Korelacje i regresje Badajc dwie lub wicej cech

Korelacje i regresje Badając dwie lub więcej cech dla danej zbiorowości interesuje nas odpowiedź na pytania dotyczące wzajemnego związku tych cech oraz siły tego związku. Szczególnie jeśli jedna z badanych cech może być zależna od drugiej. Do przeprowadzenia analizy porównawczej w tym przypadku posłużą nam dwie techniki Korelacja i regresja. Pierwsza z nich opisuje siłę związku między cechami, druga opisuje ten związek czyli służy do opisania za pomocą funkcji związku między dwoma cechami.

Korelacja i regresja Podobnie jak w przypadku jednej cechy mamy dwie możliwości ustawienia wyników, uzależnione od ilości wyników, które są dla nas dostępne. • A) liczebność próby jest mała • B) liczebność próby jest duża • W przypadku A wpisujemy wyniki w tabelę Nr jednostki 1. . . . wartość cechy x xi. . . Wartość cechy y yi. . . .

Korelacja i regresja W przypadku B w tablicy korelacyjnej

Korelacja służy do pomiaru siły i kierunku związku pomiędzy dwiema lub więcej cechami Na początku zajmiemy się analizą wpływu dwu cech ilościowych. Jednym z interesujących związków pomiędzy dwoma cechami jest ich związek liniowy. Jak również odpowiedź na pytanie jak dalece związek między dwoma cechami odbiega od związku liniowego. Przedstawimy teraz techniki służące analizie takiego związku.

Korelacja Do pomiaru siły korelacji liniowej między dwoma cechami służy tzw. współczynnik korelacji liniowej Pearsona oznaczany rxy lub po prostu r. Jest on stosunkiem kowariancji zmiennych X i Y do iloczynu ich odchyleń standardowych, czyli

Korelacja gdzie

Korelacja lub dla tablicy korelacyjnej
 > 0 – dodatnia zależność korelacyjna")
Korelacja Uwaga cowariancja określa kierunek związku cov(x, y) > 0 – dodatnia zależność korelacyjna cov(x, y) = 0 – brak zależności korelacyjnej cov(x, y) < 0 – ujemna zależność korelacyjna

Korelacja Wykorzystując te wzory mamy dla współczynnika korelacji liniowej:

Korelacja Wykorzystując ten współczynnik możemy wyliczyć współczynniki rozbieżności oraz determinacji. Współczynnik determinacji liniowej cechy Y od X lub X od Y jest kwadratem współczynnika korelacji liniowej i najczęściej wyrażamy go w procentach:
 są uzależnione")
Korelacja Mówi nam on w ilu procentach zmiany cechy Y (lub X) są uzależnione od zmian cechy X (Y), a w ilu od pozostałych czynników zarówno losowych jak i nielosowych. Współczynnik rozbieżności jest dopełnieniem do 1 WDR.

Korelacja Właśności współczynnika r korelacja jest silniejsza w przypadku gdy a słabsza gdy

Korelacja Znak natomiast mówi o kierunku korelacji. Ogólnie możemy stwierdzić, że

Korelacja Na początku badania nad zależnością pomiędzy cechami należy sprawdzić czy korelacja pomiędzy nimi jest istotna. Procedura sprawdzająca polega na postawieniu dwu hipotez

Korelacja Gdzie ρ jest współczynnikiem korelacji w całej zbiorowości. Następnie ustalamy dopuszczalny błąd α (tzw. poziom istotności 0, 01; 0, 03; 0, 05 itp. ). Kolejnym krokiem jest odczytanie z tablic rozkładu t-Studenta wartości t(α , n 2), gdzie n-2 oznacza ilość stopni swobody. Mając to ustalone obliczamy z naszych danych wartość statystyki
 lub w drugim przypadku t>u(α, n) to lepszą jest hipoteza")
Korelacja Jeśli t>t(α, n-2) lub w drugim przypadku t>u(α, n) to lepszą jest hipoteza H 1 czyli współczynnik korelacji jest istotny. Czyli występuje istotna zależność pomiędzy cechami. W przypadku przeciwnym wnioskujemy, że nie ma istotnej zależności pomiędzy cechami.

Regresja liniowa Jak wspomnieliśmy wcześniej regresja służy do opisu związku pomiędzy cechami. Jest ona opisywana na ogół matematyczną zależnością nazywaną funkcją regresji. W przypadku rozważanym regresji liniowej Y od X lub (X od Y) funkcja ta jest nazywana funkcją regresji II – rodzaju a jej wykresem jest prosta nazywana prostą regresji. Oczywiście w przypadku rozważania cech X i Y uzyskamy dwie proste jedna z nich będzie prostą regresji cechy Y od X, druga natomiast prostą regresji X od Y.

