Issues in Measuring Individual Differences in Judgmental Accuracy




 h Models")













 • r is judge ability, assumed to have a normal")




 Biesanz, J. C. (2010). The social accuracy model of interpersonal")
 Biesanz, J. C. (2010). The social accuracy model of interpersonal")




 or a lie")







. –Predicted slope adjusted for")






- Slides: 45
Issues in Measuring Individual Differences in Judgmental Accuracy David A. Kenny University of Connecticut http: //davidakenny. net/doc/Ghent 14. ppt
Who Am I? A social psychologist who studies dyads. Keenly interested in dyadic questions of consensus, reciprocity, and accuracy. I study dyads in which each person is paired with the same set of persons: -- round robin design -- block design
I Also Study… Dyadic designs in which one person is paired with just one partner. -- romantic couples -- supervisor-supervisee One model that I have investigated is the Actor-Partner Interdependence Model. Can be used to study: Effects of individual differences (e. g. , EI) on relational outcomes. Accuracy in interpersonal perception.
Judgmental Accuracy Does the judge know the emotional state, thoughts, intent, or personality of a target?
A Renewed Interest in Individual Differences h Interest in Emotional Intelligence (EQ) h Models that provide a framework for understanding judge moderators h Interest in neurological deficits
Strategies To Measure Individual Differences h. Standardized Scales he. g. , PONS hmeasure the number correct h Random Effects Models: SAM hmodel the judgment hsearch for mediators (biases) (Presuming that all judges evaluate the same targets/items. )
Standardized Scales h. Develop a pool of items h. Pick the “good” items h. Establish reliability as measured by internal consistency
Capitalization on Chance h“Good” items may not be so good in another sample. h. Examples …
Follow-up Alphas Scale Initial Follow-up CARAT . 56 . 46 IPT-30 . 52 . 29 IPT-15 . 38 . 24
Low Reliability of Scales Scale a IICa CARAT . 46 . 028 IPT-30 . 29 . 013 IPT-15 . 24 . 039 PONS . 86 . 021 Eyes . 49 . 026 a. IIC: Inter-item correlation
Maybe an Inter-Item Correlation of. 03 Is Not All that Bad? h. Peabody Picture Vocabulary Test: . 08 h. Beck Depression: . 30 h. Bem M/F Scale: . 19 h. Rosenberg Self-Esteem: . 34 I guess it is bad.
Why So Low? • Bad Ideas • No individual differences • Abandon the traditional psychometric approach • Better Ideas • Multidimensionality • Average item difficulty
No Individual Differences? : NO! h. People perform well above chance. h. Difficult to believe that there is a skill but no individual differences. h. Validity evidence h. Tests correlate in theoretically meaningful ways with antecedents and consequents.
Abandon the Psychometric Approach h. Argument that internal consistency estimates are inappropriate because constructs are multidimensional. h. Other forms of reliability (test-retest) are appropriate. h. However, some sort of internal consistency measure (e. g. , split-half) is still desirable.
Multidimensionality • Tests are often multidimensional. – Different emotions – Different aspects of the target • Channels: auditory vs. visual • Information: face vs. body • Items tapping different dimensions will be weakly correlated which lowers IIC. • In some cases, split-half reliability is more sensible. • Multidimensionality explains some but not all of the low IICs.
Item Difficulty • It turns out that average item difficulty has a dramatic effect on reliability. • Obviously if items are either too difficult or easy, reliability will be poor. • What is the optimal difficulty?
Assume • Two response alternatives. • Allow for guessing • What is the ideal average item difficulty? • 75%? • Simulation model that varies average item difficulty…
CTT vs. IRT • An internal consistency measure is based on Classical Test Theory (CTT) • Since about 1970, in testing CTT has been discarded and Item Response Theory (IRT) has been adopted.
Item Response Theory (IRT) • r is judge ability, assumed to have a normal distribution • d is item difficulty; let f = ln[d/(1 – d)] – A d of 0 implies a judge has a 50/50 chance of being right. • probability that the judge is correct: er-f/(1 + er-f) (e approximately equals 2. 718) • allow for guessing er-f/(1 + er-f) + g[1 − (er-f/(1 + er-f)]
“SD” the variance of r
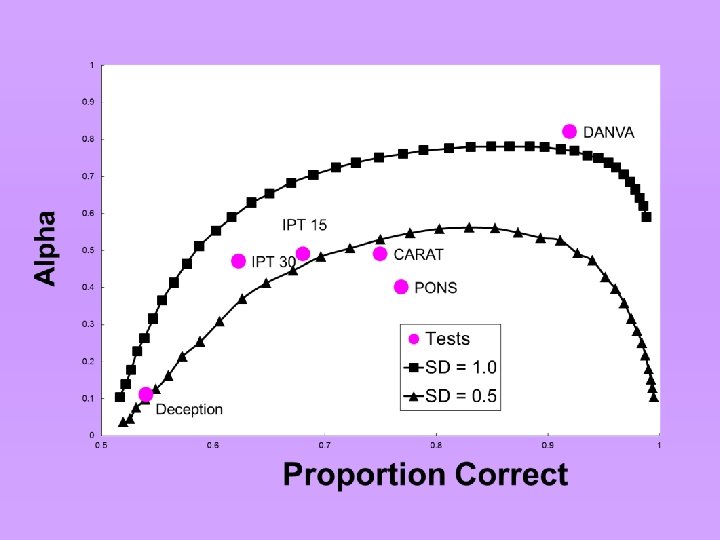
Interpretation • • Curves peak in the high 80 s Predicted by IRT (high. 80 s) Better to design “easy” tests Why? • Performance of low ability judges is almost entirely due to chance. If you want to discriminate low ability judges, you need an easy test.
1 PONS Subtests 0. 9 0. 8 0. 7 Alpha 0. 6 Subtests 0. 5 SD = 0. 33 0. 4 0. 3 0. 2 0. 1 0 0. 5 0. 6 0. 7 0. 8 Proportion Correct 0. 9 1
Modeling Accuracy: Random Effects Model
