JARINGAN SYARAF TIRUAN ARTIFICIAL NEURAL NETWORK Jaringan Syaraf

 atau Artificial Neural Network (ANN) adalah suatu")

 Menirukan model otak manusia Otak Manusia JST Soma Node Dendrites")




 Hardlimit function a = 1 Jika n ≥")
 Sigmoid")


: JST training yang sederhana dipakaikan prosedur algoritma training yang pertama")



")



 e(k) = a(k) – t(k) , k = iterasi")

 = t(k) – a(k) t(k) =")



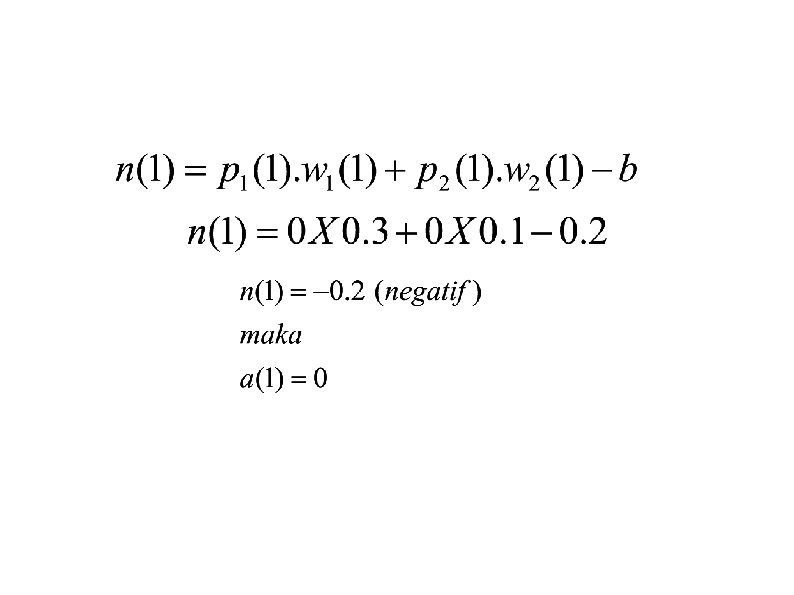
 = t(k) – a(k) e(1) =")
= 0. 3 w 2(2)=0. 1, p 1(2)=0, p 2(2)=1 target(2)=Fd(2)=1")
= target(2) – a(2) = 1 – 0 =1 (ada")