Regresja liniowa Prosta regresji Y od X to funkcja zadana wzorem :

Regresja liniowa Gdzie α, β są parametrami strukturalnymi funkcji regresji i dla danych empirycznych przybliżane są przez a 1 a 0. I dane są wzorami
 lub spadnie")
Regresja liniowa a 1 - mówi o ile jednostek wzrośnie ( dodatnie) lub spadnie (ujemne) wartość cechy y jeśli wartość cechy x wzrośnie o jedną swoją jednostkę. Prosta regresji X od Y to funkcja zadana wzorem:

Regresja liniowa gdzie :

Regresja liniowa Aby wyznaczyć proste regresji nie musimy znać współczynnika korelacji liniowej. Wtedy aby wyznaczyć a 0 i a 1 rozwiązujemy następujący układ równań:

Regresja liniowa Stąd mamy

Korelacja liniowa a linie regresji Proste regresji w zależności od współczynnika korelacji liniowej można zobrazować następująco:

Korelacja liniowa a linie regresji

Korelacja liniowa a linie regresji

Korelacja liniowa a linie regresji Kąt możemy wyliczyć ze wzoru

Korelacja liniowa a linie regresji

Standardowy błąd oszacowania parametrów prostej regresji W dalszych rozważaniach zajmiemy się liniową funkcją regresji Y od X. Oczywiście oszacowując parametry liniowej funkcji regresji popełniamy pewien standardowy błąd oszacowania, który możemy wyliczyć ze wzoru:

Standardowy błąd oszacowania parametrów prostej regresji Gdzie W tym przypadku yi – oznacza wartości rzeczywiste zmiennej y

Standardowy błąd oszacowania parametrów prostej regresji Analogicznie możemy obliczyć standardowe błędy oszacowania dla parametrów a 1 i a 0 wtedy odpowiednie wzory będą miały postać:

Standardowy błąd oszacowania parametrów prostej regresji

Standardowy błąd oszacowania parametrów prostej regresji Podobnie jak przy sprawdzaniu czy współczynnik korelacji jest istotny tak i tutaj możemy sprawdzić czy współczynniki α, β są istotne. Procedura sprawdzania jest analogiczna i oparta o rozkład t-Studenta. Procedura sprawdzająca polega na postawieniu dwu hipotez

Standardowy błąd oszacowania parametrów prostej regresji Przy ustalonym poziomie istotności obliczamy z naszych danych wartość statystyk

Standardowy błąd oszacowania parametrów prostej regresji

Przykład 1 Zbadać zależność między miesięcznymi dochodami netto w tyś. złotych i wydatkami w zł. na osobę na produkty żywnościowe miejskich gospodarstw domowych, jeżeli z wylosowanych 9 gospodarstw trzyosobowych uzyskano następujące wyniki.

Przykład 1

Przykład 1 Wykonując obliczenia zgodnie z podanymi wzorami uzyskamy:

Przykład 1 ostatecznie uzyskamy prostą regresji Y od X opisaną wzorem:

Przykład 1 WDR który jest równy kwadratowi współczynnika korelacji wyrażonemu w procentach można policzyć z wzoru
 zatem")
Przykład 1 Istotność współczynnika korelacji : niech Stąd t=6, 241>2, 365=t(0, 05, 7) zatem zachodzi istotny związek pomiędzy wydatkami i dochodami gospodarstw.

Przykład 1 Standardowy błąd oszacowania liniowej funkcji regresji: Korzystając ze wzoru na liniową funkcję regresji wyliczamy kolejno

Przykład 1 Wyliczony błąd pozwala poprawić liniową funkcję regresji do postaci

Przykład 1 Powyższe wyniki pozwalają wysnuć następujące wnioski: • Współczynnik regresji oznacza, że korelacja między dochodami a wydatkami ma charakter ujemny. • Czyli wzrostowi dochodów netto na osobę o 1 tyś. złotych towarzyszy średnio rzecz biorąc, spadek wydatków na przetwory zbożowe o 14, 83 zł na osobę.

Przykład 1 WDR informuje nas o tym, że zmienność wydatków na przetwory zbożowe można w 83, 4% wyjaśnić zmiennością dochodów netto badanych gospodarstw. Pozostałe 16, 6% - współczynnik rozbieżności jest efektem działania innych czynników (losowych i nielosowych). Podsumowując możemy stwierdzić duży stopień dopasowania linii prostej do danych empirycznych.

Współczynnik korelacji rang Spearmana Przedstawimy teraz kolejny współczynnik, który jest szczególnie przydatny w przypadku badania zgodności opinii różnych grup ludności czy też w przypadku wyjaśnienia podejmowanych decyzji na podstawie siły wpływu na siebie różnych cech. Tym współczynnikiem jest współczynnik korelacji rang Spearmana

Współczynnik korelacji rang Spearmana Rangowanie cech polega na przyporządkowaniu poszczególnym wartościom cechy kolejnych numerów od 1 do n, według ustalonego kryterium. Jeśli cecha jest ilościowa to rangi nadajemy według rosnących lub malejących wartości cechy. Czyli porządkujemy rosnąco wartości cechy (lub malejąco) i kolejnym wartościom nadajemy numery 1, 2, 3, . . . , n (jeśli wartości są takie same to jako rangę biorę średnią arytmetyczną rang).

Współczynnik korelacji rang Spearmana Rangi możemy przypisać też cechom jakościowym o ile można je uporządkować w logicznej kolejności ( np. wykształcenie podstawowe, średnie, wyższe czy też stan zdrowia, bardzo zły, dobry, bardzo dobry, . . ). Współczynnik ten możemy zatem stosować nie tylko do analizy zależności cech ilościowych ale również do analizy zależności cech jakościowych.

