 of A, 1 of B, and 1 of C. Which sequence will be faster? How much? What is the CPI for each sequence? Ó 2004 Morgan Kaufmann Publishers 32
MIPS example • Two different compilers are being tested for a 4 GHz. machine with three different classes of instructions: Class A, Class B, and Class C, which require one, two, and three cycles (respectively). Both compilers are used to produce code for a large piece of software. The first compiler's code uses 5 million Class A instructions, 1 million Class B instructions, and 1 million Class C instructions. The second compiler's code uses 10 million Class A instructions, 1 million Class B instructions, and 1 million Class C instructions. • • Which sequence will be faster according to MIPS? Which sequence will be faster according to execution time? Ó 2004 Morgan Kaufmann Publishers 33
Benchmarks • • • Performance best determined by running a real application – Use programs typical of expected workload – Or, typical of expected class of applications e. g. , compilers/editors, scientific applications, graphics, etc. Small benchmarks – nice for architects and designers – easy to standardize – can be abused SPEC (System Performance Evaluation Cooperative) – companies have agreed on a set of real program and inputs – valuable indicator of performance (and compiler technology) – can still be abused Ó 2004 Morgan Kaufmann Publishers 34
Benchmark Games • An embarrassed Intel Corp. acknowledged Friday that a bug in a software program known as a compiler had led the company to overstate the speed of its microprocessor chips on an industry benchmark by 10 percent. However, industry analysts said the coding error…was a sad commentary on a common industry practice of “cheating” on standardized performance tests…The error was pointed out to Intel two days ago by a competitor, Motorola …came in a test known as SPECint 92…Intel acknowledged that it had “optimized” its compiler to improve its test scores. The company had also said that it did not like the practice but felt to compelled to make the optimizations because its competitors were doing the same thing…At the heart of Intel’s problem is the practice of “tuning” compiler programs to recognize certain computing problems in the test and then substituting special handwritten pieces of code… Saturday, January 6, 1996 New York Times Ó 2004 Morgan Kaufmann Publishers 35
SPEC ‘ 89 • Compiler “enhancements” and performance Ó 2004 Morgan Kaufmann Publishers 36
SPEC CPU 2000 Ó 2004 Morgan Kaufmann Publishers 37
SPEC 2000 Does doubling the clock rate double the performance? Can a machine with a slower clock rate have better performance? Ó 2004 Morgan Kaufmann Publishers 38
Experiment • Phone a major computer retailer and tell them you are having trouble deciding between two different computers, specifically you are confused about the processors strengths and weaknesses (e. g. , Pentium 4 at 2 Ghz vs. Celeron M at 1. 4 Ghz ) • What kind of response are you likely to get? • What kind of response could you give a friend with the same question? Ó 2004 Morgan Kaufmann Publishers 39
Amdahl's Law Execution Time After Improvement = Execution Time Unaffected +( Execution Time Affected / Amount of Improvement ) • Example: "Suppose a program runs in 100 seconds on a machine, with multiply responsible for 80 seconds of this time. How much do we have to improve the speed of multiplication if we want the program to run 4 times faster? " How about making it 5 times faster? • Principle: Make the common case fast Ó 2004 Morgan Kaufmann Publishers 40