- Slides: 31
JARINGAN SYARAF TIRUAN ARTIFICIAL NEURAL NETWORK
Jaringan Syaraf Tiruan Jaringan syaraf tiruan (JST) atau Artificial Neural Network (ANN) adalah suatu model matematik atau komputasi untuk mensimulasikan struktur dan fungsi dari jaringan syaraf dalam otak. Terdiri dari: Node atau unit pemroses (penjumlah dan fungsi aktivasi) weight/ bobot yang dapat diatur Masukan dan Keluaran Sifat : Adatif Mampu belajar Nonlinear
Biological Neural Network
Jaringan Syaraf Tiruan (JST) Menirukan model otak manusia Otak Manusia JST Soma Node Dendrites Input/Masukan Axon Output/Keluaran Synapsis Weight/ Bobot Milyaran Neuron Ratusan Neuron
Model Neuron Tanpa bias Masukan /Inputs p 1 w 1 p 2 w 2. Penjumlahan n=Σpi. wi Σ . . pi Fungsi Aktifasi wi Bobot/Weight = bisa diatur F(y) a=f(n)
Model Neuron dengan bias Masukan /Inputs p 1 w 1 p 2 w 2. Penjumlahan Σ Fungsi Aktivasi n=Σpi. wi F(y) . . pi wi b (Bias)=Fix Bobot/Weight = bisa diatur a=f(n)
Neuron Sederhana
Model Matematis X=input/masukan i= banyaknya input W=bobot/weight Keluaran Penjumlah -> n = Σpi. wi (Jumlah semua Input(pi) dikali bobot (wi) Output/Keluaran Neuron= a = f(n) f=fungsi aktivasi
Fungsi Aktivasi Beberapa fungsi aktivasi a=f(n) Hardlimit function a = 1 Jika n ≥ 0 0 Jika n < 0 Linear Function a = n Sigmoid Function a = 1 /( 1+ e-n )
Grafik Fungsi Aktivasi Hardlimiter Purelinear a=f(n) Sigmoid
Kegunaan Aktivasi Untuk pengambilan keputusan biasanya digunakan Hardlimit Untuk pengenalan pola/jaringan back propagation biasanya digunakan sigmoid Untuk prediksi/aproksimasi linear biasanya digunakan linear
Model Mc. Culloch and Pitts Neuron menghitung jumlah bobot dari setiap sinyal input dan membandingkan hasilnya dengan nilai bias/threshold, b. Jika input bersih kurang dari threshold, output neuron adalah -1. Tetapi, jika input bersih lebih besar dari atau sama dengan threshold, neuron diaktifkan dan outputnya ditetapkan +1 (Mc. Culloch and Pitts, 1943). Fungsi aktivasi ini disebut Fungsi Tanda (Sign Function). Sehingga output aktual dari neuron dapat ditunjukkan dengan:
Perceptron Perceptron (Rosenblatt, 1958): JST training yang sederhana dipakaikan prosedur algoritma training yang pertama kali. Terdiri dari neuron tunggal dengan bobot synaptic yang diatur dan hard limiter. Operasinya didasarkan pada model neuron Mc. Culloch dan Pitts. Jumlah input yang telah diboboti dipakaikan kepada hard limiter: menghasilkan output +1 jika input positif dan -1 jika negatif mengklasifikasikan output ke dalam dua area A 1 dan A 2.
Proses Belajar Target = Nilai yang diinginkan, Output = Nilai yang keluar dari neuron Proses Compare (membandingkan) antara output dengan target, Jika terjadi perbedaan maka weight/bobot di adjust/atur sampai nilai ouput= (mendekati) nilai target
Proses Belajar Target Masukan p 1 w 1 p 2 w 2. . . pi Keluaran wi n=Σpi. wi Σ a=f(n) F(y) - + b Error=target-a Error digunakan untuk pembelajaran /mengatur bobot
Analog Target apa yang anda inginkan Input/masukan Kekurangan dan kelebihan/potensi anda Bobot seberapa besar usaha anda Output hasil dari potensi and kelemahan dikalikan dengan usaha terhadap potensi or kelemahan Error Kesalahan/Introspeksi diri perkuat potensi or/and lemahkan kekurangan
Proses Belajar n=p 1. w 1 Masukan p 1 w 1 Bobot Σ F(y) a=f(n)
Proses Belajar jika masukan positif Untuk masukan positif penambahan bobot menyebabkan peningkatan keluaran Target Masukan p 1 (2) n=p 1. w 1 (3) w 1 Σ (10) (6) Keluaran a=f(n) F(y) - + F=linear Karena e ≥ 0 maka keluaran a e=10 -6=4 (+) hrs dinaikan untuk menaikan a maka naikan nilai w 1 karena Error=target-a masukan positif w 1 next= w 1 old + delta w 1