Współczynnik korelacji rang Spearmana wyraża się wzorem

Współczynnik korelacji rang Spearmana gdzie:
 Załóżmy że, po przeprowadzeniu")
Współczynnik korelacji rang Spearmana Sposób obliczania współczynnika korelacji rang. 1) Załóżmy że, po przeprowadzeniu badania statystycznego uzyskaliśmy n wyników w postaci par (x 1, y 1) , . . . , (xn, yn). 2) Porządkujemy rosnąco wyniki xi i numerujemy kolejnymi numerami 1, 2, . . . , n (nadajemy im rangi)
Analogicznie postępujemy z odpowiadającymi im wartościami yi 4) Następnie wykorzystujemy")
Współczynnik korelacji rang Spearmana 3)Analogicznie postępujemy z odpowiadającymi im wartościami yi 4) Następnie wykorzystujemy wzór na rs Uwagi: Policzony współczynnik daje nam odpowiedź na pytanie o sile i kierunku zależności między cechami X i Y.

Współczynnik korelacji rang Spearmana

Współczynnik korelacji rang Spearmana Procentowy wpływ jednej cechy na drugą wyraża analogiczny jak w przypadku współczynnika liniowego współczynnik determinacji postaci

Współczynnik korelacji rang Spearmana Przykład 2 Sprawdzić jak silna jest zgodność opinii pracowników i uczniów odnośnie rangi wybranych pięciu szkół, jeśli po badaniach uzyskano następujące wyniki:

Współczynnik korelacji rang Spearmana

Współczynnik korelacji rang Spearmana Porządkujemy wyniki względem cechy X i odpowiadającej jej cechy Y

Współczynnik korelacji rang Spearmana Rangujemy wyniki i mamy

Współczynnik korelacji rang Spearmana W wyniku zastosowania wzoru na współczynnik korelacji i determinacji mamy:

Współczynnik korelacji rang Spearmana Stąd: • zgodność opinii pracowników i uczniów występuje tylko w 49%. • Siła zależności ustawienia szkół w rankingu przez pracowników i uczniów jest dość duża wynosi 0, 7 i ma kierunek dodatni (czyli opinie raczej się pokrywają, to znaczy uczniowie raczej wyżej ustawiają szkoły które wyżej zostały usytuawane przez pracowników).

Współczynnik tau-Kendalla Oprócz współczynnika korelacji rang Spearmana można użyć współczynnika rang Kendalla. Mówi on o tym samym niemniej czasem wygodniej go używać. Do jego obliczania stosujemy następujący algorytm:
 Rangujemy cechy 2) Dla cechy x ustawiamy rangi według porządku rosnącego")
Współczynnik tau-Kendalla 1) Rangujemy cechy 2) Dla cechy x ustawiamy rangi według porządku rosnącego 3) Dla cechy y ustawiamy rangi zgodnie z odpowiednikami w x 4) Tworzymy pary rang dla cechy y (wszystkie)
 Jeśli poprzednik w parze jest większy od następnika to przypisujemy notę")
Współczynnik tau-Kendalla 5) Jeśli poprzednik w parze jest większy od następnika to przypisujemy notę „-1” a jeśli jest na odwrót to notę „ 1” 6) Sumujemy wszystkie noty (V-suma not) lub tylko noty dodatnie –U) 7) Obliczamy współczynnik korelacji Kendalla odpowiednio ze wzorów

Współczynnik tau-Kendalla

Współczynnik tau-Kendalla W przykładzie 2 mamy : Rangi x – 1, 2, 3, 4, 5 Rangi y – 1, 2, 4, 5, 3 stąd możemy zestawić następujące pary z rang y oraz przypisać odpowiednie noty dla tych par

Współczynnik tau-Kendalla

Współczynnik tau-Kendalla Po obliczeniu współczynników uzyskujemy

Analiza cech jakościowych Badając współzależność cech niemierzalnych natrafiamy na podstawowy problem możliwości obliczenia np. średnich czy też kowariancji, zatem nie możemy stosować współczynnika korelacji liniowej. Zachodzi więc w sposób naturalny pytanie jak w tym przypadku określić występowanie współzależności między cechami ? , obliczyć jej siłę ?

Analiza cech jakościowych Z pomocą w tym przypadku przychodzi nam statystyczny rozkład chi -kwadrat. Za pomocą tego rozkładu możemy zbadać czy : 1) Występuje zależność między cechami. 2) wyznaczyć o ile występuje jej siłę.
 między cechami sprowadza się do weryfikowania hipotezy")
Analiza cech jakościowych Sprawdzanie występowania zależności (niezależności) między cechami sprowadza się do weryfikowania hipotezy H 0 - zależność nie występuje względem hipotezy, H 1 - zależność ta występuje. Aby przeprowadzić tę weryfikację postępujemy następująco :
 obliczamy empiryczną wartość statystyki")
Analiza cech jakościowych Dla danych zgrupowanych w tablicy korelacyjnej (kontyngencyjnej) obliczamy empiryczną wartość statystyki chi - kwadrat używając następującego wzoru.
 w")
Analiza cech jakościowych gdzie: nij – empiryczna częstość absolutna w tablicy korelacyjnej (kontyngencyjnej) w i –tym wierszu i j-tej kolumnie. eij - spodziewana częstość absolutna w i-tym wierszu i j-tej kolumnie.

