Introduction to Programming Massively Parallel Graphics processors Introduction







![Sequential Execution Model int a[N]; // N is large for (i =0; i <](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-8.jpg "Sequential Execution Model int a[N]; // N is large for (i =0; i <")
![Data Parallel Execution Model / SIMD int a[N]; // N is large for all](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-9.jpg "Data Parallel Execution Model / SIMD int a[N]; // N is large for all")
![Single Program Multiple Data / SPMD int a[N]; // N is large for all](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-10.jpg "Single Program Multiple Data / SPMD int a[N]; // N is large for all")

 CPU 3 GB/s – 8 GB.")
![Target Applications int a[N]; // N is large for all elements of a compute](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-13.jpg "Target Applications int a[N]; // N is large for all elements of a compute")


















 • Grid of blocks of threads – 1")
 cuda…() cu…()")
 calls and kernel invocations")
 {")
![CUDA API: Example int a[N]; for (i =0; i < N; i++) a[i] =](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-36.jpg "CUDA API: Example int a[N]; for (i =0; i < N; i++) a[i] =")
![1. Allocate CPU Data float *ha; main (int argc, char *argv[]) { int N](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-37.jpg "1. Allocate CPU Data float *ha; main (int argc, char *argv[]) { int N")
 float *ha; int i; for (i = 0; i")
 &da, sizeof (float) *")





 calls – Kernel/requests are queued")

 { int i")

")
![__device__ Example • Add x to a[i] multiple times __device__ float addmany (float a,](https://slidetodoc.com/presentation_image/20caa6e52b76eda8760e43157262c27d/image-50.jpg "__device__ Example • Add x to a[i] multiple times __device__ float addmany (float a,")

 {")




















 Super-lens capable of resolving details down to l/6 Small and broadband antennas")

 converters •")






