LanguageGrammarStatic BNF ContexFree Grammar ContexFree Grammar 1 Terminal
是由文法(Grammar)來描述其靜態(Static)結構。 而文法可藉由語法描述 具(如 BNF, Contex-Free Grammar)來表達。 一個 Contex-Free Grammar 共有四部份: 1. 一個由終端符號(Terminal Symbol /")
語言(Language)是由文法(Grammar)來描述其靜態(Static)結構。 而文法可藉由語法描述 具(如 BNF, Contex-Free Grammar)來表達。 一個 Contex-Free Grammar 共有四部份: 1. 一個由終端符號(Terminal Symbol / Token)所構成的集合。 2. 一個由非終端符號(Nonterminal Symbol)所構成的集合。 3. 一個由產生規則(Production rules)所構成的集合。 4. 並指出非終端符號中的一個作為開始符號(Start Symbol)。 Def: a context-free grammar consists of the following: 1. A set T of terminals. 2. A set N of nonterminals( disjoint from T) 3. A set P of productions, or grammar rules, of the form A where A is an element of N and is an element of (T N)* 4. A start symbol S from the set N. 1
表達")
語法解析程式之設計: 如何判定輸入敘述句合乎文法 ? z 語言由文法來描述其 static 結構 z 文法藉由 BNF (Backus-Normal / Naur Form)表達 英文句子( Sentence )用 BNF 描述,則如下述 <Sentence> : : = <Subject> <Verb> <Object> non-terminal <Subject> : : = <Noun> | <Noun> <Adverb> <Verb> : : = likes | gets | helps <Object> : : = <Noun> | <Adjective> <Noun> : : = Horse | Man <Adverb> : : = extremely | always <Adjective> : : = beautiful | dirty terminal 終端記號 以上述之文法( 以 BNF 描述者 )可以判斷下面三句是 真句子或不合乎句子之文法 Horse always helps dirty Man. (是句子) dirty Man extremely likes beautiful Horse. (不是句子) Man dirty gets Horse beautiful. (不是句子) 2
表示上頁之第一個句子 < Sentence > < Noun > < Adverb >")
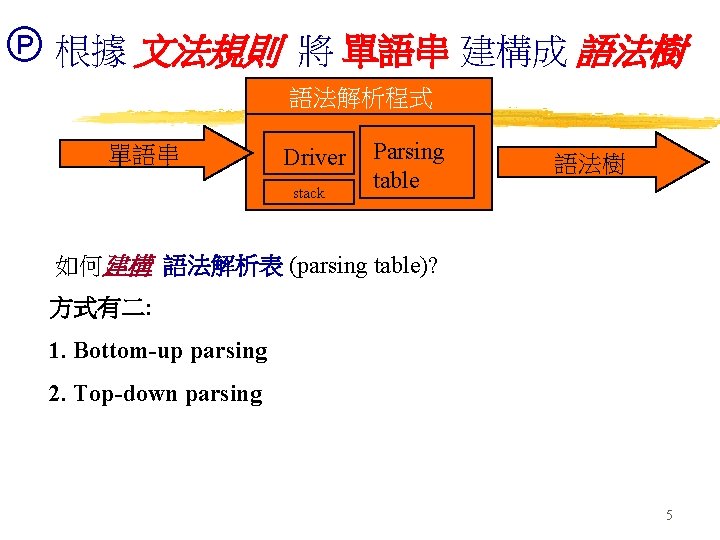
以圖形(構文樹 Parse tree ; 語法樹)表示上頁之第一個句子 < Sentence > < Noun > < Adverb > Horse always < Adjective > < Noun > dirty Man helps Button-up parsing < Object > < Verb > < Subject > 而語法(構文)解析程式之功能如下圖: ( 輸入 ) 單語串 驅動副程式 driver 構文解析表 parsing table 文法解析 : parsing ( 輸出 ) 構文樹 3

例如:Simplified Pascal Grammar. <prog> : : = PROGRAM <prog-name> VAR <dec-list> BEGIN <stmt-list> END. <prog-name> : : = id <dec-list> : : = <dec> | <dec-list> ; <dec> : : = <id-list> : <type> : : = INTEGER <id-list> : : = id | <id-list> , id <stmt-list> : : = <stmt> | <stmt-list> ; <stmt> : : = <assign> | <read> | <write> | <for> <assign> : : = id : = <exp> : : = <term> | <exp> + <term> | <exp> - <term> : : = <factor> | <term> * <factor> | <term> DIV <factor> : : = id | int | (<exp>) <read> : : = READ (<id-list>) <write> : : = WRITE (<id-list>) <for> : : = FOR <index-exp> DO <body> <index-exp> : : = id : = <exp> TO <exp> <body> : : = <stmt> | BEGIN <stmt-list> END 4
 例示: 有一組文法G定義如下: E E T T F F : : =")
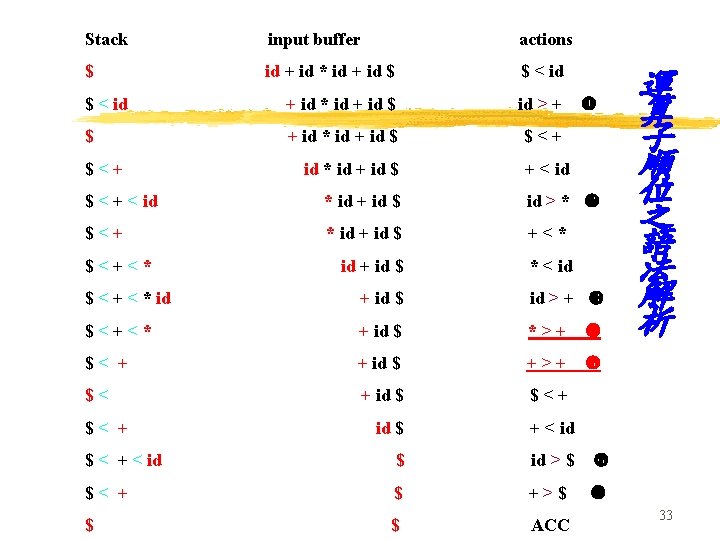
1. (LR 解析法) 例示: 有一組文法G定義如下: E E T T F F : : = E + T : : = T * F : : = (E) : : = id acc: accept; 接受 (done!) si: shift to state i ri: reduce the ith production state 0 1 2 3 4 5 6 7 8 9 10 11 1. 2. 3. 4. 5. 6. 根據左邊之文法G定義之文法解析表(parsing blank: error occurs id s 5 s 5 + Action * ( ) s 4 $ s 6 r 2 s 7 r 2 acc r 2 r 4 r 4 r 6 r 6 s 6 r 1 r 3 r 5 r 6 s 4 s 4 s 7 r 3 r 5 s 11 r 3 r 5 table) E 如下: Goto T F 1 2 3 8 2 3 9 3 10 r 1 r 3 r 5 LR Parser 單語串 Input buffer Driver stack Parsing table 語法樹 6

