Learning Techniques for Information Retrieval Perceptron algorithm Least




 For each X D 1, if X·W<0 then increase the weight")






 • Definition Consider the -th row in the")
- Slides: 13
Learning Techniques for Information Retrieval • Perceptron algorithm • Least mean
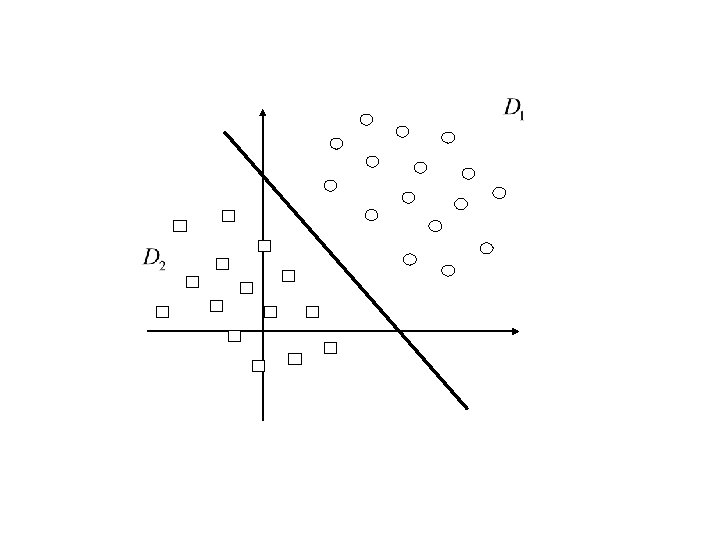
Adaptive linear model • Let X 1, X 2, …, Xn be n vectors (of n documents). • D 1 D 2={X 1, X 2, …, Xn}, where D 1 be the set of relevant documents and D 2 be the set of irrelevant documents. • D 1 and D 2 are obtained from users feedback. • Question: find a vector w such that Wi Xij<0 for each Xj D 1 and i=1 to m Wi Xij>>0 for each Xj D 2
X 0 X 1 X 2 W 1 W 0 Threshold W 2 X 3 +1 W 3 -1 Wn Xn Output =sign(y)
Remarks: • W is the new vector for query. • W is computed based on the feedback, i. e. , D 1 and D 2. • The following is a hyper-plane: Wi Xi>=0 i=1 to m • The hyper-palne cuts the whole space into to parts and hopefully one part contains relevant docs and the other contains ir-relevant docs.
Perceptron Algorithm (1) For each X D 1, if X·W<0 then increase the weight vector at the next iteration: W=Wold+CX. (2) For each X D 2 if X·W>0 then decrease the weight vector at the next iteration: W=Wold -CX. C is a constant. Repeat until X·W>0 for each X D 1 and X·W<0 for each X D 2.
Preceptron Convergence Theorem • The perceptron algorithm finds a W in finite iterations if the t raining set {X 1, X 2, …, Xn} is linearly separable.
Query Expansion and Term Reweighting for the Vector Model • : set of relevant documents, as identified by the user, among the retrieved documents; • : set of non-relevant documents among the retrieved documents; • : set of relevant documents among all documents in the , collection; , • : number of documents in the sets respectively; • : tuning constants.
Query Expansion and Term Reweighting for the Vector Model Standard_Rochio : Ide_Regular : Ide_Dec_Hi : Where non-relevant document. is a reference to the highest ranked
Evaluation of Relevance Feedback Strategies • Simple way: use the new query to search the database and recalculate the results • Problem: used feedback information, it is not fare. • Better way: just consider the unused document.
Query Expansion Through Local Clustering • Definition Let be a non-empty subset of words which are grammatical variants of each other. A canonical form from of is called a stem. For instance, if then • Definition For a given query , the set of documents retrieved is called the local document set. Further, the set of all distinct words in the local document set is called the local vocabulary. The set of all distinct stems derived from the set is referred to as.
Association Clusters • Definition The frequency of a stem , is referred to as matrix with Let rows and be the transpose of in a document be an association columns, where . . The matrix is a local stem-stem association matrix. Each element expresses a correlation , between the stems in and namely, (5. 5) (5. 6)
Association Clusters • Normalize (5. 7) • Definition Consider the -th row in the association matrix (i. e. , the row with all the associations for the stem ). Let be a function which takes the -th row and returns the set of largest values , where varies over the set of local stems and. Then defines a local association cluster around the stem. If is given by equation (5. 6), the association cluster is said to be unnormalized. If is given by equation 5. 7, the association cluster is said to be normalized.