- Slides: 84
Introduction to Programming Massively Parallel Graphics processors Introduction to CUDA Programming Andreas Moshovos moshovos@eecg. toronto. edu ECE, Univ. of Toronto Summer 2010 Some slides/material from: UIUC course by Wen-Mei Hwu and David Kirk UCSB course by Andrea Di Blas Universitat Jena by Waqar Saleem NVIDIA by Simon Green and others as noted on slides
How to Get High Performance • Computation – Calculations – Data communication/Storage Unlimited Bandwidth Zero/Low Latency Tons of Compute Engines Tons of Storage
Calculation capabilities • How many calculation units can be built? • Today’s silicon chips – About 1 B transistors – 30 K transistors for a 52 b multiplier Tons of Compute Engines ? • ~30 K multipliers – 260 mm^2 area (mid-range) – 112 microns^2 for FP unit (overestimated) • ~2 K FP units • Frequency ~ 3 Ghz common today – TFLOPs possible • Disclaimer: back-on-the-envelop calculations – take with a grain of salt • Can build lots of calculation units (ALUs)
How about Communication/Storage • Need data feed and storage • The larger the slower • Takes time to get there and back – Multiple cycles even on the same die �� � Unlimited Bandwidth Zero/Low Latency Tons of Compute Engines Tons of Slow Storage
Is there enough parallelism? Unlimited Bandwidth Zero/Low Latency Tons of Compute Engines Tons of Storage • Keep this busy? – Needs lots of independent calculations • Parallelism/Concurrency • Much of what we do is sequential – First do 1, then do 2, then if X do 3 else do 4
Today’s High-End General Purpose Processors Slower Cache Faster cache time • Localize Communication and Computation • Try to automatically extract parallelism Tons of Slow Storage Automatically extract instruction level parallelism Large on-die caches to tolerate off-chip memory latency
Some things are naturally parallel
Sequential Execution Model int a[N]; // N is large for (i =0; i < N; i++) time a[i] = a[i] * fade; Flow of control / Thread One instruction at the time Optimizations possible at the machine level
Data Parallel Execution Model / SIMD int a[N]; // N is large for all elements do in parallel time a[index] = a[index] * fade; This has been tried before: ILLIAC III, UIUC, 1966
Single Program Multiple Data / SPMD int a[N]; // N is large for all elements do in parallel time if (a[i] > threshold) a[i]*= fade; The model used in today’s Graphics Processors
CPU vs. GPU overview • CPU: – Handles sequential code well – Can’t take advantage of massively parallel code – Off-chip bandwidth lower – Peak Computation capability lower • GPU: – Requires massively parallel computation – Handles some control flow – Higher off-chip bandwidth – Higher peak computation capability
Programmer’s view • GPU as a co-processor (2008) CPU 3 GB/s – 8 GB. s GPU 141 GB/sec 6. 4 GB/sec – 31. 92 GB/sec 8 B per transfer Memory GPU Memory 1 GB on our systems
Target Applications int a[N]; // N is large for all elements of a compute a[i] = a[i] * fade • Lots of independent computations – CUDA threads need not be independent
Programmer’s View of the GPU • GPU: a compute device that: – Is a coprocessor to the CPU or host – Has its own DRAM (device memory) – Runs many threads in parallel • Data-parallel portions of an application are executed on the device as kernels which run in parallel on many threads
Why are threads useful? Parallelism • Concurrency: – Do multiple things in parallel Needs more functional units – Uses more hardware Gets higher performance
Why are threads useful #2 – Tolerating stalls • Often a thread stalls, e. g. , memory access Multiplex the same functional unit Get more performance at a fraction of the cost
GPU vs. CPU Threads • GPU threads are extremely lightweight • Very little creation overhead • In the order of microseconds • All done in hardware • GPU needs 1000 s of threads for full efficiency • Multi-core CPU needs only a few
Execution Timeline CPU / Host 1. Copy to GPU mem 2. Launch GPU Kernel time 2’. Synchronize with GPU 3. Copy from GPU mem GPU / Device
Programmer’s view • First create data on CPU memory CPU Memory GPU Memory