STACK 0 INPUT BUFFER actions id * id + id $ s 5 0 id 5 * id + id $ r 6 0 F 3 * id + id $ goto 3及 r 4 0 T 2 * id + id $ goto 2及 s 7 0 T 2 * 7 id + id $ s 5 0 T 2 * 7 id 5 + id $ r 6 0 T 2 * 7 F 10 + id $ goto 10 及r 3 0 T 2 + id $ goto 2及r 2 0 E 1 + id $ goto 1及s 6 0 E 1 + 6 id $ s 5 0 E 1 + 6 id 5 $ r 6 0 E 1 + 6 F 3 $ goto 3及r 4 0 E 1 + 6 T 9 $ goto 9及r 1 0 E 1 $ goto 1及accept ! 7

E 8 E T 2 F 1 * + 4 F id 3 T 7 F 6 id Bottom-up parsing T 5 id 想一想: (1) How to create the LR parsing table ? (2) How many LR parsing tables are there ? 8
 Canonical LR parsing table { LR} , (1) Simple")
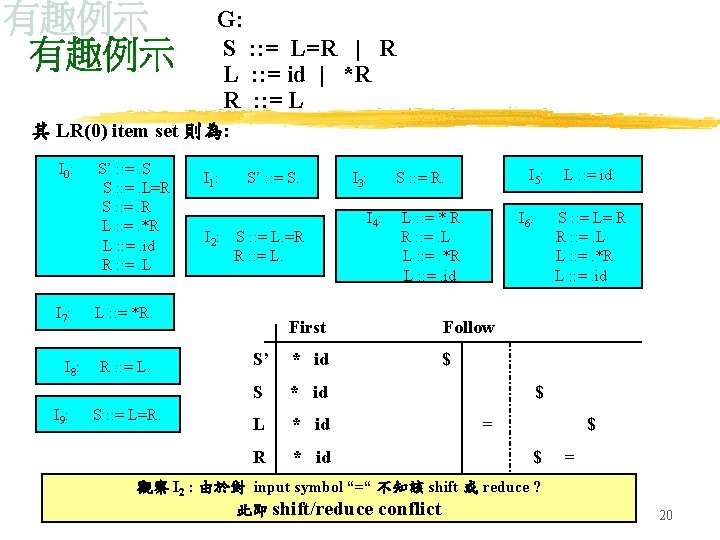
LR Parsing tables include: (2) Canonical LR parsing table { LR} , (1) Simple LR parsing table {SLR} 態同長法產三利 數唯相解生種用 不有均析的方左 同狀相表語法述 (3) Look. Ahead LR parsing table {LALR} SLR parsing table 之建構流程: (you might recall the processing of NFA DFA) (一) 增加一條語法規則 (0)S’ : : = S {S表文法之start symbol} 於文法G中, 令 新語法名曰 G’ (二) 計算 items I 之 closure集合 closure(I) (三) 計算 grammar symbol X 之 goto值 I’ goto(I, X) 並求其 closure(I’) (四) 重覆上一步驟直到不再產生新的 goto值 {而得 item set} (五) 計算所有 nonterminals 之 FIRST 與 FOLLOW集合 (六) 藉 Item 與 FOLLOW 兩集合建置 parsing table 9

例示: 0. 1. 2. 3. 4. 5. 6. id E’ : : = E E : : = E + T E : : = T T : : = T * F T : : = F F : : = (E) F : : = id E’ . E E . E+T E . T T . T*F T . F F . (E) F . id I 0: E I 1: E’ E. E E. +T T F T + I 4: F (. E) E . E+T E . T T . T*F T . F F . (E) F . id I 8: F (E. ) E E. +T I 5: F id. I 3: T F. I 2: E T. T T. *F ( * I 6: E E+. T T . T*F T T . F F . (E) F . id ) I 9: E E+T. T T. *F I 11: F (E). Canonical LR(0) collection for grammar G’ I 7: T T*. F F . (E) F . id F I 10: T T*F. 10
 = * *")
3. 要計算出 FOLLOW 集合卻不能不先求 FIRST, Why ? By Definition: FIRST( ) = * * { a| a } { | } * * FOLLOW(A) = { a| S Aa } {$|S A} Here are conventions: Terminals: a, b, c, d, 0, 1, +, (, ), begin Non-terminals: A, B, C, D, S, <word> Vocabulary symbols: U, V, W, X, Y, Z Strings of terminals: u, v, w, x, y, z Strings of vocabulary symbols: , , A : : = * is the same as A means n times derivation, for n 0 12
 集合之計算可依下列三 步驟而得: 1. If X , then FIRST(X) = { X }.")
根據定義, FIRST(X) 集合之計算可依下列三 步驟而得: 1. If X , then FIRST(X) = { X }. 2. If X : : = , then add to FIRST(X). 3. If X N, and X : : = Y 1 Y 2. . . Yn , then add all non- elements of FIRST(Y 1) to FIRST(X), if FIRST(Y 1), then add all non- elements of FIRST(Y 2) to FIRST(X), . . . if FIRST(Yn), then add to FIRST(X). 13