Social Accuracy Model (SAM) Biesanz, J. C. (2010). The social accuracy model of interpersonal perception: Assessing individual differences in perceptive and expressive accuracy. Multivariate Behavioral Research, 45, 853 -885.
Social Accuracy Model (SAM) Biesanz, J. C. (2010). The social accuracy model of interpersonal perception: Assessing individual differences in perceptive and expressive accuracy. Multivariate Behavioral Research, 45, 853 -885.
The Truth and Bias Model: T&B West, T. V. , & Kenny, D. A. (2001). The truth and bias model of judgment. Psychological Review, 118, 357 -378.
SAM & T&B Models • Theoretical and empirical frameworks designed to address the basic questions of how accuracy and bias operate, and the nature of their interdependence • In studying accuracy, truth (T) becomes a predictor. • Accuracy is a slope or an effect not the outcome or summed score. • Most prior work has not looked at emotion.
Bias • T&B: How strongly judgments are pulled away from the mean level of the truth toward one of the poles of the judgment continuum: For example, perceivers are generally biased to think others are telling the truth. • SAM: Components analogous to Cronbach’s: elevation, differential elevation, and stereotype accuracy.
Example • Christensen 1981 dissertation • 12 targets and 103 judges • Each target tells three stories, two true and one false. • Outcome is dichotomous, the judgment is that the story is true or false.
Variables • Judgment • Is the target telling the truth (1) or a lie (0)? • Truth • Equals 1 if the target is telling the truth • Equals -1 if the target is lying.
SAM Model: Fixed Effects • Intercept: Overall Bias –Do people on average tend to think others are telling the truth? • Truth: Overall Skill –The overall effect of Truth on the judgment of truth telling
SAM Model: Random Effects • Judge: Personal Bias • Truth x Judge: Individual Differences in Judges’ Skill • Target: Demeanor Bias • Truth x Target: Readability or Expressiveness • Judge x Target: Relational Demeanor Bias • Truth x Judge x Target: Relational Skill (black and blue effects may be correlated)
Analysis • R’s rlmer with logit function • Analysis can also be done within SAS, HLM, R, Mplus, or MLwi. N (and likely Stata) • Analysis can take a very long time, especially with Judge x Target as a random variable.
Results: Fixed Effects Effect Estimate Std. Error p Intercept 0. 526 0. 094 <. 001 Truth 0. 364 0. 126. 004 Intercept is a logit. It implies that when Truth = 0, judges think that there is. 629 chance the person is telling the truth. People are “biased” to think targets are telling the truth. Truth is a logit difference or log of an odds ratio. It corresponds to a. 709 chance of being right if someone is telling truth and. 460 chance if telling a lie.
Results: Random Effects No evidence of a Judge x Target variance for either skill or bias effects. Thus, people are not consistently better at judging some people than other people and the bias to think that a person is lying is the same for all judges. Also skill and bias variables are uncorrelated.
Results: Variances of Random Effects Variance Absolute Relative Skill Judge Target 0. 133 0. 156 . 032. 038 Judge Target 0. 496 0. 031 3. 290 . 121. 008. 801 Bias Error
Follow-up Analyses • Traditional –Compute estimates of skill and correlated them with other variables. • Look for mediators and moderators –A Brunswikian analysis
Traditional • Can obtain estimates of skill (called Empirical Bayes). –Predicted slope adjusted for level of knowledge (i. e. , regression towards the mean). • Can correlate these estimates with other variables for validity studies.
Brunswikian Analysis • Look for a cue, e. g. , eye contact in the Christensen study. • See if the cue explains accuracy. • T&B treats a cue as a bias, but a bias can lead to accuracy.
Cue as a Mediator Cue a Truth c' b Judgment
Effects • Terms – a: cue validity – b: cue utilization – ab: achievement (indirect effect) – c’: accuracy not explained by the cue (direct effect) – c = ab + c’: total effect • Individual Differences: a, b (and so ab), and c’ can vary by – Judges – Targets • Thus, there might be moderated mediation.
A Surprising Result • Assume a and b are non-zero and c’ equals zero. Thus, the effect is completely mediated, i. e. , the total effect or c would equal indirect effect or ab. • You would think that the power of the two tests are about the same. • They are not! There can be substantially more power in the test of the indirect effect. The test of c need 75 times the number of cases to have the same power as the test of ab!
Conclusion • Measurement of individual differences in this area is difficult. • It is important to move beyond the measurement of a global score. Need to model the process of judgment by judges of targets. • Obviously there are difficult analysis issues that are not discussed in much detail in this talk.
http: //davidakenny. net/doc/Ghent 14. ppt Thank You!