Programmer’s view • Then Copy to GPU CPU Memory GPU Memory
Programmer’s view • GPU starts computation runs a kernel • CPU can also continue CPU Memory GPU Memory
Programmer’s view • CPU and GPU Synchronize CPU Memory GPU Memory
Programmer’s view • Copy results back to CPU Memory GPU Memory
Computation partitioning: • At the highest level: – Think of computation as a series of loops: • for (i = 0; i < big_number; i++) – a[i] = some function • for (i = 0; i < big_number; i++) – a[i] = some other function Kernels
Computation Partitioning -- Kernel • CUDA exposes the hardware to the programmer • Programmer must manually partition work appropriately • Programmers view is hierarchical: – Think of data as an array
Per Kernel Computation Partitioning • Computation Grid: 2 D Case thread Block • Threads within a block can communicate/synchronize – Run on the same multiprocessor • Threads across blocks can’t communicate – Shouldn’t touch each others data – Behavior undefined
Thread Coordination Overview • Race-free access to data
GBT: Grids of Blocks of Threads Programmers view of data and computation partitioning Why? Realities of integrated circuits: need to cluster computation and storage to achieve high speeds
Block and Thread IDs • Threads and blocks have IDs – So each thread can decide what data to work on – Block ID: 1 D or 2 D – Thread ID: 1 D, 2 D, or 3 D • Simplifies memory addressing when processing multidimensional data – Convenience not necessity Device Grid 1 Block (0, 0) Block (1, 0) Block (2, 0) Block (0, 1) Block (1, 1) Block (2, 1) Block (1, 1) Thread Thread (0, 0) (1, 0) (2, 0) (3, 0) (4, 0) Thread Thread (0, 1) (1, 1) (2, 1) (3, 1) (4, 1) Thread Thread (0, 2) (1, 2) (2, 2) (3, 2) (4, 2) • IDs and dimensions are accessible through predefined “variables”, e. g. , block. Dim. x and thread. Idx. x
Execution Model: Ordering • Execution order is undefined • Do not assume and use: • block 0 executes before block 1 • Thread 10 executes before thread 20 • And any other ordering even if you can observe it – Future implementations may break this ordering – It’s not part of the CUDA definition – Why? More flexible hardware options
Programmer’s view: Memory Model • Different memories with different uses and performance – Some managed by the compiler – Some must be managed by the programmer Arrows show whether read and/or write is possible
Execution Model Summary (for your reference) • Grid of blocks of threads – 1 D/2 D grid of blocks – 1 D/2 D/3 D blocks of threads • All blocks are identical: – same structure and # of threads • Block execution order is undefined • Same block threads: – can synchronize and share data fast (shared memory) • Threads from different blocks: – Cannot cooperate – Communication through global memory • Threads and Blocks have IDs – Simplifies data indexing – Can be 1 D, 2 D, or 3 D (threads) • Blocks do not migrate: execute on the same processor • Several blocks may run over the same processor
CUDA Software Architecture e. g. , fft() cuda…() cu…()
Reasoning about CUDA call ordering • GPU communication via cuda…() calls and kernel invocations – cuda. Malloc, cuda. Mem. Cpy • Asynchronous from the CPU’s perspective – CPU places a request in a “CUDA” queue – requests are handled in-order • Streams allow for multiple queues – Order within each queue honored – No order across queues – More on this much later on
My first CUDA Program __global__ void arradd (float *a, float f, int N) { int i = block. Idx. x * block. Dim. x + thread. Idx. x; if (i < N) a[i] = a[i] + float; } GPU int main() { float h_a[N]; float *d_a; cuda. Malloc ((void **) &a_d, SIZE); CPU cuda. Thread. Synchronize (); cuda. Memcpy (d_a, h_a, SIZE, cuda. Memcpy. Host. To. Device)); arradd <<< n_blocks, block_size >>> (d_a, 10. 0, N); cuda. Thread. Synchronize (); cuda. Memcpy (h_a, d_a, SIZE, cuda. Memcpy. Device. To. Host)); CUDA_SAFE_CALL (cuda. Free (a_d)); }
CUDA API: Example int a[N]; for (i =0; i < N; i++) a[i] = a[i] + x; 1. 2. 3. 4. 5. 6. 7. 8. 9. Allocate CPU Data Structure Initialize Data on CPU Allocate GPU Data Structure Copy Data from CPU to GPU Define Execution Configuration Run Kernel CPU synchronizes with GPU Copy Data from GPU to CPU De-allocate GPU and CPU memory
