Latent Dirichlet Allocation a generative model for text




 n Latent Semantic Indexing ¨ Classic attempt at")
 n n A generative model Models each word in a")


















 For each document, find the optimizing")










- Slides: 37
Latent Dirichlet Allocation a generative model for text David M. Blei, Andrew Y. Ng, Michael I. Jordan (2002) Presenter: Ido Abramovich
Overview n n n n Motivation Other models Notation and terminology Latent Dirichlet allocation method LDA in relation to other models A geometric interpretation The problems of estimating Example
Motivation What do we want to do with text corpora? classification, novelty detection, n summarization and similarity/relevance judgments. n Given a text corpora or other collection of discrete data we wish to: n ¨ Find a short description of the data. ¨ Preserve the essential statistical relationships
Term Frequency – Inverse Document Frequency n n n tf-idf (Salton and Mc. Gill, 1983) The term frequency count is compared to an inverse document frequency count. Results in a txd matrix – thus reducing the corpus to a fixed-length list Basic identification of sets of words that are discriminative for documents in the collection Used for search engines
LSI (Deerwester et al. , 1990) n Latent Semantic Indexing ¨ Classic attempt at solving this problem in information retrieval ¨ Uses SVD to reduce document representations ¨ Models synonymy and polysemy ¨ Computing SVD is slow ¨ Non-probabilistic model
p. LSI Hoffman (1999) n n A generative model Models each word in a document as a sample from a mixture model. Each word is generated from a single topic, different words in the document may be generated from different topics. Each document is represented as a list of mixing proportions for the mixture components.
Exchangeability n A finite set of random variables is said to be exchangeable if the joint distribution is invariant to permutation. If π is a permutation of the integers from 1 to N: n An infinite sequence of random is infinitely exchangeable if every finite subsequence is exchangeable
bag-of-words Assumption n Word order is ignored “bag-of-words” – exchangeability, not i. i. d Theorem (De Finetti, 1935) – if are infinitely exchangeable, then the joint probability has a representation as a mixture: For some random variable θ
Notation and terminology n n n A word is an item from a vocabulary indexed by {1, …, V}. We represent words using unit-basis vectors. The vth word is represented by a Vvector w such that and for A document is a sequence of N words denoted by , where is the nth word in the sequence. A corpus is a collection of M documents denoted by
Latent Dirichlet allocation n LDA is a generative probabilistic model of a corpus. The basic idea is that the documents are represented as random mixtures over latent topics, where a topic is characterized by a distribution over words.
LDA – generative process 1. 2. 3. Choose For each of the N words : Choose a topic (b) Choose a word from , a multinomial probability conditioned on the topic (a)