Analiza cech jakościowych Czyli

Analiza cech jakościowych Odczytujemy z tablicy rozkładu chi-kwadrat wartość teoretyczną χ2α, r służącą do porównywania hipotez H 0 i H 1. Aby tę wartość odczytać z tablic, musimy ustalić α oraz ilość stopni swobody, dla których tę wartość odczytujemy. α jest poziomem istotności a liczbę stopni swobody ustalamy z wzoru

Analiza cech jakościowych Zależność występuje gdy zachodzi następujący związek pomiędzy chi-kwadrat wyliczonym i chi -kwadrat odczytanym

Analiza cech jakościowych Przykład 3 Wśród 300 wybranych losowo ludzi przeprowadzono ankietę dotyczącą stosowania przez nich specjalnej diety oraz wyników w zakresie zmian wagi, uzyskując następujące wyniki przedstawione w tablicy kontyngencyjnej. Przyjmując α=0, 05, zweryfikować hipotezę, że utrata wagi nie zależy od stosowania diety.

Analiza cech jakościowych

Analiza cech jakościowych Wyliczamy empiryczną wartość statystyki chi-kwadrat. W tym celu pomocniczo budujemy tabelę zawierającą wartości częstości eij.

Analiza cech jakościowych

Analiza cech jakościowych gdzie odpowiednie „eij” i chi – kwadrat wyniosą
=1 z tablic rozkładu")
Analiza cech jakościowych Dla naszego ustalonego α=0, 05 i r=(2 -1)=1 z tablic rozkładu chi-kwadrat odczytujemy

Analiza cech jakościowych Ponieważ 25>3, 841 zatem hipotezę H 0 mówiącą, że utrata wagi nie zależy od stosowania diety należy odrzucić. To oznacza, że utrata wagi zależy od stosowania diety. Oczywiście zachodzi teraz pytanie ( o ile cechy są zależne) w jakim stopniu zależą one jedna od drugiej. Na ile są skorelowane? I w jakim procencie jedna determinuje drugą. (czyli pytania o siłę determinacji.
 ale")
Siła zależności cech jakościowych Do pomiaru siły zależności dwóch cech (szczególnie jakościowych (niemierzalnych) ale nie tylko) służą następujące współczynniki korelacji ( nazywane często współczynnikami zbieżności): Są różne współczynniki przedstawimy kilka z nich wszystkie mówią o tym samym czy zależność cech jest silna czy słaba
")
Siła zależności cech jakościowych Współczynnik zbieżności Czuprowa (Txy)

Siła zależności cech jakościowych Uwaga: Współczynnik ten jak i pozostałe przyjmuje wartości z przedziału <0, 1>. Czym większa wartość tego współczynnika tym korelacja mocniejsza. Jeżeli chcemy wyrazić procentową zależność między cechami to wystarczy pomnożyć ten współczynnik przez 100. Współczynnik ten nie mierzy kierunku korelacji.
")
Siła zależności cech jakościowych Współczynnik korelacji V - Cramera: (Cxy)
 i C –Pearsona skorygowany ( gdy różna")
Siła zależności cech jakościowych Współczynnik C-Pearsona. (C) i C –Pearsona skorygowany ( gdy różna jest liczba wierszy i kolumn)

Siła zależności cech jakościowych Współczynnik Φ Yula

Siła zależności cech jakościowych Dla szczególnych tablic wymiaru 2 na 2 zamiast współczynników opartych na chi-kwadrat wylicza się współczynnik chi-kwadrat z poprawką Yatesa, czyli dla tablic postaci A C B D

Siła zależności cech jakościowych Mamy

Siła zależności cech jakościowych Dla przykładu 3 mamy

Korelacja wieloraka Jeśli chcemy wyznaczyć siłę związku liniowego pomiędzy wybraną cechą Y oraz zespołem cech X 1, . . . , Xn to powinniśmy wyznaczyć tzw. Współczynnik korelacji wielorakiej. (ozn. R). Algorytm wyznaczania tego współczynnika polega na wykorzystaniu rachunku macierzowego. Zakładamy, że ze zbiorowości losujemy próbkę m-elementową.
 pomiędzy cechą Y i")
Korelacja wieloraka Na początek tworzymy wektor współczynników korelacji liniowej (Pearsona) pomiędzy cechą Y i każdą z cech Xi, dla i=1, 2. . . , n. Niech ri oznacza współczynnik korelacji liniowej pomiędzy cechą Y i cechą Xi, wtedy nasz wektor można zapisać w postaci:

Korelacja wieloraka Kolejnym krokiem jest utworzenie macierzy współczynników korelacji liniowej pomiędzy cechami X 1, . . . , Xn ( czyli obliczenie każdego współczynnika korelacji liniowej ri, j pomiędzy cechą o numerze i i cechą o numerze j). Macierz ta ma postać:

Korelacja wieloraka

Korelacja wieloraka Z wektora Ro i macierzy RX budujemy macierz korelacji W następująco

Korelacja wieloraka Gdzie RT 0 oznacza macierz transponowaną Po tych krokach możemy obliczyć współczynnik korelacji wielorakiej pokazujący zależność pomiędzy cechą Y i zespołem cech X 1, . . , Xn.

Korelacja wieloraka Uwagi ! 1. Współczynnik R jest pomiędzy 0 i 1 2. Jeśli R=0 to występuje zupełny brak korelacji 3. Czym R bliższe 1 tym związek jest większy i można przejść do opisu zależności funkcyjnej liniowej. 4. Kwadrat współczynnika R wyrażony w procentach nazywamy współczynnikiem determinacji WDR=R 2*100.