1. Allocate CPU Data float *ha; main (int argc, char *argv[]) { int N = atoi (argv[1]); ha = (float *) malloc (sizeof (float) * N); . . . } No memory allocated on the GPU side • • Pinned memory allocation results in faster CPU to/from GPU copies But pinned memory cannot be paged-out More on this later cuda. Malloc. Host (…)
2. Initialize CPU Data (dummy) float *ha; int i; for (i = 0; i < N; i++) ha[i] = i;
3. Allocate GPU Data float *da; cuda. Malloc ((void **) &da, sizeof (float) * N); • Notice: no assignment side – NOT: da = cuda. Malloc (…) • Assignment is done internally: – That’s why we pass &da • Space is allocated in Global Memory on the GPU
GPU Memory Allocation • The host manages GPU memory allocation: – cuda. Malloc (void **ptr, size_t nbytes) – Must explicitly cast to (void **) • cuda. Malloc ((void **) &da, sizeof (float) * N); – cuda. Free (void *ptr); • cuda. Free (da); – cuda. Memset (void *ptr, int value, size_t nbytes); • cuda. Memset (da, 0, N * sizeof (int)); • Check the CUDA Reference Manual
4. Copy Initialized CPU data to GPU float *da; float *ha; cuda. Mem. Cpy ((void *) da, // DESTINATION (void *) ha, // SOURCE sizeof (float) * N, // #bytes cuda. Memcpy. Host. To. Device); // DIRECTION
Host/Device Data Transfers • The host initiates all transfers: • cuda. Memcpy( void *dst, void *src, size_t nbytes, enum cuda. Memcpy. Kind direction) • Asynchronous from the CPU’s perspective – CPU thread continues • In-order processing with other CUDA requests • enum cuda. Memcpy. Kind – cuda. Memcpy. Host. To. Device – cuda. Memcpy. Device. To. Host – cuda. Memcpy. Device. To. Device
5. Define Execution Configuration • How many blocks and threads/block int threads_block = 64; int blocks = N / threads_block; if (blocks % N != 0) blocks += 1; • Alternatively: blocks = (N + threads_block – 1) / threads_block;
6. Launch Kernel & 7. CPU/GPU Synchronization • Instructs the GPU to launch blocks x threads_block threads: darradd <<<blocks, threads_block>> (da, 10 f, N); cuda. Thread. Synchronize (); // forces CPU to wait • darradd: kernel name • <<<…>>> execution configuration – More on this soon • (da, x, N): arguments – 256 – 8 byte limit / No variable arguments
CPU/GPU Synchronization • CPU does not block on cuda…() calls – Kernel/requests are queued and processed in-order – Control returns to CPU immediately • Good if there is other work to be done – e. g. , preparing for the next kernel invocation • Eventually, CPU must know when GPU is done • Then it can safely copy the GPU results • cuda. Thread. Synchronize () – Block CPU until all preceding cuda…() and kernel requests have completed
8. Copy data from GPU to CPU & 9. De. Allocate Memory float *da; float *ha; cuda. Mem. Cpy ((void *) ha, // DESTINATION (void *) da, // SOURCE sizeof (float) * N, // #bytes cuda. Memcpy. Device. To. Host); // DIRECTION cuda. Free (da); // display or process results here free (ha);
The GPU Kernel __global__ darradd (float *da, float x, int N) { int i = block. Idx. x * block. Dim. x + thread. Idx. x; if (i < N) da[i] = da[i] + x; } • Block. Idx: Unique Block ID. – Numerically asceding: 0, 1, … • Block. Dim: Dimensions of Block = how many threads it has – Block. Dim. x, Block. Dim. y, Block. Dim. z – Unused dimensions default to 0 • Thread. Idx: Unique per Block Index – 0, 1, … – Per Block
Array Index Calculation Example int i = block. Idx. x * block. Dim. x + thread. Idx. x; i = 127 x 0 Id x. 3 th th re x. Id ad re ad x 6 x 0 ad th re th i = 64 Id x. Id ad ad re th i = 63 a[191]a[192] x. x 6 x 0 Id x. Id ad re th a[127]a[128] x. x 0 x. Id ad re th i = 0 block. Idx. x = 2 3 a[63] a[64] x 63 a[0] block. Idx. x = 1 re block. Idx. x = 0 i = 128 Assuming block. Dim. x = 64 i = 191 i = 192
CUDA Function Declarations Executed Only callable on the: from the: __device__ float Device. Func() device __global__ void device host __host__ Kernel. Func() float Host. Func() • __global__ defines a kernel function – Must return void – Can only call __device__ functions • __device__ and __host__ can be used together – Two difference versions generated