Example • Suppose we enhance a machine making all floating-point instructions run five times faster. If the execution time of some benchmark before the floating-point enhancement is 10 seconds, what will the speedup be if half of the 10 seconds is spent executing floating-point instructions? • We are looking for a benchmark to show off the new floating-point unit described above, and want the overall benchmark to show a speedup of 3. One benchmark we are considering runs for 100 seconds with the old floating-point hardware. How much of the execution time would floatingpoint instructions have to account for in this program in order to yield our desired speedup on this benchmark? Ó 2004 Morgan Kaufmann Publishers 41
Remember • Performance is specific to a particular program/s – Total execution time is a consistent summary of performance • For a given architecture performance increases come from: – – • increases in clock rate (without adverse CPI affects) improvements in processor organization that lower CPI compiler enhancements that lower CPI and/or instruction count Algorithm/Language choices that affect instruction count Pitfall: expecting improvement in one aspect of a machine’s performance to affect the total performance Ó 2004 Morgan Kaufmann Publishers 42
Lets Build a Processor • • Almost ready to move into chapter 5 and start building a processor First, let’s review Boolean Logic and build the ALU we’ll need (Material from Appendix B) operation a 32 ALU result 32 b 32 Ó 2004 Morgan Kaufmann Publishers 43
Review: Boolean Algebra & Gates • Problem: Consider a logic function with three inputs: A, B, and C. Output D is true if at least one input is true Output E is true if exactly two inputs are true Output F is true only if all three inputs are true • Show the truth table for these three functions. • Show the Boolean equations for these three functions. • Show an implementation consisting of inverters, AND, and OR gates. Ó 2004 Morgan Kaufmann Publishers 44
An ALU (arithmetic logic unit) • Let's build an ALU to support the andi and ori instructions – we'll just build a 1 bit ALU, and use 32 of them operation a op a b result b • Possible Implementation (sum-of-products): Ó 2004 Morgan Kaufmann Publishers 45
Review: The Multiplexor • Selects one of the inputs to be the output, based on a control input S • A 0 B 1 C note: we call this a 2 -input mux even though it has 3 inputs! Lets build our ALU using a MUX: Ó 2004 Morgan Kaufmann Publishers 46
Different Implementations • Not easy to decide the “best” way to build something – Don't want too many inputs to a single gate – Don’t want to have to go through too many gates – for our purposes, ease of comprehension is important • Let's look at a 1 -bit ALU for addition: cout = a b + a cin + b cin sum = a xor b xor cin • How could we build a 1 -bit ALU for add, and or? • How could we build a 32 -bit ALU? Ó 2004 Morgan Kaufmann Publishers 47
Building a 32 bit ALU Ó 2004 Morgan Kaufmann Publishers 48
What about subtraction (a – b) ? • • Two's complement approach: just negate b and add. How do we negate? • A very clever solution: Ó 2004 Morgan Kaufmann Publishers 49
Adding a NOR function • Can also choose to invert a. How do we get “a NOR b” ? Ó 2004 Morgan Kaufmann Publishers 50
Tailoring the ALU to the MIPS • Need to support the set-on-less-than instruction (slt) – remember: slt is an arithmetic instruction – produces a 1 if rs < rt and 0 otherwise – use subtraction: (a-b) < 0 implies a < b • Need to support test for equality (beq $t 5, $t 6, $t 7) – use subtraction: (a-b) = 0 implies a = b Ó 2004 Morgan Kaufmann Publishers 51
Supporting slt • Can we figure out the idea? Use this ALU for most significant bit all other bits
Supporting slt Ó 2004 Morgan Kaufmann Publishers 53
