K means and K means Parallel Jun Wang




")









 iterations • Each iteration there suppose to")











 0. 35 0. 3 0. 25 0. 2 0. 15")











- Slides: 39
K means ++ and K means Parallel Jun Wang
Review of K means • Simple and fast • Choose k centers randomly • Class points to its nearest center • Update centers
K means ++ • Actually you are using it • Spend some time on choosing k centers(seeding) • Save time on clustering
K means ++ algorithm • Seeding • Choose a center from X randomly • For k-1 times • Sample one center each time from X with probability p • Update center matrix • Clustering
di 2=min(euclidean distance b/t Xi to each Ci )
How to choose K centers
Choose a point from X randomly
Calculate all di 2
Calculate Pi • D=d 12+d 22+d 32+…+dn 2 • Pi=di 2 / D • ∑Pi=1 • Points further away from red point have better chance to be chosen
Pick up point with probability p
Keep doing the following: • Update center matrix • Calculate di 2 • Calculate pi Until k centers are found
K means || algorithm • Seeding • Choose a small subset C from X • Assign weight to points in C • Cluster C and get k centers • Clustering
Choose subset C from X • Let D=Sum of square distance=d 12+d 22+d 32+…+dn 2 • Let L be f(k) like 0. 2 k or 1. 5 k • for ln(D) times • Pick up each point in X using Bernoulli distribution • P(chosen)=L*di 2/D • Update the C
How many data in C?
How many data in C? • Ln(D) iterations • Each iteration there suppose to be 1*P 1+1*P 2+…+1*Pn =L points • Total Ln(D)*L points
Cluster the subset C • Red points are in subset C
Cluster the sample C • Calculate distances between point A to other points in C, and find the smallest distance • In this case , d_c 1
Cluster the sample C • Calculate distances between point A and all points in X, and get d_xi
Cluster the sample C • Compare d_xi to d_c 1, and let WA=number of d_xi<d_c 1 • Then we get weight matrix, W • Cluster W into k clusters, get k centers
Difference among three methods K means seeding clustering K means ++ K means || choose k centers Choose subset C randomly proportionally and get k centers from C
Hypothesis K means seeding clustering K means ++ K means || choose k centers Choose subset C randomly proportionally and get k fast slow centers from C slower
Hypothesis K means seeding clustering K means ++ K means || choose k centers Choose subset C randomly proportionally and get k fast slow centers from C slower slow faster
Test Hypothesis • Toy data one – very small • Cloud data – small • Spam data – moderate • Toy data two – very large
Simple data set • N=100; • d=2; • k=2; • Iteration=100
Executive time 0. 4 0. 364668 0. 35 0. 3 0. 25 0. 2 0. 15 0. 1 0. 067244 0. 076458 0. 05 0 K means ++ K means ||
Cloud data • consists of 1024 points in 10 dimension • k=6
Executive time (in seconds) 0. 35 0. 3 0. 25 0. 2 0. 15 0. 1 0. 05 0 K means ++ K means ||
Total scatter 2. 50 E+06 2. 00 E+06 1. 50 E+06 1. 00 E+06 5. 00 E+05 0. 00 E+00 K means ++ K means ||
Spam base data • represents features available to an e-mail spam detection system • consists of 4601 points in 58 dimensions • K=10
Executive time 3. 5 3 2. 5 2 1. 5 1 0. 5 0 K means++ K means ||
Total scatter 4. 50 E+07 4. 00 E+07 3. 50 E+07 3. 00 E+07 2. 50 E+07 2. 00 E+07 1. 50 E+07 1. 00 E+07 5. 00 E+06 0. 00 E+00 K means ++ K means ||
Complicate data set • N=20, 000 • d=40 • K=40
Executive time 800 700 600 500 400 300 200 100 0 K means++ K means||
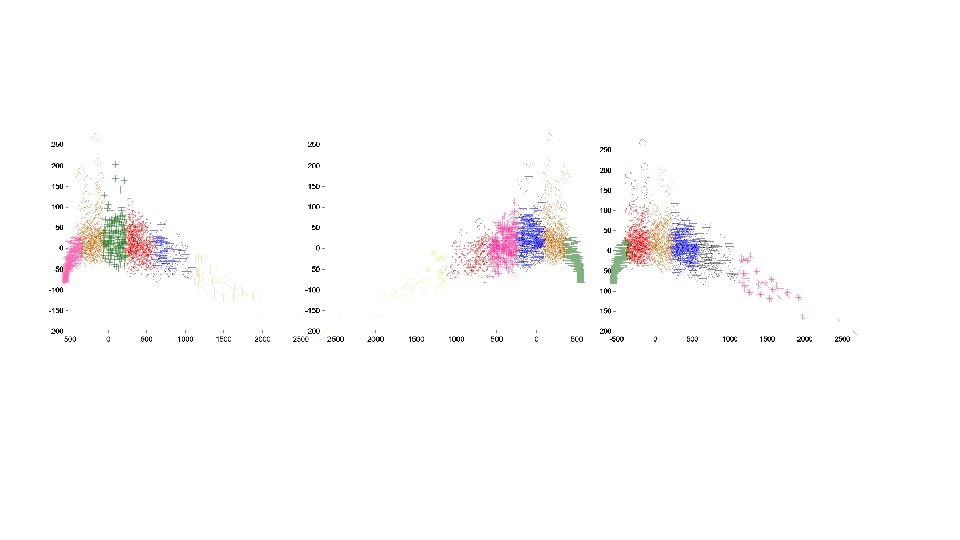
Clustered figure with true label
Clustered figure with computed label
summary K means ++ K means || Small size data Fast Very fast Slow Moderate size Large size data Slow Very slow Fast
Select L • Does not matter much when data is small • Try on large data set 100 80 60 40 20 0 L=0. 2 k L=1. 5 K L=2 k
Questions