Korelacja wieloraka Przed przystąpieniem do dalszych analiz należy podobnie jak w przypadku współczynnika korelacji liniowej sprawdzić czy korelacja jest istotna. Procedura sprawdzająca polega na postawieniu dwu hipotez

Korelacja wieloraka Ustalamy błąd α. Odczytujemy z tablic rozkładu F-Fishera. Snedecora wartości F(α, n, m-n-1) gdzie n i m-n-1 oznaczają ilość stopni swobody. Mając to ustalone obliczamy z naszych danych wartość statystyki

Korelacja wieloraka gdzie m- liczebność próbki, n – ilość zmiennych X. Korelacja jest istotna jeśli zachodzi

Model liniowy zależności Jeśli R nie jest bliski 0 to można opisać związek pomiędzy cechą Y i cechami X 1, . . . , Xn za pomocą modelu liniowego (regresji liniowej) postaci

Model liniowy zależności Współczynniki strukturalne αi estymujemy za pomocą wyznaczenia wektora

Model liniowy zależności ε - jest składnikiem losowym modelu. Zatem aby taki model zbudować należy wyznaczyć wektor „a”. Aby wyliczyć ten wektor tworzymy macierz obserwacji cech X ( tak jak tablicę korelacyjną z początku tej części dodając na początku kolumnę jedynek) oraz wektor obserwacji cechy Y czyli mamy

Model liniowy zależności

Model liniowy zależności Wtedy wektor a wyliczamy ze wzoru:

Model liniowy zależności Mając wyliczone nasze parametry model, który budujemy można zapisać w postaci

Model liniowy zależności Gdzie

Model liniowy zależności Mając taką postać łatwo obliczyć wektor reszt

Model liniowy zależności Oraz standardowy błąd oszacowania liniowej funkcji regresji

Model liniowy zależności Oczywiście nasza funkcja nie pokrywa się z rzeczywistą funkcją opisującą zjawisko Y uzależnione od zjawisk X 1, . . . , Xn. Zatem aby zobaczyć jak ona jest dopasowana należy policzyć tzw. Miary dopasowania we wzorach

Model liniowy zależności Współczynnik zbieżności informuje jaka część ogólnej zmienności cechy Y nie jest wyjaśniana przez równanie regresji

Model liniowy zależności Współczynnik determinacji informuje jaka część ogólnej zmienności cechy Y jest wyjaśniana przez równanie regresji

Model liniowy zależności Współczynnik zmienności losowej pokazuje on jaki jest procentowy udział standardowego błędu oszacowania w średniej arytmetycznej wartości cechy objaśnianej

Model liniowy zależności Podobnie jak w przypadku regresji liniowej dla dwu cech można zbadać istotność każdego parametru postępując analogicznie jak w przypadku dwu cech tzn: Procedura sprawdzająca polega na postawieniu dwu hipotez
 2) 3) Ustalamy dopuszczalny błąd α Odczytujemy z tablic rozkładu")
Model liniowy zależności 1) 2) 3) Ustalamy dopuszczalny błąd α Odczytujemy z tablic rozkładu t-Studenta wartość t(α, m-n-1) Obliczamy wartość statystyki

Model liniowy zależności gdzie Si są pierwiastkami elementów głównej przekątnej macierzy

Model liniowy zależności Współczynniki są istotne jeśli zachodzi:

Współczynniki korelacji cząstkowej Możemy zadać sobie pytanie jak uzależnić dwie wybrane cechy Xk, Xl od pozostałych cech Xi dla i=1, 2, . . . , n. Jest to o tyle ważne, że wpływ wybranych cech na Y nie wyklucza wpływu pozostałych cech na te dwie. Do tego celu służy tzw. WSPÓŁCZYNNIK KORELACJI CZĄSTKOWEJ

Współczynniki korelacji cząstkowej Obliczany dla naszych macierzy z wzoru:

Współczynniki korelacji cząstkowej gdzie

Jak to się robi w STATISTICA Rozważmy następujący przykład Oblicz współczynnik korelacji liniowej dla danych z poniższej tablicy oraz napisz równania prostych regresji.

Jak to się robi w STATISTICA Wpisujemy dane w kolumny
 Wybieramy moduł statystyki podstawowe i tabele 2)")
Jak to się robi w STATISTICA 1) Wybieramy moduł statystyki podstawowe i tabele 2) Wybieramy macierze korelacji 3) Deklarujemy w opcjach zmienne, poziom istotności p – nasze Dokładna tabela wyników
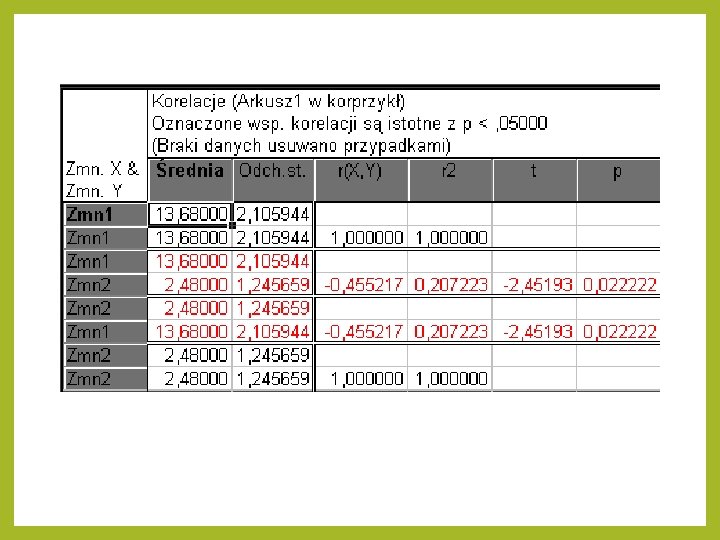