Test for equality • Notice control lines: 0000 = and 0001 = or 0010 = add 0110 = subtract 0111 = slt 1100 = NOR • Note: zero is a 1 when the result is zero! Ó 2004 Morgan Kaufmann Publishers 54
Conclusion • We can build an ALU to support the MIPS instruction set – key idea: use multiplexor to select the output we want – we can efficiently perform subtraction using two’s complement – we can replicate a 1 -bit ALU to produce a 32 -bit ALU • Important points about hardware – all of the gates are always working – the speed of a gate is affected by the number of inputs to the gate – the speed of a circuit is affected by the number of gates in series (on the “critical path” or the “deepest level of logic”) • Our primary focus: comprehension, however, – Clever changes to organization can improve performance (similar to using better algorithms in software) – We saw this in multiplication, let’s look at addition now Ó 2004 Morgan Kaufmann Publishers 55
Problem: ripple carry adder is slow • • Is a 32 -bit ALU as fast as a 1 -bit ALU? Is there more than one way to do addition? – two extremes: ripple carry and sum-of-products Can you see the ripple? How could you get rid of it? c 1 = b 0 c 0 + a 0 b 0 c 2 = b 1 c 1 + a 1 b 1 c 2 = c 3 = b 2 c 2 + a 2 b 2 c 4 = b 3 c 3 + a 3 b 3 c 3 = c 4 = Not feasible! Why? Ó 2004 Morgan Kaufmann Publishers 56
Carry-lookahead adder • • An approach in-between our two extremes Motivation: – If we didn't know the value of carry-in, what could we do? – When would we always generate a carry? gi = ai bi – When would we propagate the carry? pi = ai + bi • Did we get rid of the ripple? c 1 = g 0 + p 0 c 0 c 2 = g 1 + p 1 c 1 c 2 = c 3 = g 2 + p 2 c 2 c 3 = c 4 = g 3 + p 3 c 3 c 4 = Feasible! Why? Ó 2004 Morgan Kaufmann Publishers 57
Use principle to build bigger adders • • • Can’t build a 16 bit adder this way. . . (too big) Could use ripple carry of 4 -bit CLA adders Better: use the CLA principle again! Ó 2004 Morgan Kaufmann Publishers 58
ALU Summary • • We can build an ALU to support MIPS addition Our focus is on comprehension, not performance Real processors use more sophisticated techniques for arithmetic Where performance is not critical, hardware description languages allow designers to completely automate the creation of hardware! Ó 2004 Morgan Kaufmann Publishers 59
Chapter Five Ó 2004 Morgan Kaufmann Publishers 60
The Processor: Datapath & Control • • We're ready to look at an implementation of the MIPS Simplified to contain only: – memory-reference instructions: lw, sw – arithmetic-logical instructions: add, sub, and, or, slt – control flow instructions: beq, j • Generic Implementation: – – • use the program counter (PC) to supply instruction address get the instruction from memory read registers use the instruction to decide exactly what to do All instructions use the ALU after reading the registers Why? memory-reference? arithmetic? control flow? Ó 2004 Morgan Kaufmann Publishers 61
More Implementation Details • Abstract / Simplified View: Two types of functional units: – elements that operate on data values (combinational) – elements that contain state (sequential) Ó 2004 Morgan Kaufmann Publishers 62
State Elements • • Unclocked vs. Clocked Clocks used in synchronous logic – when should an element that contains state be updated? cycle time Ó 2004 Morgan Kaufmann Publishers 63
An unclocked state element • The set-reset latch – output depends on present inputs and also on past inputs Ó 2004 Morgan Kaufmann Publishers 64