Proses Belajar jika masukan negatif Untuk masukan negatif penambahan bobot menyebabkan penurunan keluaran Target Masukan p 1 (-2) n=p 1. w 1 (3) w 1 Σ (10) (-6) Keluaran a=f(n) F(y) - + F=linear Karena e ≥ 0 maka keluaran a e=10 -(-6)=16 (+) hrs dinaikan untuk menaikan a maka turunkan nilai w 1 Error=target-a karena masukan negatif w 1 next= w 1 old + (- delta w 1)
Proses Perceptron Belajar Pada awalnya bobot dibuat kecil untuk menjaga jangan sampai terjadi perbedaan yang sangat besar dengan target. Bobot awal adalah dibuat random, umumnya dalam interval [-0. 5 – 0. 5] Keluaran adalah proses jumlah perkalian antara masukan dengan bobot. Jika terjadi perbedaan antara keluaran dengan target, e(k) = a(k) – t(k), k = iterasi ke- 1, 2, 3, maka: Bobot diupdate/diatur sedikit demi sedikit untuk mendapatkan keluaran yang sesuai dengan target
Perceptron Learning Rule (Rosenblatt, 1960) e(k) = a(k) – t(k) , k = iterasi ke- 1, 2, 3, …. . a(k) = keluaran neuron t(k) = target yang diinginkan e(k) = error/kesalahan w(k+1) = w(k) + Δw(k) = kec belajar x masukan x error = ŋ x p(k) x e(k) Ŋ = learning rate -> kecepatan belajar (0< ŋ ≤ 1) Ŋ besar belajar cepat tidak stabil Ŋ kecil belajar lambat stabil
Langkah Pembelajaran 1. Langkah pertama : Inisialisasi Awal • Mengatur bobot w 1, w 2, . . . , wn interval [-0. 5 – 0. 5], mengatur bias/threshold b, mengatur kec pembelajaran ŋ, fungsi aktivasi 2. Langkah kedua : Menghitung keluaran • Mengaktifkan perceptron dengan memakai masukan p 1(k), p 2(k), . . . , pi(k) dan target yang dikehendaki t(k). Hitunglah output aktual pada iterasi ke-k = 1 • i adalah jumlah input perceptron dan step adalah fungsi aktivasi
1. Langkah ke tiga : Menghitung error e(k) = t(k) – a(k) t(k) = target, a(t)=keluaran perceptron 1. Langkah ke empat : Mengatur Bobot • • • Mengupdate bobot perceptron wi(k+1) = wi(k) + Δwi(k) w(k+1) bobot baru w(k) bobot yg lalu • Δwi(p) adalah pengkoreksian bobot pada iterasi k, yang dihitung dengan: • Δwi(p) = ŋ x pi(k) x e(k) 2. Langkah ke lima : pengulangan • Naikkan iterasi k dengan 1 (k=k+1), kembalilah ke langkah ke dua dan ulangi proses sampai
Melatih Perceptron: Operasi OR Variabel Input OR x 1 x 2 Fd 0 0 1 1 1 0 1 1
x 1 Fd=target Fungsi OR x 2 p 1 p 2 w 1 w 2 n=Σpi. wi Σ F(y) b a=f(n) Perceptron + error
Contoh Pembelajaran 1. Langkah pertama : Inisialisasi Awal • 2. Mengatur bobot w 1, w 2 interval [-0. 5 – 0. 5], w 1(1)=0. 3 w 2(1)=0. 1, mengatur bias/threshold b=0. 2, mengatur kec pembelajaran ŋ =0. 2, fungsi aktivasi-> step Langkah kedua : Menghitung keluaran • Mengaktifkan perceptron dengan memakai masukan p 1(k), p 2(k) dan target yang dikehendaki t(k). Hitunglah output aktual pada iterasi ke-k = 1
1. Langkah ke tiga : Menghitung error e(k) = t(k) – a(k) e(1) = 0 – 0 = 0 1. Langkah ke empat : Mengatur Bobot • Mengupdate bobot perceptron • wi(k+1) = wi(k) + Δwi(k) • w 1(2) = 0. 3(1) + Δw 1(1) • Δw 1(1) = ŋ x pi(1) x e(1) • • • = 0. 2 x 0 = 0 maka w 1(2) = 0. 3(1) + 0 = 0. 3 (tidak berubah) wi(k+1) = wi(k) + Δwi(k) • w 2(2) = 0. 3(1) + Δw 2(1) • Δw 2(1) = ŋ x pi(1) x e(1) • • = 0. 2 x 0 = 0 maka w 2(2) = 0. 1(1) + 0 = 0. 1 (tidak berubah)
K=2 w 1(2)= 0. 3 w 2(2)=0. 1, p 1(2)=0, p 2(2)=1 target(2)=Fd(2)=1 Hitung keluaran:
• Hitung error e(2)= target(2) – a(2) = 1 – 0 =1 (ada error) • Mengatur Bobot Mengupdate bobot perceptron wi(k+1) = wi(k) + Δwi(k) w 1(3) = 0. 3(2) + Δw 1(2) = ŋ x p 1(1) x e(1) = 0. 2 x 0 x 1 = 0 maka w 1(3) = 0. 3(1) + 0 = 0. 3 (tidak berubah) wi(k+1) = wi(k) + Δwi(k) w 2(3) = 0. 3(2) + Δw 2(2) Δw 2(1) = ŋ x p 2(1) x e(1)
Tugas Perorangan hitung secara manual melatih perseptron untuk fungsi AND, XOR, XNOR Kelompok buat program perceptron