Lecture Note on Switch Architectures Function of Switch



 • Output port processor")







) Not suitable for hardware")


 – O(log")
 – Egress: O(N) • Inefficient")

")
 Assume 10 G for each port and packet size is 64 bytes.")






")







 40 B packets (Mpps) 1998 -99 OC 12")


























- Slides: 63
Lecture Note on Switch Architectures
Function of Switch
Naive Way
Bus-Based Switch • No buffering at input port processor (IPP) • Output port processor (OPP) buffers cells • Controller exchanges control message with terminals and other controller. • Disadvantage: – Bus bandwidth is equal to sum of external link for non-blocking – IPPs and OPPs must operate at full bus bandwidth – Bus width increases with number of links
Centralized Bus Arbitration • IPPs send requests to central arbiter • Request may includes: – – Priority Waiting time OPP destination(s) Length of IPP queue • Arbitration complexity is O(N^2) • Distributed version is preferred, but may degrade throughput.
Bus Arbitration Using Rotating Daisy Chain • Rotating token eliminates positional favoritism
Ring Switch • Same bandwidth and complexity as bus switch • Avoids capacitive loading of bus, allowing higher clock frequencies • Control mechanisms – Token passing – Slotted ring with busy bit
Shared Buffer Switch • Individual queues are rarely full. • Shared memory needs two times of external link bandwidth • Require less memory • Better ability to handle burst traffic
Crossbar Switch
Output Buffering • Efficient, but needs N time speed up internally.
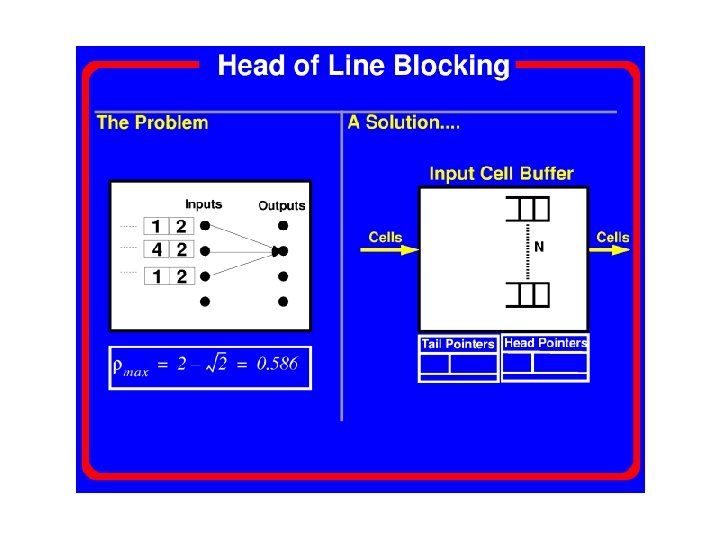
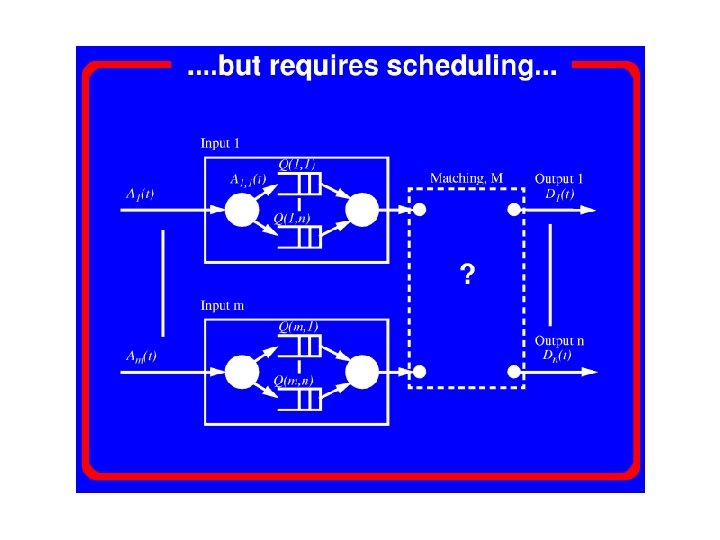
Input Buffering • • Multiple packets simultaneously transmitted distinct outputs. Require sophisticated arbitration No speed up required Head-of-line blocking
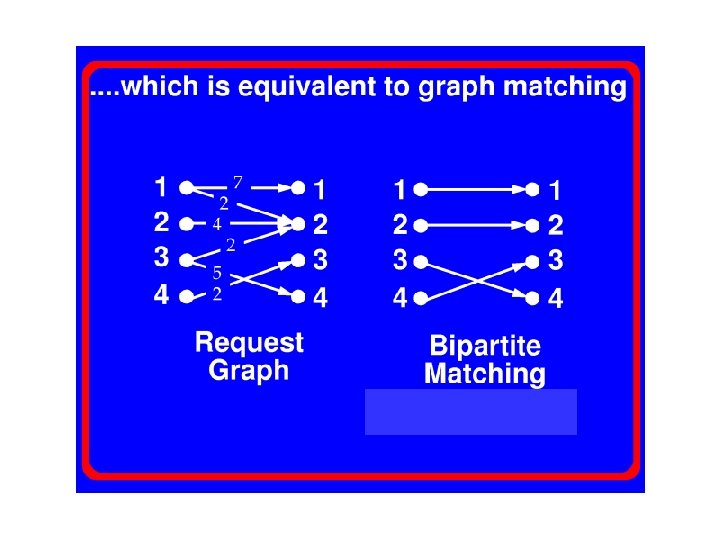
Bi-partite Matching • • Require global information Complexity is O(N^(5/2)) Not suitable for hardware implementation May leads to starvation
Desired Arbitration Algorithms • High throughput – Low backlog in each input queue – Close to 100% for each input and output • Starvation free – No queue will be hold indefinitely • Simple to implement
Options to Build High Performance Switches • Bufferless crossbar • Buffered crossbar • Shared buffer
Bufferless Crossbar • Centralized arbitrator is required – Arbitration complexity is O(N*N) – O(log 2 N) iterations of arbitration needed for high throughput • Synchronization in all elements • Single point failure: central arbitrator • Complex line interface
Buffered Crossbar • Simple scheduling algorithms – Ingress: O(1) – Egress: O(N) • Inefficient use of memory – Memory linearly increased with number of ports
Shared Memory • • • No central arbitrator needed Reduced memory requirements Distributed flow control Less timing constrains Simpler line card interface
Comparisons (1)
Comparison (2) Assume 10 G for each port and packet size is 64 bytes.