Dirichlet distribution n A k-dimensional Dirichlet random variable θ can take values in the (k-1)-simplex, and has the following probability density on this simplex:
The graphical model
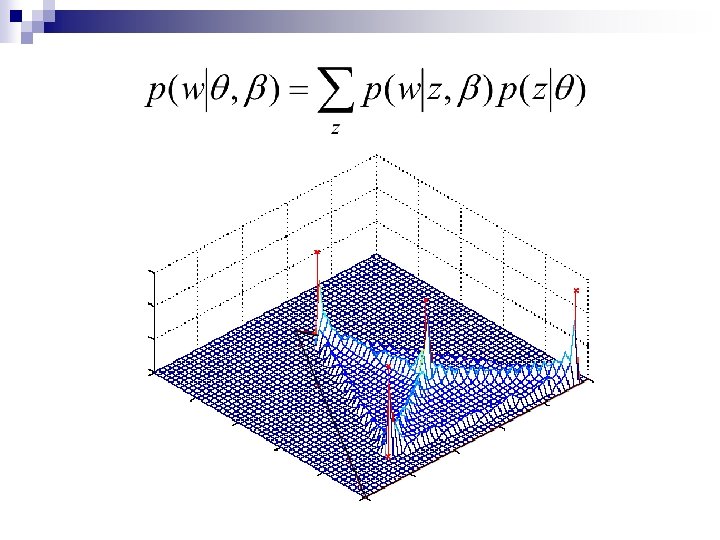
The LDA equations
LDA and exchangeability n n n We assume that words are generated by topics and that those topics are infinitely exchangeable within a document. By de Finetti’s theorem: By marginalizing out the topic variables, we get eq. 3 in the previous slide.
Unigram model
Mixture of unigrams
Probabilistic LSI
A geometric interpretation word simplex
A geometric interpretation topic 1 topic simplex word simplex topic 2 topic 3
A geometric interpretation topic 1 topic simplex word simplex topic 2 topic 3
A geometric interpretation topic 1 topic simplex word simplex topic 2 topic 3
Inference n We want to compute the posterior dist. Of the hidden variables given a document: n Unfortunately, this is intractable to compute in general. We write Eq. (3) as:
Variational inference
Parameter estimation n Variational EM ¨ (E Step) For each document, find the optimizing values of the variational parameters (γ, φ) with α, β fixed. ¨ (M Step) Maximize variational distribution w. r. t. α, β for the γ and φ values found in the E step.
Smoothed LDA n n n Introduces Dirichlet smoothing on β to avoid the “zero frequency problem” More Bayesian approach Inference and parameter learning similar to unsmoothed LDA
Document modeling n n . Unlabeled data – our goal is density estimation. Compute the perplexity of a held-out test to evaluate the models – lower perplexity score indicates better generalization.
Document Modeling – cont. data used n C. Elegans Community abstracts ¨ 5, 225 abstracts ¨ 28, 414 unique terms n TREC AP corpus (subset) ¨ 16, 333 newswire articles ¨ 23, 075 unique terms n n Held-out data – 10% Removed terms – 50 stop words, words appearing once (AP)
nematode
AP
Document Modeling – cont. Results n n n Both p. LSI and mixture suffer from overfitting. Mixture – peaked posteriors in the training set. Can solve overfitting with variational Bayesian smoothing. Perplexity Num. topics (k) Mult. Mixt. 2 22, 266 7, 052 5 2. 20 x 108 17, 588 10 1. 93 x 1017 63. 800 20 1. 20 x 1022 2. 52 x 105 50 4. 19 x 10106 5. 04 x 106 100 2. 39 x 10150 1. 72 x 107 200 3. 51 x 10264 1. 31 x 107 p. LSI
Document Modeling – cont. Results n n n Both p. LSI and mixture suffer from overfitting. p. LSI – overfitting due to dimensionality of the p(z|d) parameter. As k gets larger, the chance that a training document will cover all the topics in a new document decreases Perplexity Num. topics (k) Mult. Mixt. 2 22, 266 7, 052 5 2. 20 x 108 17, 588 10 1. 93 x 1017 63. 800 20 1. 20 x 1022 2. 52 x 105 50 4. 19 x 10106 5. 04 x 106 100 2. 39 x 10150 1. 72 x 107 200 3. 51 x 10264 1. 31 x 107 p. LSI
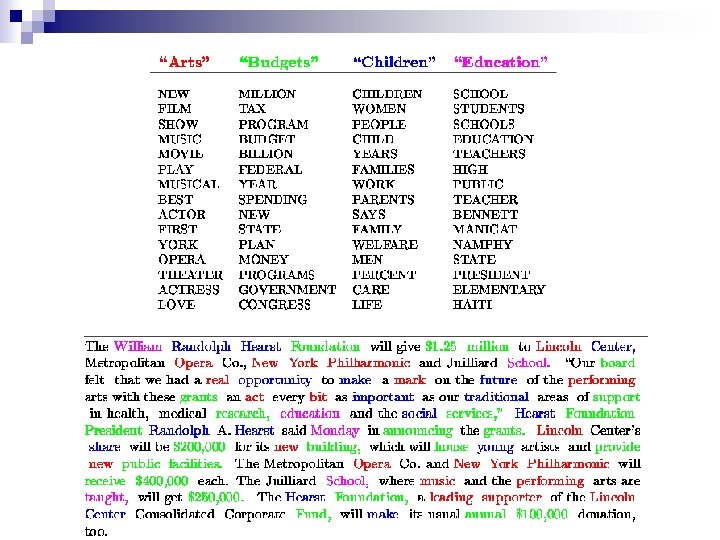
Other uses
Summary Based on the exchangeability assumption n Can be viewed as a dimensionality reduction technique n Exact inference is intractable, we can approximate instead n Can be used in other collection – images and caption for example. n