 集合之計算可依下列三 步驟而得: 1. Put $ into FOLLOW(S’) 2. For each A B")
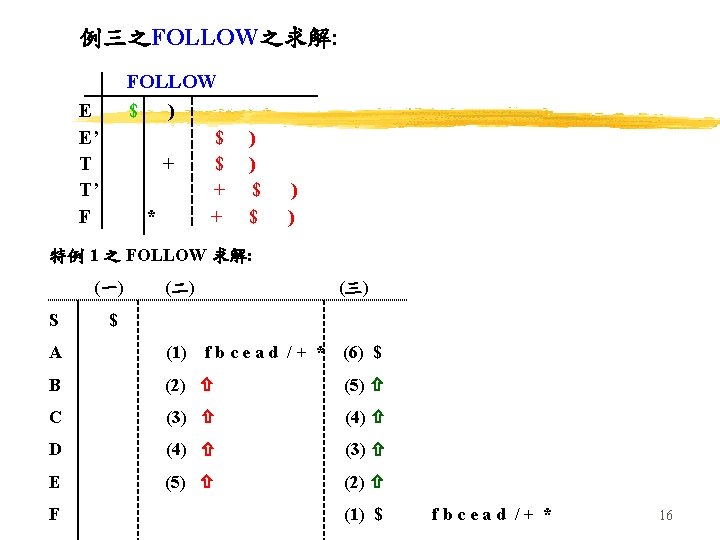
根據定義, FOLLOW(X) 集合之計算可依下列三 步驟而得: 1. Put $ into FOLLOW(S’) 2. For each A B , where add all non- elements of FIRST( ) to FOLLOW(B) 3. For each A B or A B , where FIRST( ) add all of FOLLOW(A) to FOLLOW(B) 以本章之第一例示而言, 其FIRST 與 FOLLOW可求解如下: FIRST FOLLOW E’ ( id $ E ( id + T ( id * F ( id ) $ + ) $ * + ) $ 15

I 3 F I 0 I 1 E I 6 + T I 4 I 5 I 2 F I 7 ( id T I 9 * F I 7 * I 10 id ( I 5 ( I 3 I 6 id + I 4 E I 8 ( I 5 I 11 T I 2 F id ) I 3 17
 shift")
藉 Item 與 FOLLOW 兩集合建置 parsing table 對於每一個state Ii , 其action 之決定乃根據下述五者之一行之: (1) shift action: 若 [ A : : = . a ] 在 Ii 中, 且 goto (Ii , a) = Ij , a , 則令 action[i. a] = <shift> j (2) reduce action: 若 [ A : : = . ] 在 Ii 中, 此處 A S’ , 則對集合 FOLLOW(A)中之每一個input symbol a , 令 action[i, a] = <reduce> 文法A : : = (3) accept action: 若 [S’ : : = S. ] 在Ii 中, 則 令 action[ i, $] = accept (4) goto action: 若 Ii 中 dot(. )之前面是non-terminal A; 即 GOTO (Ii , A) = Ij , 則 令 GOTO [ i, A] = j (5) 無法被上述action 所定義之表格欄位則是 錯誤欄 18
")
1. Once a parsing table is done, the said grammar G is called SLR(1) grammar. 2. 每一個SLR(1)文法必定非曖昧(unambiguous), 然而 也有一些非曖昧文法卻不是SLR(1)文法; 如次頁之例. 其原因乃在於SLR(1)不足於記憶已看過之資訊(e. g. left context), 也因而有canonical與Look. Ahead LR 之世出. 3. 曖昧文法(ambiguous grammar)之定義: A grammar that produces more than one parse tree for some sentence is said to be ambiguous. 1. Augment the grammar to G’ 2. Compute the FIRST & FOLLOW sets 3. Create the collection items (carefully judge the conflict) 4. Make the parsing table. 19
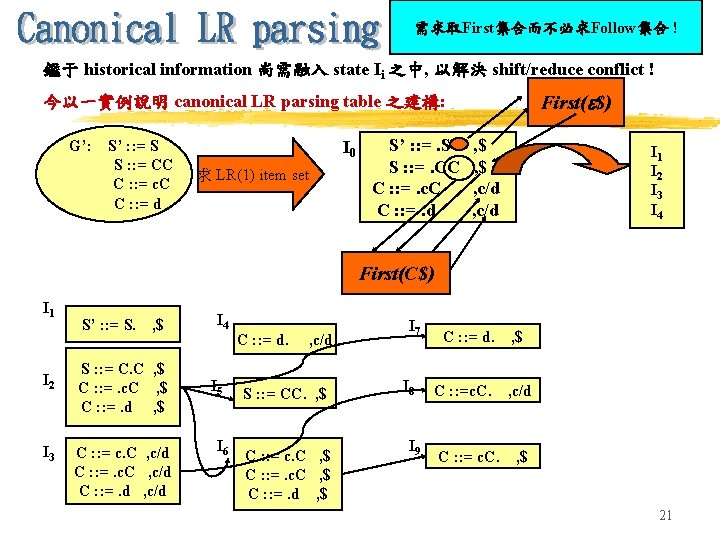