Scaling Number of Ports • Single larger switch is less expensive, more reliable, easier to maintain and offer better performance, but – O(n 2) complexity – Board-level buses limited by capacitive loading • Port multiplexing • Buffered multistage routing – Dynamic routing: Benes network – Static routing: Clos network • Bufferless multistage routing – Deflection routing
Port Multiplexing • • • High speed core can handles high speed links as well as low speed Sharing of common circuitry Reduced complexity in interconnection network Better queueing performance for bursty traffic Less fragmentation of bandwidth and memory
Dynamic Routing – Benes Network • Network expanded by adding stages on left and right – 2 k-1 stages with d port switch elements supports dk ports • • Traffic distribution on first k-1 stages Routing on last k stages Internal load external load Traffic maybe out of order: need re-sequencing
Static Routing - Clos network • All traffic follows same path • r 2 d-1 to be strict non-blocking.
Deflection Routing
Basic Architectural Components: Forwarding Decision 1. Forwarding Table Forwarding Decision 2. Interconnect 3. Output Scheduling
ATM Switches Direct Lookup Memory Data Address VCI (Port, VCI)
Ethernet Switches Hashing Memory #1 #2 #3 #4 Search Data 48 Hashing Function 16 #1 #2 CRC-16 Linked lists #1 #2 #3 Advantages • Simple • Expected lookup time can be small Disadvantages • Non-deterministic lookup time • Inefficient use of memory Associated Data { Hit? Address log 2 N
Per-Packet Processing in IP Routers 1. Accept packet arriving on an incoming link. 2. Lookup packet destination address in the forwarding table, to identify outgoing port(s). 3. Manipulate packet header: e. g. , update header checksum. 4. Send packet to the outgoing port(s). 5. Classify and buffer packet in the queue. 6. Transmit packet onto outgoing link.
IP Router Lookup H E A D E R Destination Address Incoming Packet Forwarding Engine Next Hop Computation Forwarding Table Destination Next Hop -------- Next Hop Link
Lookup and Forwarding Engine Packet payload header Router Destination Address Lookup Data Forwarding Engine Outgoing Port
Example Forwarding Table Destination IP Prefix 65. 0. 0. 0/ 8 128. 9. 0. 0/16 Prefix length 142. 12. 0. 0/19 IP prefix: 1 -32 bits Outgoing Port 3 1 7
Multiple Matching Longest matching prefix 128. 9. 176. 0/24 128. 9. 16. 0/21 128. 9. 172. 0/21 65. 0. 0. 0/8 0 128. 9. 0. 0/16 128. 9. 16. 14 142. 12. 0. 0/19 232 -1 Routing lookup: Find the longest matching prefix (or the most specific route) among all prefixes that match the destination address.
Longest Prefix Matching Problem 2 -dimensional search • Prefix Length • Prefix Value Performance Metrics • Lookup time • Storage space • Update time • Preprocessing time
Required Lookup Rates Year Line-rate (Gbps) 40 B packets (Mpps) 1998 -99 OC 12 c 0. 622 1. 94 1999 -00 OC 48 c 2. 5 7. 81 2000 -01 OC 192 c 10. 0 31. 25 2002 -05 OC 768 c 40. 0 125 31. 25 Mpps 33 ns DRAM: 50 -80 ns, SRAM: 5 -10 ns
Number of Prefixes Size of Forward Table 10, 000/year 95 96 97 Year 98 99 00 Renewed growth due to multi-homing of enterprise networks
Trees and Tries Binary Search Tree < > > < N entries > log 2 N < Binary Search Trie 0 0 1 1 010 0 1 111