Jak to się robi w STATISTICA Uwagi: • Na czerwono program zaznacza istotne współczynniki korelacji • r(X, Y) współczynnik korelacji liniowej • p = 0, 0022222 – komputerowy poziom istotności : Jeśli ten p jest mniejszy od naszego błędu zadeklarowanego to występuje istotna statystycznie zależność między cechami

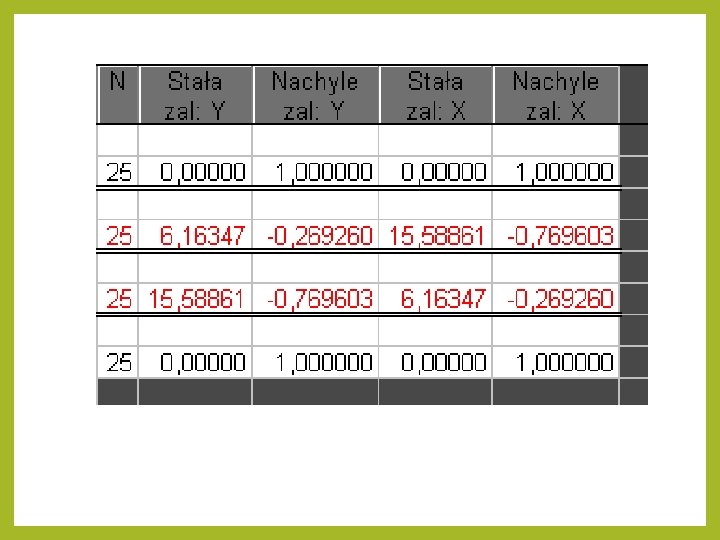
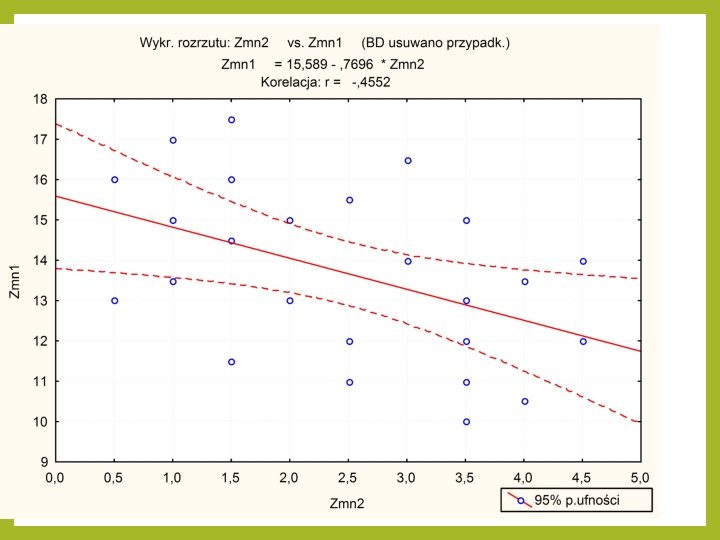
Jak to się robi w STATISTICA pozostałe kolumny odnoszą się do wzorów na proste regresji i tak Zmienna 2 = - 0, 27 Zmienna 1+6, 16 Zmienna 1 = - 0, 77 Zmienna 2+15, 59 Można również wybrać różne wykresy obrazujące naszą regresję

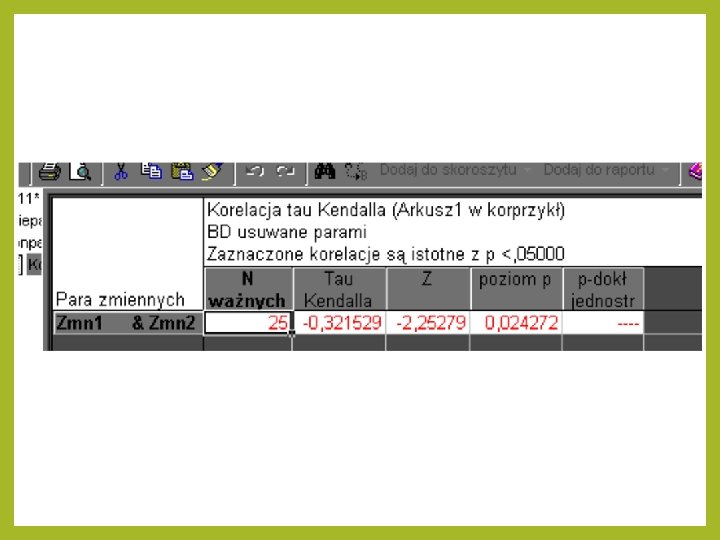
Jak to się robi w STATISTICA Inne współczynniki W module Statystyki wybieramy : · Statystyki nieparametryczne Następnie · Korelacje (Spearmana, tau kendalla, gamma) I dostajemy

Jak to się robi w STATISTICA

Jak to się robi w STATISTICA Dla cech jakościowych Przykład załóżmy że dla 50 osób badamy wpływ płci na wartość odpowiedzi w dowolnym pytaniu ankietowym o możliwościach wyboru a, b, c. Wpisujemy dane