之建構步驟 1. Augment the grammar G into grammar G’. 2. Construct C={I 0, I 1, . . . , In}, the collection of sets LR(1) items for G’. 3. State i of the parser is constructed from Ii. The parsing actions for state i are determined as follows: (a) If [A . a , b] is in Ii and goto(Ii , a) = Ij, then set action[i, a] to “shift j. ” (b) If [A . , a] is in Ii , A S’, then set action[i, a] to “reduce A . ” (c) If [S’ S. , $] is in Ii , then set action[i, a] to “accept. ” If a conflict results from the above rules, the grammar is said NOT to be LR(1), and the algorithm is said to fail. 4. The goto transitions for state i are determined as follows: If goto(Ii , a) = Ij, then goto[i, a] = j. 5. All entries not defined by rules (3) and (4) are made “error”. 6. The initial state is I 0. 22

State 0 1 2 3 4 5 6 7 8 9 action c d s 3 s 4 $ goto S C 1 2 acc s 6 s 3 r 3 s 7 s 4 r 3 5 8 r 1 s 6 s 7 9 r 3 r 2 r 2 Canonical parsing table for grammar G’ Every SLR(1) grammar is an LR(1) grammar, but for an SLR(1) grammar the canonical LR parser may have more states than the SLR parser for the same grammar. The grammar of the previous example is SLR and has an SLR parser with seven states, compared with the ten shown above. 由於就 the number of states 而言, canonical LR parser 實在太 龐大, 因此時常難以落實, 而 SLR parser 卻又能力有所未逮, 於是 LALR parser 於焉誕生; 其狀態數與 SLR parser 完成相同, 然 shift/reduce conflict 較少發生. 23
. G: S ---> Aa. Ab")
1. Show that the following grammar G is not LR(1). G: S ---> Aa. Ab │ Bb. Ba A ---> ε B ---> ε 2. Prove S ---> a. Sa │ a is not LR(1). 3. Find the sets of FIRST and FOLLOW of every nonterminals of grammar G below. G: S ----> a │ (T) │ ε T ----> T@S │ S 24

4. Consider the following grammar E : : = E + T | T T : : = TF | F F : : = F* | a | b construct the SLR parsing table for this grammar. 5. Show that the following grammar S : : = Aa | b. Ac | Bc | b. Ba A : : = d B : : = d is LR(1). 6. Construct an SLR parsing table for the grammar E E sub R | E sup E | {E} | c R E sup E | E Resolve the parsing action conflict so that expressions will be parsed in the same way as by the LR parser. 25

FIRST S’ b, d S b, d A d B d a 0 action b c d s 3 s 5 1 2 4 7 8 acc s 6 3 s 9 4 5 $ GOTO S A B s 10 r 5 r 6 6 r 1 7 s 11 8 s 12 9 r 6 r 5 10 r 3 11 r 2 12 r 4 26
? Justify your answers. a. S id")
7. Which of the following grammars are SLR(1)? Justify your answers. a. S id = E; b. E E+P c. E P d. P id e. P (E) f. P id = E b. S id = A; A id = A A E E E+P E P P id P (A) 27