Number Typical Profile of Forward Table Prefix Length Most prefixes are 24 -bits or shorter
Basic Architectural Components: Interconnect 1. Forwarding Table Forwarding Decision 2. Interconnect 3. Output Scheduling
First-Generation Routers Buffer Memory CPU DMA DMA Line Interface MAC MAC
Second-Generation Routers Buffer Memory CPU DMA DMA Line Card Local Buffer Memory MAC MAC
Third-Generation Routers Line Card CPU Card Line Card Local Buffer Memory MAC
Switching Goals
Circuit Switches • A switch that can handle N calls has N logical inputs and N logical outputs – N up to 200, 000 • Moves 8 -bit samples from an input to an output port – Samples have no headers – Destination of sample depends on time at which it arrives at the switch • In practice, input trunks are multiplexed – Multiplexed trunks carry frames, i. e. , set of samples • Extract samples from frame, and depending on position in frame, switch to output – each incoming sample has to get to the right output line and the right slot in the output frame
Blocking in Circuit Switches • Can’t find a path from input to output • Internal blocking – slot in output frame exists, but no path • Output blocking – no slot in output frame is available
Time Division Switching • Time division switching interchanges sample position within a frame: time slot interchange (TSI)
Scaling Issues with TSI
Space Division Switching • Each sample takes a different path through the switch, depending on its destination
Time Space Switching
Time Space Time Switching
Packet Switches • In a circuit switch, path of a sample is determined at time of connection establishment. No need for header. • In a packet switch, packets carry a destination field or label. Need to look up destination port on-the-fly. – Datagram switches: lookup based on destination address – Label switches: lookup based on labels
Blocking in Packet Switches • Can have both internal and output blocking • Internal – no path to output • Output – trunk unavailable • Unlike a circuit switch, cannot predict if packets will block. • If packet is blocked, must buffer or drop
Dealing with Blocking in Packet Switches • Over-provisioning – internal links much faster than inputs • Buffers – at input or output • Backpressure – if switch fabric doesn’t have buffers, prevent packet from entering until path is available • Parallel switch fabrics – increases effective switching capacity
Basic Architectural Components: Queuing, Classification 1. Forwarding Table Forwarding Decision 2. Interconnect 3. Output Scheduling
Techniques in Queuing Input Queueing Output Queueing
Output Queueing Individual Output Queues Centralized Shared Memory b/w = 2 N. R 1 2 N 1 2 Memory b/w = (N+1). R N
Input Queuing
Delay Input Queueing Performance Load 58. 6% 100%
Delay Virtual Output Queues at Input Load 100%
Classification H E A D E R Incoming Packet Forwarding Engine Packet Classification Classifier (Policy Database) Predicate Action -------- Action
Multi-Field Packet Classification Given a classifier with N rules, find the action associated with the highest priority rule matching an incoming packet.