Latches and Flip-flops • • Output is equal to the stored value inside the element (don't need to ask for permission to look at the value) Change of state (value) is based on the clock Latches: whenever the inputs change, and the clock is asserted Flip-flop: state changes only on a clock edge (edge-triggered methodology) "logically true", — could mean electrically low A clocking methodology defines when signals can be read and written — wouldn't want to read a signal at the same time it was being written Ó 2004 Morgan Kaufmann Publishers 65
D-latch • • Two inputs: – the data value to be stored (D) – the clock signal (C) indicating when to read & store D Two outputs: – the value of the internal state (Q) and it's complement Ó 2004 Morgan Kaufmann Publishers 66
D flip-flop • Output changes only on the clock edge Ó 2004 Morgan Kaufmann Publishers 67
Our Implementation • • An edge triggered methodology Typical execution: – read contents of some state elements, – send values through some combinational logic – write results to one or more state elements Ó 2004 Morgan Kaufmann Publishers 68
Register File • Built using D flip-flops Do you understand? What is the “Mux” above? Ó 2004 Morgan Kaufmann Publishers 69
Abstraction • • Make sure you understand the abstractions! Sometimes it is easy to think you do, when you don’t Ó 2004 Morgan Kaufmann Publishers 70
Register File • Note: we still use the real clock to determine when to write Ó 2004 Morgan Kaufmann Publishers 71
Simple Implementation • Include the functional units we need for each instruction Why do we need this stuff? Ó 2004 Morgan Kaufmann Publishers 72
Building the Datapath • Use multiplexors to stitch them together Ó 2004 Morgan Kaufmann Publishers 73
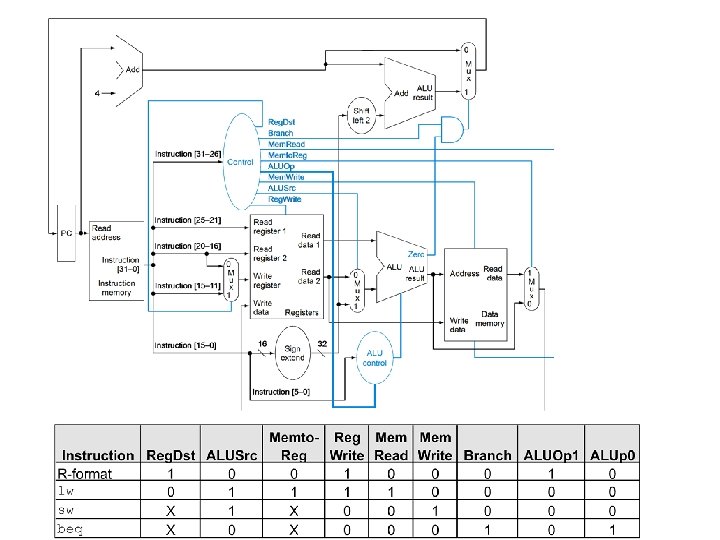
Control • Selecting the operations to perform (ALU, read/write, etc. ) • Controlling the flow of data (multiplexor inputs) • Information comes from the 32 bits of the instruction • Example: add $8, $17, $18 Instruction Format: 000000 10001 10010 01000 00000 100000 op • rs rt rd shamt funct ALU's operation based on instruction type and function code Ó 2004 Morgan Kaufmann Publishers 74
Control • • • e. g. , what should the ALU do with this instruction Example: lw $1, 100($2) 35 2 1 op rs rt 16 bit offset ALU control input 0000 0001 0010 0111 1100 • 100 AND OR add subtract set-on-less-than NOR Why is the code for subtract 0110 and not 0011? Ó 2004 Morgan Kaufmann Publishers 75
Control • Must describe hardware to compute 4 -bit ALU control input – given instruction type 00 = lw, sw ALUOp 01 = beq, computed from instruction type 10 = arithmetic – function code for arithmetic • Describe it using a truth table (can turn into gates): Ó 2004 Morgan Kaufmann Publishers 76
Control • Simple combinational logic (truth tables) Ó 2004 Morgan Kaufmann Publishers 78
Our Simple Control Structure • All of the logic is combinational • We wait for everything to settle down, and the right thing to be done – ALU might not produce “right answer” right away – we use write signals along with clock to determine when to write • Cycle time determined by length of the longest path We are ignoring some details like setup and hold times Ó 2004 Morgan Kaufmann Publishers 79
Single Cycle Implementation • Calculate cycle time assuming negligible delays except: – memory (200 ps), ALU and adders (100 ps), register file access (50 ps) Ó 2004 Morgan Kaufmann Publishers 80
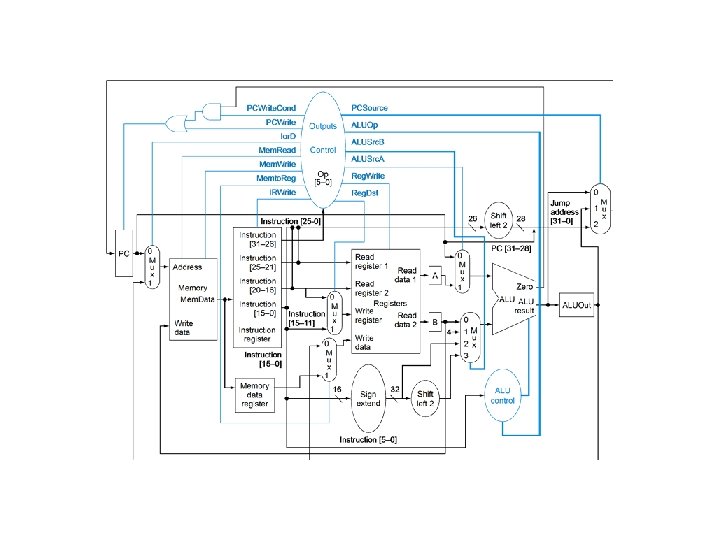
Where we are headed • • Single Cycle Problems: – what if we had a more complicated instruction like floating point? – wasteful of area One Solution: – use a “smaller” cycle time – have different instructions take different numbers of cycles – a “multicycle” datapath: Ó 2004 Morgan Kaufmann Publishers 81
Multicycle Approach • • • We will be reusing functional units – ALU used to compute address and to increment PC – Memory used for instruction and data Our control signals will not be determined directly by instruction – e. g. , what should the ALU do for a “subtract” instruction? We’ll use a finite state machine for control Ó 2004 Morgan Kaufmann Publishers 82