c. S id = A; d. A PE e. P id = P f. P g. E E+P h. E P i. P id j. P (A) d. NOT LR(1) S SAP e. S A f. A AP g. A P h. A i. P (a. P) j. P k. P b NOT LR(1) 28
 items. 2. 將所有 items")
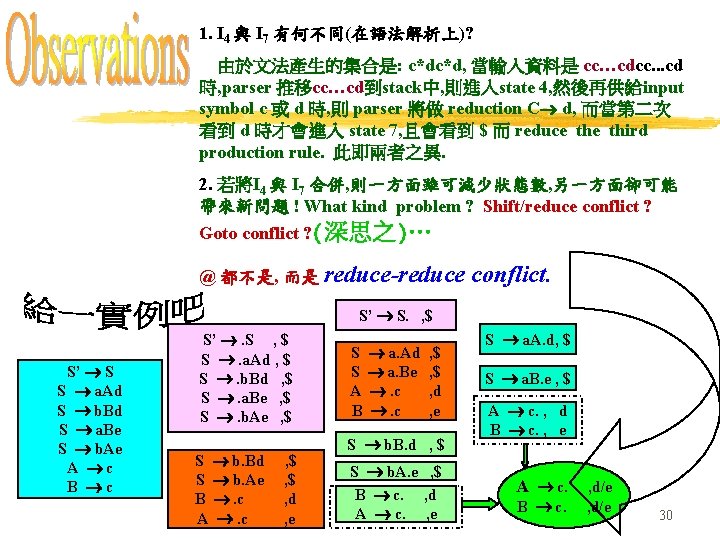
1. 根據 page 19之方法求得 a collection of sets of LR(1) items. 2. 將所有 items 中之 first components 相同者(the same cores )合併. 例示: 以 page 19之實例來說, 可資合併者包括: 3 and 6, 4 and 7, 8 and 9 等三對, 合併而成: I 36 C : : = c. C , c/d/$ C : : =. d , c/d/$ I 47 C : : = d. State Comes up with 0 1 2 36 47 5 89 , c/d/$ action c d s 36 s 47 I 89 C : : =c. C. $ , c/d/$ goto S C 1 2 acc s 36 r 3 s 47 r 3 r 2 5 89 r 3 r 1 r 2 29
 no production right side is , and")
1. 將文法改成 operator-precedence grammar ; 即 (1) no production right side is , and (2) no production has two adjacent nonterminals. 2. 求解所有 nonterminals 之 LEADING 與 TRAILING 兩集合; + LEADING(A) = { a | A Ka , K N { } } TRAILING(A) = { a | A a. K , K N { } } 3. 根據下列五者之一決定任意兩 terminals 之 precedences: (1) a = b if A : : = a. Kb (2) a < b (3) a > b + a. K if A : : = Bb and B + if S a. K (4) $ < a (5) a > $ + if A : : = a. B and B Kb + if S Ka 4. 利用 stack 與 上述方法產生之 parsing table 執行 語法解析( 以一實例說明之. ) 任意兩 terminals 之間必有順位值, 一旦看到 < 與 >成對, 即 reduce 該 sub-parse tree. 直到 左右兩“$” 遙遙相對即大功告成 ! 31
 P id LEADING TRAILING")
E E+T E T T T*P T P P (E) P id LEADING TRAILING E + + * T * ( P ( id * ( + * ( ) id $ + > < < > * > > < > ( < < < = < ) > > id > > $ < < id id ) * ) ) id id id acc 32
 最早的語法解析方式 例示 2. 可能需要back-tracking token S : : = c. Ad A :")
(一) 最早的語法解析方式 例示 2. 可能需要back-tracking token S : : = c. Ad A : : = ab A : : = a 若input string 是 cad 其 top-down parsing 如下: S c 1. 利用recursive procedure撰寫 A (1) S S d c A a d b (2) c A d a (3) Procedure A( ) begin Procedure S( ) isave = input-point begin if input symbol = ‘a’ then if input symbol = ‘c’ then ADVANCE( ) if input symbol = ‘b’ then if A( ) then ADVANCE( ) if input symbol = ‘d’ then return true ADVANCE( ) end if return true input-point = isave // 無法找到 ab // end if if input symbol = ‘a’ then ADVANCE( ) end if return true end if return false end if end 34
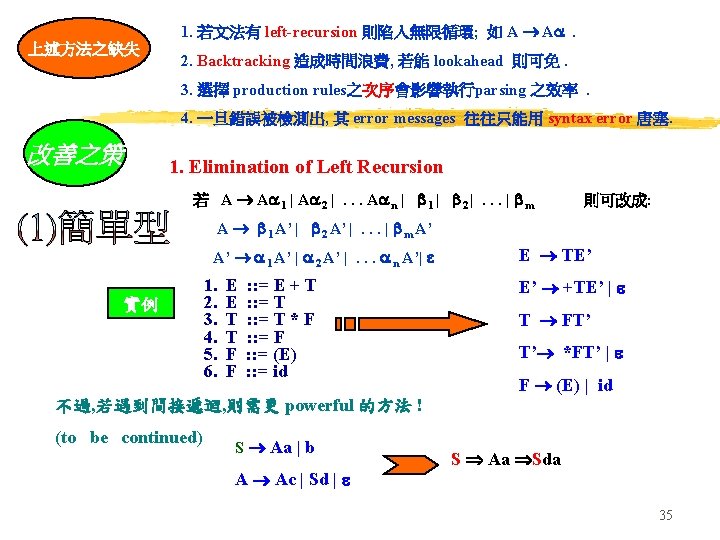

Input: Grammar G with no cycles or - productions. Output: An equivalent grammar with no left recursion. Method: (Note that the resulting non-left-recursive grammar may have - productions) 1. Arrange the nonterminals in some order A 1, A 2, . . . , An. 2. for i : = 1 to n do begin for j : = 1 to i-1 do begin replace each production of the form Ai Aj by the production Ai 1 | 2 |. . . | k , where Aj 1 | 2 |. . . | k are all the current Aj-productions; end eliminate the immediate left recursion among the Ai-productions end 36

S Aa | b We order the nonterminals S, A. A Ac | Sd | There is no immediate left recursion among the S-production, so nothing happens during step (2) for the case i =1. For i =2 , we substitute the S-productions in A Sd to obtain the following A-productions. A Ac| Aad | bd | Eliminating the immediate left recursion among the A-productions yields the following grammar. S Aa | b A bd. A’ | A’ A’ c. A’ | ad. A’ | 37


If A 1 | 2 |. . . | n | Then after left factoring process: A A’ | A’ 1 | 2 |. . . | n 實例 若文法G為 S i. Ct. S | i. Ct. Se. S | a C b 做了 eliminating left recursion 與 left factoring , 則文法 G可以 利用一種不需要 backtracking 之 recursive-decent parser (i. e. , a predictive parser) 外加 stack 來執行 Top-Down parsing. 則提左因子後: S i. Ct. SS’ | a S’ e. S | C b LL Parser 單語串 Input buffer Driver stack Parsing table 語法樹 39

1. 2. 3. 4. 5. 6. F T’ FIRST ( id * T E’ E ( + ( id E E T T F F : : = E + T : : = T * F : : = (E) : : = id E E’ T T’ F E TE’ E’ +TE’ | 經過 eliminating left recursion與 left factoring 之後 FOLLOW $ ) $ + * + T FT’ T’ *FT’ | F (E) | id ) ) $ $ ) ) How to create a predictive parsing table{ LL(1) }: 1. Compute the sets of First and Follow for each nonterminal. 2. For each production A of the grammar, do steps 3 and 4. 3. For each terminal a in First( ) , add A to M[A, a]. 4. If is in First( ) , add A to M[A, b] for each terminal b in Follow(A). If is in First( ) and $ is in Follow(A), add A to M[A, $]. 5. Make each undefined entry of M be error. 40

Id E Stack $E $ E’ T’ F $ E’ T’ id $ E’ T’ $ E’ T + $ E’ T’ F $ E’ T’ id $ E’ T’ F * $ E’ T’ F $ E’ T’ id $ E’ T’ $ E’ $ ( ) T FT’ E’ E’ T’ T’ T FT’ T’ F id $ E TE’ E’ +TE’ T’ F * E TE’ E’ T + T’ *FT’ F (E) Input Buffer id + id * id $ + id * id $ id * id $ id $ $ $ $ Actions 1. M[E, id] = E TE’ 2. M[T, id] = T FT’ 3. M[F, id] = F id Pop-up id & advance to next token 4. M[T’, +] = T’ 5. M[E’, +] = E’ +TE’ Pop-up + & advance to next token 上表謂之 LL(1) parsing table. 41

