Learning to rank pr 20 Ranking of job

Learning to rank ápr. 20.

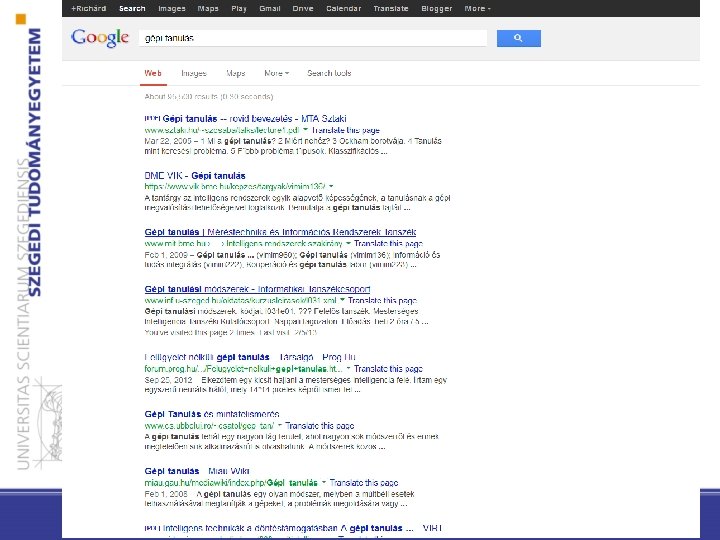

Ranking of job candidates

The ranking task The set of o 1…n candidates and the query q is given The pairs {oi, q} can be described by a (rich) feature set Rank the o 1…n items according to their relevance to the qurery q! The output is an ordering of o 1…n instances (i. e. a structure)

Learning to rank Train database: Model:

Learning 2 rank vs. regression Baseline solution: use rank as a target regression value Warning: The ranking is relative in a a given set! And the concrete values are not important, only the order counts! Normalisation among sets is crucial: pl. f(q 1, o 1, 18) = f(q 2, o 2, 72) = 1

Learning to rank – top K case Train database: Only a few relevant item is know: Model:

Learning 2 rank vs. classification Relevant/non-relevant binary classification? Relevant is a local concept as we are looking for the most relevant ones! (What happens if a binary classifier predicts only non-relevant for each item? ) We’re looking for a relative ordering and not a global function.

Evaluation metric Kendall tau: top. K case: reciproc ranking = 1/rank, where rank is the place of the first relevant prediction MRR: mean of the reciproc rank over a set of q, O pairs

Learning 2 rank approaches • Pointwise approach Forget the original set memberships, global regressziós (full ranking) or classfication (top. K case) • Pairwise approach Take each pair inside an O. Define a binary classification task for predicting whether o 1 or o 2 is preferred (all-vs-all) • Listwise approach Learn the ranking directly. A pair {q, O} is an instance.

Pairwise learning to rank

SVMrank

SVMrank
 is linear: … http: //www. cs. cornell. edu/people/tj/svm_light/svm_rank. html")
SVMrank Assume f(x) is linear: … http: //www. cs. cornell. edu/people/tj/svm_light/svm_rank. html

Listwise learning to rank
 is")
List. MLE – Plackett Luce Modell π is an ordering of O π-1(i) is the item in the ith position s a the score for a particular item • P is a distribution • The decreasing(increasing) ordering according to s has the greatest(lowest) probability Ps
 of the Plackett-Luce modell")
List. MLE Training is a maximum likelihood parameter estimation (MLE) of the Plackett-Luce modell alapján (θ):

List. MLE top. K case Yi is the set of relevant items for the ith query ?

Notes • Pair- and listwise approaches considerably outperform the pointwise approach • The pair- and listwise approaches are competitive • Number of training instances: • • pairwise |Q||O|2 listwise |Q|

Summary • Learning to rank • Full ranking • Only top. K relevant item is known • Pointwise approach • Regression • Relevant/non-relevant classification • Pairwise approach • SVMrank • Listwise approach • List. MLE
- Slides: 22