Lecture 4 Text embeddings and recurrent neural networks

Lecture 4: Text, embeddings, and recurrent neural networks Practical deep learning
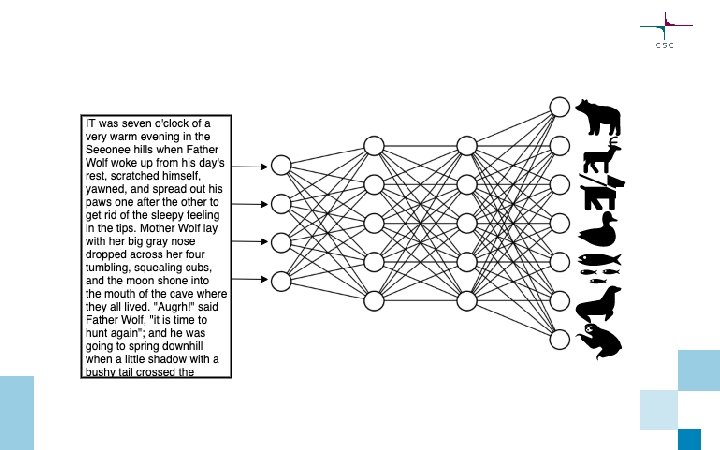

Representations for text
![Sequence data By Mogrifier 5 [CC BY-SA 3. 0], from Wikimedia Commons By Der](http://slidetodoc.com/presentation_image_h2/bb5b6bb707458b8c4b1c571f5be65988/image-4.jpg "Sequence data By Mogrifier 5 [CC BY-SA 3. 0], from Wikimedia Commons By Der")
Sequence data By Mogrifier 5 [CC BY-SA 3. 0], from Wikimedia Commons By Der Lange 11/6/2005, http: //commons. wikimedia. org/w/index. php? title=File: Spikewaves. png&action=edit§ion=2
 • main representations: • one-hot encoding")
Text data • sequence of words (or characters) • main representations: • one-hot encoding • word embedding raw text cleaned text preprocessing one-hot encoding tokens tokenization vectorization word embedding

One-hot encoding and bag-of-words • dimensionality equals the number of distinct tokens in dictionary • 1000’s or 10000’s • tokens are independent of each other • bag-of-words loses the ordering of tokens • lots of important applications: IR etc. • n-grams cleaned text tokens The cat is in the moon. [“the”, “cat”, “is”, “in”, “the”, “moon”] dictionary one-hot encoding {“a”: 1, “aardvark”: 2, “aardwolf”: 3, …} bag of words

Word embeddings • dense vector representations • dimensionality typically much lower than in one-hot ⇒ bag-of-words not needed • learned based on context of words • semantics • similar words have similar vectors • directions in the vector space map to semantic relationships • context-free and contextual embeddings • either learn from data or use a pre-trained embedding
 word embeddings Images from: https: //www. tensorflow. org/tutorials/word 2 vec Image from: http:")
(Context-free) word embeddings Images from: https: //www. tensorflow. org/tutorials/word 2 vec Image from: http: //wiki. fast. ai/index. php/Lesson_5_Notes

Standalone word embedding algorithms • unsupervised learning, no annotation needed • popular context-free algorithms include: • word 2 vec • GLo. Ve • fast. Text • recently proposed contextual algorithms include: • ELMo • BERT • to learn a task-based embedding or to use a pre-trained one? • pre-trained embeddings encode general semantic relationships • need to handle OOV (out-of-vocabulary) words • task-based may sometimes be better if enough data

Word sequence embedding • usually a fixed-size matrix or sequence • in tf. keras: layers. Embedding(input_dim, output_dim, input_length, trainable, weights) cleaned text The cat is in the moon. tokens padding / truncate [“the”, “cat”, “is”, “in”, “the”, “moon”] “the”, “moon”, ∅, ∅] learned embedding sequence embedding 10 × N matrix or sequence of length 10

Deep learning for sequences
 •")
Deep learning for sequences • first layer is usually an embedding (if needed) • then there are three main approaches (that can also be combined): • recurrent layers • convolutional layers • dense layers + attention (covered tomorrow) • last layers are often dense
 CNNs for sequences • a fixed-length embedded sequence is a matrix")
Convolutional layer (1) CNNs for sequences • a fixed-length embedded sequence is a matrix • can be considered as an image ⇒ CNNs • 1 D convolution • as we want to process the full embedding each time • simple and cheap approach for simple tasks • in tf. keras: layers. Conv 1 D(filters, kernel_size, padding, activation) layers. Max. Pooling 1 D(pool_size) layers. Global. Max. Pooling 1 D()

1 D convolution tokens embedding
 Recurrent neural networks • MLPs and CNNs expect fixed-sized input, not sequences •")
(2) Recurrent neural networks • MLPs and CNNs expect fixed-sized input, not sequences • RNNs have memory and recurrent connections, i. e. loops • last output contains a representation of the whole sequence • learning by backpropagation through time • vanishing or exploding gradients! By François Deloche [CC BY-SA 4. 0], from Wikimedia Commons

Recurrent neural networks Image from: http: //karpathy. github. io/2015/05/21/rnn-effectiveness/
 network • RNNs can be harder to train than feedforward")
Long-short term memory (LSTM) network • RNNs can be harder to train than feedforward networks • LSTM: specialized model to solve the vanishing gradient problem • • additional “conveyor belt” dataflow to carry information across timesteps “forget”, “input”, and “output” gates By François Deloche [CC BY-SA 4. 0], from Wikimedia Commons

LSTM layer • simple RNNs do not usually work in practice ⇒ use LSTM or its variants (e. g. GRU) • can also be used bidirectionally • in tf. keras: layers. LSTM(units, return_sequences) layers. GRU(units, return_sequences) layers. Bidirectional(layer, merge_mode)

Image from: https: //support. apple. com/en-us/HT 207525 Language models and text generation • RNNs can be trained to predict the next word and then used to generate novel text (or music, etc. ) Image from: https: //github. com/oxford-cs-deepnlp-2017/lectures/blob/master/Lecture%204%20 -%20 Language%20 Modelling%20 and%20 RNNs%20 Part%202. pdf
 networks Image from: https: //devblogs. nvidia. com/introduction-neural-machine-translation-gpus-part-2/")
Encoder–decoder (seq 2 seq) networks Image from: https: //devblogs. nvidia. com/introduction-neural-machine-translation-gpus-part-2/
- Slides: 20