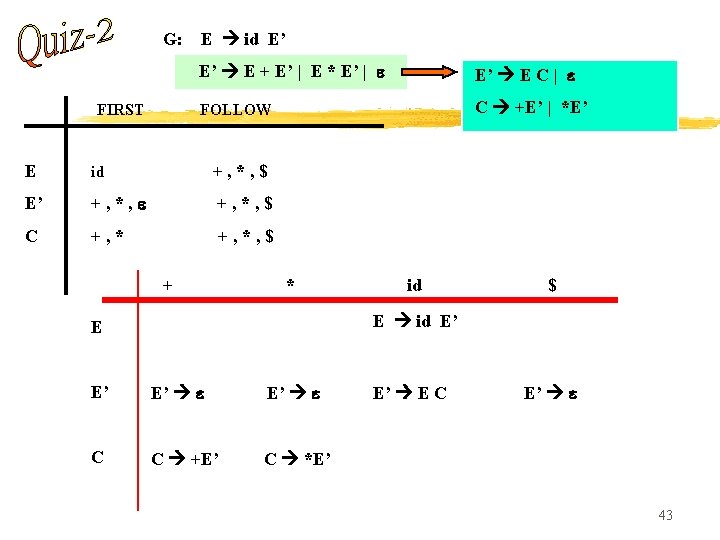
G: S 2 S’ FIRST S’ 1 AS’ | A B 1 A | B 3 B’ B’ B 1 | 1 S’ A S S’ $ S’ 1, $ A 3, 1, $ B 3 1 B’ 3, 1 $ 3 2 S’ S’ A A B’ 2 1 AS’ B B’ S 2 S FOLLOW A B 1 A B 3 B’ B’ B 1 42

A Production rule is written as or : : = . A phrase structure grammar G is a quadruple (N, , P, S), where N: finite set of non-terminals. S: finite set of alphabet (terminals). P: a set of products. S: the start symbol. Example: G 1 = ({A, S}, {0, 1}, P, S) where P is S 0 A 1 0 A 00 A 1 A If is a string in (N )* and is a production in G, then we say directly derives and write . + : derives in one or more steps. * : derives in zero or more steps. 44

* If S then is called a Sentential Form of G. * If S x then x is called a Sentence of G. * The language generated by G, written L(G), is {x| x * and S x} Now, G 1 = ({A, S}, {0, 1}, P, S) where P is S 0 A 1 0 A 00 A 1 A , therefore L(G 1) = {0 n 1 n | n > 0} CONVENTIONS: Terminals: a, b, c, d, 0, 1, +, (, ), begin Non-terminals: A, B, C, D, S, <word> Vocabulary symbols: U, V, W, X, Y, Z Strings of terminals: u, v, w, x, y, z Strings of vocabulary symbols: , , 45
 for all , |")
Type 0: Unrestricted Grammars any Type 1: Context Sensitive Grammars(CSG) for all , | | G 2 = ({S, B, C}, {a, b, c}, P, S) P: S a. SBC S ab. C CB BC b. B bb b. C bc c. C cc Which Type ? What the language is? Type 2: Context Free Grammars(CFG) for all , N (i. e. , A ) Type 3: Right (or Left)-Linear Grammars if all productions are of the form A x or A x. B G 3 : S S+S S S*S S (S) S a Which Type ? What language ? 46

An Ambiguous Grammar is one for which some sentence has two or more different parse trees. // Show that the last one at previous page is ambiguous grammar// // Try to prove the following CFG grammar is ambiguous: S AB | CD A 0 A | B 1 B 2 | C 2 C | D 0 D 1 | // // Try to prove the following CFG grammar is ambiguous: S if X then S | M M if X then M else S X X+T|T T T*F| F F (X) | a // 47

L = {0 n 1 n | n 1} is a Context Free Language ? Yes, since S 0 S 1 | 01 generates L. A RECOGNIZER is a machine (system) with a finite description that can accept a terminal string for some grammar and determine whether the string is in the language accepted by the grammar. A PARSER can, in addition, find a derivation for the string. PARSING Alternatives: Suppose we want to parse id * id + id E E + T T F id * T in G 0 : E E + T | T T T*F|F F (E) | id , then F F id id This parse tree might be created with left-most derivation or right-most derivation as follows: 48