 Wybieramy w module statystyki – statystyki podstawowe")
Jak to się robi w STATISTICA 1) Wybieramy w module statystyki – statystyki podstawowe i tabele – tabele wielodzielcze lub w przypadku odpowiedzi wielokrotnych – tabele wielokrotnych odpowiedzi 2) W opcjach ustalamy różne charakterystyki w tym jakość wyników, które chcemy uzyskać oraz współczynniki kontyngencji 3) W podsumowaniu dostajemy

Jak to się robi w STATISTICA

Jak to się robi w STATISTICA

Jak to się robi w STATISTICA Możemy też przedstawiać dane za pomocą różnych wykresów Dla przykładu wykresy zestawiające rozkład na odpowiedzi na pytanie względem płci
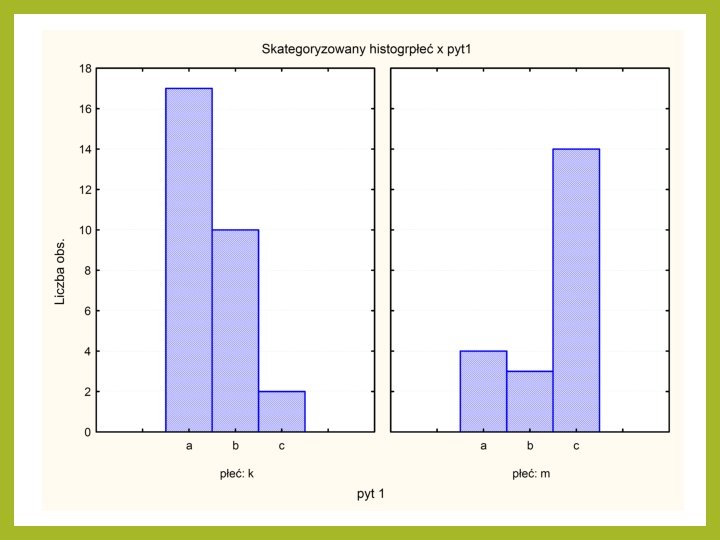

Jak to się robi w STATISTICA Korelacja i regresja wieloraka Dopiszmy do przykładu 1 kolejną zmienną Otrzymamy:
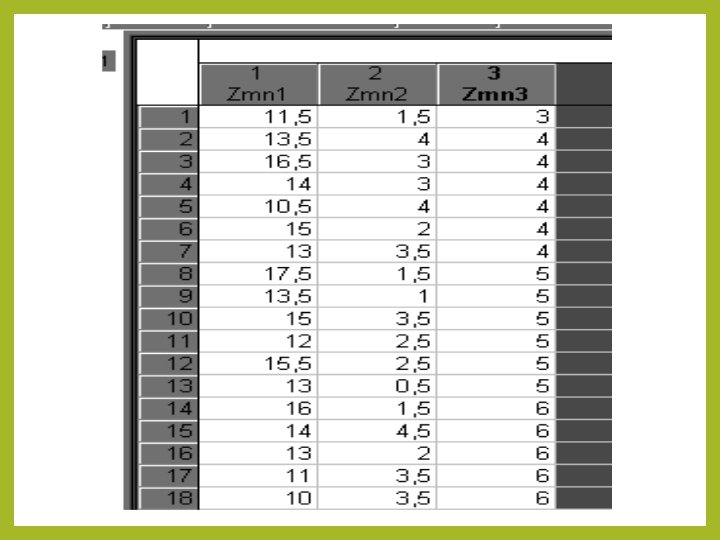
 W module statystyka wybieramy – regresja wieloraka")
Jak to się robi w STATISTICA 1) W module statystyka wybieramy – regresja wieloraka 2) Deklarujemy zmienną zależną i zmienne niezależne u nas zależna to Zmn 1, a niezależne to Zmn 2 i Zmn 3 naciskamy OK. i mamy

Jak to się robi w STATISTICA

Jak to się robi w STATISTICA Można dostać następujące zestawienie

Jak to się robi w STATISTICA gdzie BETA Zmn 2 oznacza współczynnik korelacji Zmn 1 i Zmn 2 BETA Zmn 3 oznacza współczynnik korelacji Zmn 1 i Zmn 3 p - odpowiednie poziomy istotności dla tych współczynników zatem wpływ Zmn 2 jest istotny a Zmn 3 nie jest istotny

Jak to się robi w STATISTICA B – oznacza odpowiednie współczynniki w modelu regresji liniowej czyli w naszym przypadku zmienną 1 można opisać przez zmienne 2 i 3 następująco: Zmn 1=-0, 76 Zmn 2+0, 008 Zmn 3+15, 16

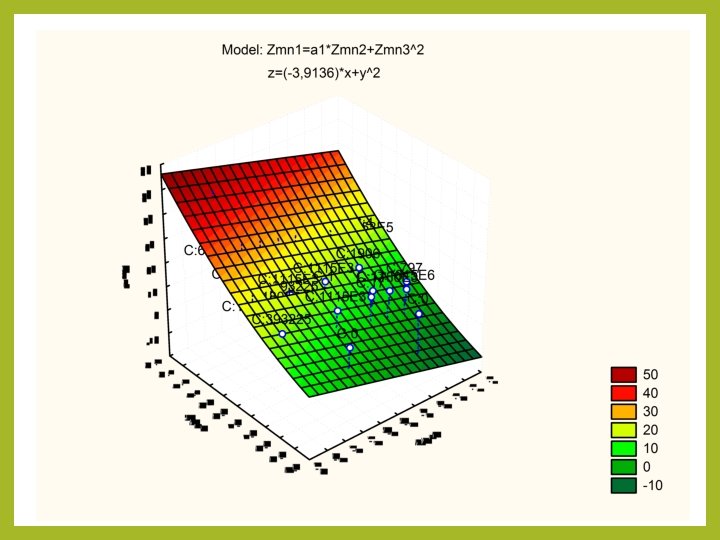
Jak to się robi w STATISTICA Oczywiście możemy też tworzyć modele nieliniowe Wtedy wybieramy pod moduł – modele liniowe i nieliniowe – ogólne modele regresji, określamy za pomocą dostępnych wyrażeń matematycznych wzór funkcji oraz metodę estymacji parametrów u nas jeśli dla przykładu zadeklarujemy, że wzór będzie postaci: Zmn 1=a 1*Zmn 2+Zmn 3^2 To dostaniemy