Multicycle Approach • • Break up the instructions into steps, each step takes a cycle – balance the amount of work to be done – restrict each cycle to use only one major functional unit At the end of a cycle – store values for use in later cycles (easiest thing to do) – introduce additional “internal” registers Ó 2004 Morgan Kaufmann Publishers 83
Instructions from ISA perspective • • Consider each instruction from perspective of ISA. Example: – The add instruction changes a register. – Register specified by bits 15: 11 of instruction. – Instruction specified by the PC. – New value is the sum (“op”) of two registers. – Registers specified by bits 25: 21 and 20: 16 of the instruction Reg[Memory[PC][15: 11]] <= Reg[Memory[PC][25: 21]] op Reg[Memory[PC][20: 16]] – In order to accomplish this we must break up the instruction. (kind of like introducing variables when programming) Ó 2004 Morgan Kaufmann Publishers 84
Breaking down an instruction • ISA definition of arithmetic: Reg[Memory[PC][15: 11]] <= Reg[Memory[PC][25: 21]] op Reg[Memory[PC][20: 16]] • Could break down to: – IR <= Memory[PC] – A <= Reg[IR[25: 21]] – B <= Reg[IR[20: 16]] – ALUOut <= A op B – Reg[IR[20: 16]] <= ALUOut • We forgot an important part of the definition of arithmetic! – PC <= PC + 4 Ó 2004 Morgan Kaufmann Publishers 85
Idea behind multicycle approach • We define each instruction from the ISA perspective (do this!) • Break it down into steps following our rule that data flows through at most one major functional unit (e. g. , balance work across steps) • Introduce new registers as needed (e. g, A, B, ALUOut, MDR, etc. ) • Finally try and pack as much work into each step (avoid unnecessary cycles) while also trying to share steps where possible (minimizes control, helps to simplify solution) • Result: Our book’s multicycle Implementation! Ó 2004 Morgan Kaufmann Publishers 86
Five Execution Steps • Instruction Fetch • Instruction Decode and Register Fetch • Execution, Memory Address Computation, or Branch Completion • Memory Access or R-type instruction completion • Write-back step INSTRUCTIONS TAKE FROM 3 - 5 CYCLES! Ó 2004 Morgan Kaufmann Publishers 87
Step 1: Instruction Fetch • • • Use PC to get instruction and put it in the Instruction Register. Increment the PC by 4 and put the result back in the PC. Can be described succinctly using RTL "Register-Transfer Language" IR <= Memory[PC]; PC <= PC + 4; Can we figure out the values of the control signals? What is the advantage of updating the PC now? Ó 2004 Morgan Kaufmann Publishers 88
Step 2: Instruction Decode and Register Fetch • • • Read registers rs and rt in case we need them Compute the branch address in case the instruction is a branch RTL: A <= Reg[IR[25: 21]]; B <= Reg[IR[20: 16]]; ALUOut <= PC + (sign-extend(IR[15: 0]) << 2); • We aren't setting any control lines based on the instruction type (we are busy "decoding" it in our control logic) Ó 2004 Morgan Kaufmann Publishers 89
Step 3 (instruction dependent) • ALU is performing one of three functions, based on instruction type • Memory Reference: ALUOut <= A + sign-extend(IR[15: 0]); • R-type: ALUOut <= A op B; • Branch: if (A==B) PC <= ALUOut; Ó 2004 Morgan Kaufmann Publishers 90
Step 4 (R-type or memory-access) • Loads and stores access memory MDR <= Memory[ALUOut]; or Memory[ALUOut] <= B; • R-type instructions finish Reg[IR[15: 11]] <= ALUOut; The write actually takes place at the end of the cycle on the edge Ó 2004 Morgan Kaufmann Publishers 91