E lm E + T T * P + T P * P + T id * id + P lm id * id + id Try it yourself ! 49

Prove the grammar G with productions S 0 S 1 | 01 accepts exactly L={0 n 1 n | n 1} PROOF: First show L(G) L (i. e. , the grammar generates only string in L. ) Inductive hypothesis: If w L(G) derived in k steps, then w L. Basis: k=1, the only one-step derivation is S 01 and 01 L. Inductive step: assume inductive hypothesis is true for k = k 0 1; show true for k = k 0 +1>1. K-1 Since k >1 the first step must be S 0 S 1 0 x 1 = w. K-1 But S x is of no more then k 0 steps, so by hypothesis x L, say x = 0 i 1 i , i 1. Then w = 0 x 1 = 0 i+11 i+1 L. Now show L L(G) (i. e. , the grammar generates all strings of L. ) Inductive hypothesis: If w L and |w| = 2 k, w L(G). Basis: k=1, the only string in L of length 2 is 01. But S 01 so 01 L(G). Inductive step: assume inductive hypothesis is true for k=k 0 1; show true for k = k 0 +1>1. Since the length of w is 2 k, w = 0 k 1 k. By inductive hypothesis 0 k-11 k-1 L(G) and thus * * S 0 k-11 k-1. So S 0 S 1 0 0 k-11 k-1 1 = w is a valid derivation for w. Thus w L(G). L L(G), so L = L(G). 50
 is a septuple P=(Q, , q 0, z, F), where")
A Push-Down Automaton (PDA) is a septuple P=(Q, , q 0, z, F), where Q is finite set of states, S is a finite input alphabet, G is a finite stack alphabet, maps elements of Q x ( x { }) x into finite subsets of Q x * q 0 Q is start state, z is start stack symbol, F Q is set of final states. Example: Let P=({q 0, q 1, q 2}, {0, 1}, {Z, 0}, , q 0, Z, {q 0}) where (q 0, 0, Z) = {(q 1, 0 Z)} (q 1, 0, 0) = {(q 1, 00)} (q 1, 1, 0) = {(q 2, )} (q 2, , Z) = {(q 0, )} L(P)={0 n 1 n| n 0} ? Why ? 51
 Q x * x")
A Configuration of P is a triple (q, w, ) Q x * x *. A Move (q, aw, Z ) (qi , w, i ) occurs if (qi , i ) (q, a, Z). An Initial Configuration is (q 0, w, Z). A string w is Accepted by P if (q 0, w, Z) * (q, , ) for q F, *. The Language Accepted by P, L(P) is the set of all strings P accepts. 接續上一頁之話題: (q 0 , 0011, Z) (q 1 , 011, 0 Z) (q 1 , 11, 00 Z) (q 2 , 1, 0 Z) (q 2 , , Z) (q 0 , , ) 用 暫代 Now, try to build a PDA that accepts L={ww. R | w (0, 1)+}. 52
 = {(q 0 , 0 Z) } (q 0")
(q 0 , Z) = {(q 0 , 0 Z) } (q 0 , 1 , Z) = {(q 0 , 1 Z) } (q 0 , 1) = {(q 0 , 01) } (q 0 , 1 , 0) = {(q 0 , 10) } (q 0 , 0) = {(q 0 , 00), (q 1 , ) } (q 0 , 1) = {(q 0 , 11), (q 1 , ) } Two items are included, thus it is a Nondeterministic PDA. (q 1 , 0) = {(q 1 , ) } (q 1 , 1) = {(q 1 , ) } (q 1 , , Z) = {(q 1 , ) } 53
. q Q, Z , whenever (q")
A Deterministic PDA is one in which (1). q Q, Z , whenever (q , , Z) , then (q , a , Z)= a . (2). q Q, a ( { }), Z , (q , a , Z) contains at most one element. Converting a CFG to a PDA : ª For each production A , make (q, ) (q , , A). ª For each a , make (q, ) (q , a). Show whether some specific language L is a CFL ? 1. If L is NOT a CFL, then we may prove it by pumping lemma of CFL. 2. If L is a CFL, then we may prove it by 3. (a) giving a deterministic/nondeterministic pushdown automaton for L( but 4. sometime this DPDA doesn’t exist, since DPDA accepts only a subset of 5. 6. all CFL’s) or, (b) giving a context-free grammar for L. 54

Theorem: For any CFL L, there exists a constant p depending on L such that z L, where |z| p, z may be written as z = uvwxy such that 1. |vx| 1 (i. e. , both are not ) 2. |vwx| p 3. uviwxiy L i 0. {證明相似於 RE. } Prove L ={ aibici | i 0} is NOT a CFL. Proof: If it were, by pumping lemma of CFL, p>0 z L where |z| p, let z = apbpcp = uvwxy such that (i). |vx| 1 (ii). |vwx| p (iii). uviwxiy L i 0. 55
 suppose vwx = aj , j p, then uwy = ap-lbpcp L,")
But (1) suppose vwx = aj , j p, then uwy = ap-lbpcp L, since |vx| 0, l 0. It is a contradiction to (iii) uwy L when let i=0. The same argument holds for vwx = bj or vwx = cj. (2) suppose vwx = ajbk , j, k p, then uwy = ap-l’bp-l’’cp L, since |vx| 0, either l’ 0 or l’’ 0 or both. It is a contradiction to (iii) uwy L when let i=0. The same argument holds for vwx = bjck. (3) suppose vwx = ajbpck , but |vwx| p, so vwx cannot contain both a’s and c’s. Thus, there are no pumpable substrings. It concludes that L cannot be context free. 56
 = { w |")
Begin by extending to FIRSTk and FOLLOWk: * FIRSTk( ) = { w | ( |w| < k and w) or ( |w| = k and wx for some x) } * * The domain of FIRSTk is extended to sets of strings in the natural way. * FOLLOWk(A) = { w | S A and w FIRSTk( ) } G is LL(k) for some fixed k iff whenever there are two leftmost derivations S w. A w w x and S w. A w w y and , then FIRSTk(x) FIRSTk(y). 57

S Abc | a. Acb A | b | c For left-sentential form S: FIRST 1(Abc) = { b, c } FIRST 1(a. Acb) = { a } For left-sentential form Abc: FIRST 1( bc) = { b } FIRST 1(bbc) = { b } FIRST 1(cbc) = { c } FIRST 2( bc) = { bc } FIRST 2(bbc) = { bb } FIRST 2(cbc) = {cb } No multiply defined entries In left-sentential form Acb: FIRST 2( cb) = { cb } FIRST 2(bcb) = { bc } FIRST 2(ccb) = {cc } No multiply defined entries We know LL(2) grammar. 58