Jak to się robi w STATISTICA

Jak to się robi w STATISTICA oraz wykres zależności

Jak to się robi w STATISTICA Wśród metod estymacji mamy do wyboru między innymi a Metoda quasi-Newtona. Polega ona na tym, że w każdym kroku w różnych punktach oszacowuje się funkcję w celu estymacji pochodnych pierwszego i drugiego rzędu. Mówią one o tym w którym kierunku i jak szybko zmienia się nachylenie funkcji. Informację tę wykorzystuje algorytm w celu podążenia po pewnej ścieżce do minimum funkcji straty. Należy znać wartości początkowe
 Polega")
Jak to się robi w STATISTICA Metoda sympleksów. (opracowana przez Neldera i Meada) Polega na wyznaczeniu położenia minimum funkcji wielu zmiennych. Pozwala uniknąć „zdradliwych” zagrożeń jakimi są minima lokalnych. Metoda sympleksu i quasi – Newtona. Łączy zalety obu wcześniejszych metod. Pierwsza wyliczy wstępne wartości estymowanych parametrów, które zostaną wykorzystane w drugiej metodzie jako wartości początkowe.

Jak to się robi w STATISTICA Metoda Hooke’a – Jeevesa przemieszczenia układu. Metoda ta polega na przesuwaniu w każdej iteracji układu punktów w nowe miejsce przy czym długość kroków przesuwania jest stale modyfikowana aby trafić na optimum. Stosowana gdy poprzednie metody nie dają sensownych rezultatów. Metoda Hooke’a – Jeevesa i quasi-Newtona. Łączy zalety obu wcześniejszych metod. Pierwsza wyliczy wstępne wartości estymowanych parametrów, które zostaną wykorzystane w drugiej metodzie jako wartości początkowe

Jak to się robi w STATISTICA Metoda Rosenbroca poszukiwania układu. W tej metodzie obraca się przestrzeń, tak aby jedna oś była wyrównana do grzbietu funkcji straty a pozostałe osie są do niej ortogonalne. Metoda ta jest zalecana gdy wszystkie inne zawiodą.

Jak to się robi w STATISTICA Przy pisaniu wzorów funkcji możemy wykorzystywać różne symbole matematyczne np. · Arytmetyczne (*, +, -, /, ^) · Logiczne (and, or, not) · Relacyjne (<, <=, >, >=, <>, =) · Funkcje matematyczne (exp, log, sqrt, …. . )

Jak to się robi w EXCELU
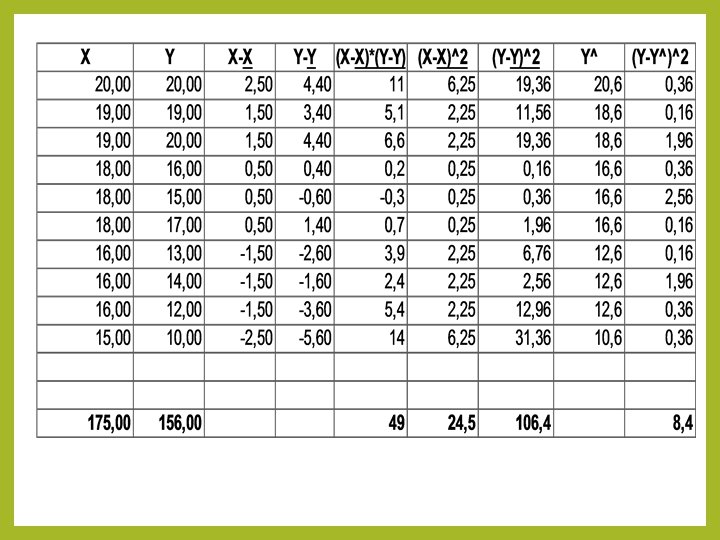

Jak to się robi w EXCELU Obliczenia można przeprowadzić wykorzystując wpisywanie w odpowiednie komórki wzory lub wykorzystując funkcje statystyczne

Jak to się robi w EXCELU Dla współczynnika Spearmana
")
Jak to się robi w EXCELU Badania dla cech jakościowych ( tablica kontyngencyjna)
")
Jak to się robi w EXCELU Badania dla cech jakościowych (wyliczanie eij)
")
Jak to się robi w EXCELU Badania dla cech jakościowych (wyliczanie chi-kwadrat)
")
Jak to się robi w EXCELU Badania dla cech jakościowych (wyliczanie współczynnika C- Pearsona)

Jak to się robi w EXCELU Współczynnik korelacji wielorakiej
- Slides: 164