Write-back step • Reg[IR[20: 16]] <= MDR; Which instruction needs this? Ó 2004 Morgan Kaufmann Publishers 92
Summary: Ó 2004 Morgan Kaufmann Publishers 93
Simple Questions • How many cycles will it take to execute this code? Label: • • lw $t 2, 0($t 3) lw $t 3, 4($t 3) beq $t 2, $t 3, Label add $t 5, $t 2, $t 3 sw $t 5, 8($t 3). . . #assume not What is going on during the 8 th cycle of execution? In what cycle does the actual addition of $t 2 and $t 3 takes place? Ó 2004 Morgan Kaufmann Publishers 94
Review: finite state machines • Finite state machines: – a set of states and – next state function (determined by current state and the input) – output function (determined by current state and possibly input) – We’ll use a Moore machine (output based only on current state) Ó 2004 Morgan Kaufmann Publishers 96
Review: finite state machines • Example: B. 37 A friend would like you to build an “electronic eye” for use as a fake security device. The device consists of three lights lined up in a row, controlled by the outputs Left, Middle, and Right, which, if asserted, indicate that a light should be on. Only one light is on at a time, and the light “moves” from left to right and then from right to left, thus scaring away thieves who believe that the device is monitoring their activity. Draw the graphical representation for the finite state machine used to specify the electronic eye. Note that the rate of the eye’s movement will be controlled by the clock speed (which should not be too great) and that there are essentially no inputs. Ó 2004 Morgan Kaufmann Publishers 97
Implementing the Control • Value of control signals is dependent upon: – what instruction is being executed – which step is being performed • Use the information we’ve accumulated to specify a finite state machine – specify the finite state machine graphically, or – use microprogramming • Implementation can be derived from specification Ó 2004 Morgan Kaufmann Publishers 98
Graphical Specification of FSM • Note: – don’t care if not mentioned – asserted if name only – otherwise exact value • How many state bits will we need? Ó 2004 Morgan Kaufmann Publishers 99
Finite State Machine for Control • Implementation: Ó 2004 Morgan Kaufmann Publishers 100
PLA Implementation • If I picked a horizontal or vertical line could you explain it? Ó 2004 Morgan Kaufmann Publishers 101
ROM Implementation • • ROM = "Read Only Memory" – values of memory locations are fixed ahead of time A ROM can be used to implement a truth table – if the address is m-bits, we can address 2 m entries in the ROM. – our outputs are the bits of data that the address points to. m n 0 0 1 1 0 1 0 1 0 1 1 1 0 0 0 1 1 1 0 0 0 0 1 m is the "height", and n is the "width" Ó 2004 Morgan Kaufmann Publishers 102
ROM Implementation • • How many inputs are there? 6 bits for opcode, 4 bits for state = 10 address lines (i. e. , 210 = 1024 different addresses) How many outputs are there? 16 datapath-control outputs, 4 state bits = 20 outputs • ROM is 210 x 20 = 20 K bits • Rather wasteful, since for lots of the entries, the outputs are the same — i. e. , opcode is often ignored (and a rather unusual size) Ó 2004 Morgan Kaufmann Publishers 103
ROM vs PLA • Break up the table into two parts — 4 state bits tell you the 16 outputs, 24 x 16 bits of ROM — 10 bits tell you the 4 next state bits, 210 x 4 bits of ROM — Total: 4. 3 K bits of ROM • PLA is much smaller — can share product terms — only need entries that produce an active output — can take into account don't cares • Size is (#inputs ´ #product-terms) + (#outputs ´ #product-terms) For this example = (10 x 17)+(20 x 17) = 510 PLA cells • PLA cells usually about the size of a ROM cell (slightly bigger) Ó 2004 Morgan Kaufmann Publishers 104