FIRST 1 FOLLOW 1 FIRST 2 FOLLOW 2 S a, b, c $ ab, ac, bb, bc, cb $$ A , b, c bc, cb Some grammars are not LL(k) for any k. For instance, S A|B A a. Ab | 0 B a. Bbb | 1 L(G) = {an 0 bn | n 0} {an 1 b 2 n | n 0} is not LL(k). Assume it were, S A an 0 bn , S B an 1 b 2 n for any n. Let k = 2 m, m I+, then FIRSTk(a 2 m 0 b 2 m ) = FIRSTk(a 2 m 1 b 4 m ), But A B. Since k is arbitrary, the G is not LL(k) for any k. 59

1. Show that the following grammar 2. S Aa. Ab | Bb. Ba 3. A 4. B 2. is LL(1) but not SLR(1). Show that the following grammar 3. S Aa | b. Ac | dc | bda 4. A d 3. is LL(1). LR(1) ? SLR(1) ? Show that the following grammar 4. S Aa | b. Ac | Bc | b. Ba 5. A d 6. B d LALR(1). is LR(1). LL(1) ? Not 60
 parser for the simple programming language described below. Each time")
z Write an SLR(1) parser for the simple programming language described below. Each time the parser makes a reduction, print out the production used. ( Later this printing will be replaced by the generation of intermediate code, don’t scatter the print statements if that will cause trouble in the future. ) If you discover a syntax error in the input, issue an error message and discard the offending token. (We will assume all errors are caused by additional garbage in the input. ) Note: You need not write a program to build FIRST or FOLLOW, the canonical collection of items, or the parse table. These can be by hand. 61

<program> : : = <decl-list> <proc-list> <stmt-list> < decl-list> : : = <decl-list> <decl> | ε < decl > : : = DECLARE <id-list> : <type> <id-list> : : = <id-list>, <id> | <id> <type> : : = INT | CHAR <proc-list> : : = <proc-list> <proc> | <proc> : : = PROC <id> <stmt-list> CORP <stmt-list> : : = <stmt-list> <stmt> |ε <stmt> : : = <assign> | <if> | <loop> | <call> <assign> : : = <id> : = <expr> <if> : : = IF <test> THEN <stmt-list> ELSE <stmt-list> FI <loop> : : = FOR <id> : = <expr> TO <expr> DO <stmt-list> FOR <call> : : = CALL <id> <test> : : = <test> AND <alt> | <alt> : : = <alt> OR <rel> | <rel> : : = <expr> <relop> <expr> | ( <test>) | NOT ( <test> ) <relop> : : = > | > = | = <expr> : : = <expr> <addop> <term> | <term> <addop> : : = + | <term> : : = <term> <mulop> <prim> | <prim> <mulop> : : = * | / <prim> : : = ( <expr> ) | <id> | <number> | <char> The <id>, <number>, and <char> are tokens returned by the scanner. 62

TOKEN TYPES The Token. Type codes returned by the scanner (you should design it ! ) are shown below. Only <id>s, <number>s, <char>s, and keywords have a Token Value ----the index of the entry in the symbol table. All other tokens have NO_VALUE (0) for their Token. Value. DECLARE …. 1 INT …………. 3 CHAR ……… 4 PROC ………. 7 CORP ………. 8 FOR ………… 9 TO …………. 10 DO ………… 11 ROF ………. . 12 IF …………. . 13 THEN ……… 14 ELSE ………. . 15 FI …………… 16 CALL ………. 17 AND. . . 18 OR ………. … 19 NOT ………. . 20 <id>. . ……… 32 <number>…. . 33 <char>……. . . 34 , ………. . . 35 : ………. . . 36 : = ………. . 37 ( …………. . 38 ) ……. …… 39 > …………. 42 >= …………. 43 = …………. . 44 + …………… 46 - ……………. 47 * …………. . … 48 / …………. … 49 <eof>……. . . 100 63

GRADING The parser is due on Jan. 7 at the start of class. You should hand in the following: a.The first ten states in your canonical collection of items. b.Your complete parser table IN A READABLE FORMAT. If your table can be read easily form the listing you need not turn in another copy. DO NOT TURN IN YOUR ONLY COPY. c.The compiled listing of your program. d.The output of a run against PARSER DATA I (will be given later). Grading will be as follows: a.50%- Is the design correct ? Was proper use made of the SLR(1) techniques as discussed in class? b.40%- Were good programming techniques used? (This includes things like those listed in ELMENTS OF PROGRAMMING STYLE BY Kernighan and plauger. Also: minimizing globals; structuring data and control flow; using symbolic constants; mnemonic names; good comments; use of enumerated data types; perspicuous; naturalness of algorithm implementation; Consistent, readable indention; overall readablility. ) c.10% - Does it run properly on test data provided? d.10% - per day (or part thereof) penalty for late submission. 64
 grammar (b) regular grammar (c) context-free grammar. (10%) 2. A language")
1. Define (a) grammar (b) regular grammar (c) context-free grammar. (10%) 2. A language L is called a regular component if L = , for some , Show that every infinite regular language contains a component. (10%) 3. (1) Give three regular operations. (2) Let. Give three regular expressions over Σ. (10%) 4. (1) Give the definition of pushdown automaton. How a pushdown automaton move ? How a pushdown automaton accept a word ? How a pushdown automaton accept a language. (2) Give the definition of linear bounded automaton. (20%) 5. (1) Give the definition of Theorem. (2) Let Σ={a, b, c}. By using the Theorem show that the language L = is not a context-free language. 65
 What is the Chomsky Normal Form for context-free")
6. Answer the following questions. (1) What is the Chomsky Normal Form for context-free grammar ? (2) What is the Greibach Normal Form for context-free grammar ? (10%) 7. If and languages are context-free language, then the catenation and is a context-free language. Prove it. (10%) of the 8. Describe the so call Turing Machine if you can. (10%) 66
- Slides: 66