Another Implementation Style • Complex instructions: the "next state" is often current state + 1 Ó 2004 Morgan Kaufmann Publishers 105
Details Ó 2004 Morgan Kaufmann Publishers 106
Microprogramming • What are the “microinstructions” ? Ó 2004 Morgan Kaufmann Publishers 107
Microprogramming • A specification methodology – appropriate if hundreds of opcodes, modes, cycles, etc. – signals specified symbolically using microinstructions • • Will two implementations of the same architecture have the same microcode? What would a microassembler do? Ó 2004 Morgan Kaufmann Publishers 108
Microinstruction format Ó 2004 Morgan Kaufmann Publishers 109
Maximally vs. Minimally Encoded • No encoding: – 1 bit for each datapath operation – faster, requires more memory (logic) – used for Vax 780 — an astonishing 400 K of memory! • Lots of encoding: – send the microinstructions through logic to get control signals – uses less memory, slower • Historical context of CISC: – Too much logic to put on a single chip with everything else – Use a ROM (or even RAM) to hold the microcode – It’s easy to add new instructions Ó 2004 Morgan Kaufmann Publishers 110
Microcode: Trade-offs • Distinction between specification and implementation is sometimes blurred • Specification Advantages: – Easy to design and write – Design architecture and microcode in parallel • Implementation (off-chip ROM) Advantages – Easy to change since values are in memory – Can emulate other architectures – Can make use of internal registers • Implementation Disadvantages, SLOWER now that: – Control is implemented on same chip as processor – ROM is no longer faster than RAM – No need to go back and make changes Ó 2004 Morgan Kaufmann Publishers 111
Historical Perspective • • • In the ‘ 60 s and ‘ 70 s microprogramming was very important for implementing machines This led to more sophisticated ISAs and the VAX In the ‘ 80 s RISC processors based on pipelining became popular Pipelining the microinstructions is also possible! Implementations of IA-32 architecture processors since 486 use: – “hardwired control” for simpler instructions (few cycles, FSM control implemented using PLA or random logic) – “microcoded control” for more complex instructions (large numbers of cycles, central control store) • The IA-64 architecture uses a RISC-style ISA and can be implemented without a large central control store Ó 2004 Morgan Kaufmann Publishers 112
Pentium 4 • Pipelining is important (last IA-32 without it was 80386 in 1985) Chapter 7 Chapter 6 • Pipelining is used for the simple instructions favored by compilers “Simply put, a high performance implementation needs to ensure that the simple instructions execute quickly, and that the burden of the complexities of the instruction set penalize the complex, less frequently used, instructions” Ó 2004 Morgan Kaufmann Publishers 113
Pentium 4 • Somewhere in all that “control we must handle complex instructions • • • Processor executes simple microinstructions, 70 bits wide (hardwired) 120 control lines for integer datapath (400 for floating point) If an instruction requires more than 4 microinstructions to implement, control from microcode ROM (8000 microinstructions) Its complicated! • Ó 2004 Morgan Kaufmann Publishers 114
Chapter 5 Summary • If we understand the instructions… We can build a simple processor! • If instructions take different amounts of time, multi-cycle is better • Datapath implemented using: – Combinational logic for arithmetic – State holding elements to remember bits • Control implemented using: – Combinational logic for single-cycle implementation – Finite state machine for multi-cycle implementation Ó 2004 Morgan Kaufmann Publishers 115