__device__ Example • Add x to a[i] multiple times __device__ float addmany (float a, float b, int count) { while (count--) a += b; return a; } __global__ darradd (float *da, float x, int N) { int i = block. Idx. x * block. Dim. x + thread. Idx. x; if (i < N) da[i] = addmany (da[i], x, 10); }
Kernel and Device Function Restrictions • __device__ functions cannot have their address taken – e. g. , f = &addmany; *f(…); • For functions executed on the device: – No recursion • darradd (…) { darradd (…) } – No static variable declarations inside the function • darradd (…) { static int canthavethis; } – No variable number of arguments • e. g. , something like printf (…)
My first CUDA Program __global__ void arradd (float *a, float f, int N) { int i = block. Idx. x * block. Dim. x + thread. Idx. x; if (i < N) a[i] = a[i] + float; } GPU int main() { float h_a[N]; float *d_a; cuda. Malloc ((void **) &a_d, SIZE); CPU cuda. Thread. Synchronize (); cuda. Memcpy (d_a, h_a, SIZE, cuda. Memcpy. Host. To. Device)); arradd <<< n_blocks, block_size >>> (d_a, 10. 0, N); cuda. Thread. Synchronize (); cuda. Memcpy (h_a, d_a, SIZE, cuda. Memcpy. Device. To. Host)); CUDA_SAFE_CALL (cuda. Free (a_d)); }
How to get high-performance #1 • Programmer managed Scratchpad memory – Bring data in from global memory – Reuse – 16 KB/banked – Accessed in parallel by 16 threads • Programmer needs to: – Decide what to bring and when – Decide which thread accesses what and when – Coordination paramount
How to get high-performance #2 • Global memory accesses – 32 threads access memory together – Can coalesce into a single reference – E. g. , a[thread. ID] works well • Control flow – 32 threads run together – If they diverge there is a performance penalty • Texture cache – When you think there is locality
Are GPUs really that much faster than CPUs • 50 x – 200 x speedups typically reported • Recent work found – Not enough effort goes into optimizing code for CPUs • But: – The learning curve and expertise needed for CPUs is much larger
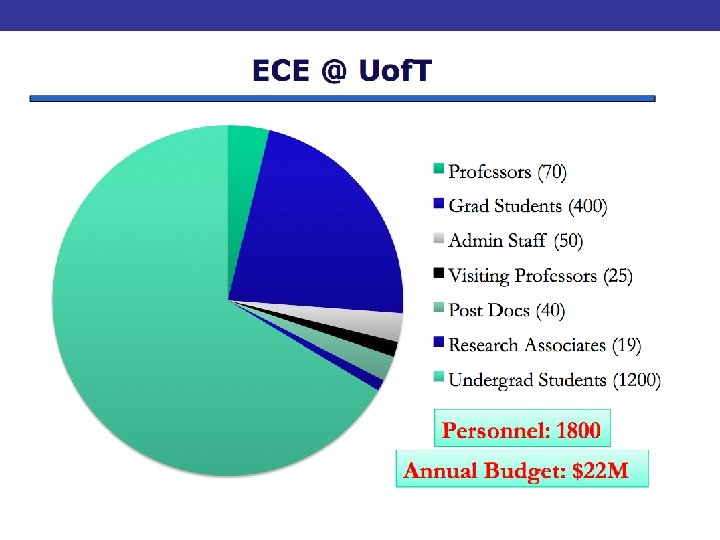
ECE Overview - ECE research Profile - Personnel and budget Partnerships with industry • Our areas of expertise - Biomedical Engineering Communications Computer Engineering Electromagnetics Electronics Energy Systems Photonics Systems Control - Slides from F. Najm (Chair) and T. Sargent (Research Vice Chair)
About our group • Computer Architecture – How to build the best possible system – Best: performance, power, cost, etc. • Expertise in high-end systems – Micro-architecture – Multi-processor and Multi-core systems • Current Research Support: – AMD, IBM, NSERC, Qualcomm (planned) • Claims to fame – Memory Dependence Prediction • Commercially implemented and licensed – Snoop Filtering: IBM Blue Gene
Uof. T-DRDC Partnership
Examples of industry research contracts with ECE in the past 8 years AMD Agile Systems Inc Altera ARISE Technologies Asahi Kasei Microsystems Bell Canada Bell Mobility Cellular Bioscrypt Inc Broadcom Corporation Ciclon Semiconductor Cybermation Inc Digital Predictive Systems Inc. DPL Science Eastman Kodak Electro Scientific Industries EMS Technologies Exar Corp FOX-TEK Firan Technology Group Fuji Electric Fujitsu Gennum H 2 Green Energy Corporation Honeywell ASCa, Inc. Hydro One Networks Inc. IBM Canada Ltd. IBM IMAX Corporation Intel Corporation Jazz Semiconductor KT Micro LG Electronics Maxim MPB Technologies Microsoft Motorola Northrop Grumman NXP Semiconductors ON Semiconductor Ontario Lottery and Gaming Corp Ontario Power Generation Inc. Panasonic Semiconductor Singapore Peraso Technologies Inc. Philips Electronics North America Redline Communications Inc. Research in Motion Ltd. Right Track CAD Robert Bosch Corporation Samsung Thales Co. , Ltd Semiconductor Research Corporation Siemens Aktiengesellschaft Sipex Corporation STMicroelectronics Inc. Sun Microsystems of Canada Inc. Telus Mobility Texas Instruments Toronto Hydro-Electric System Toshiba Corporation Xilinx Inc. 62
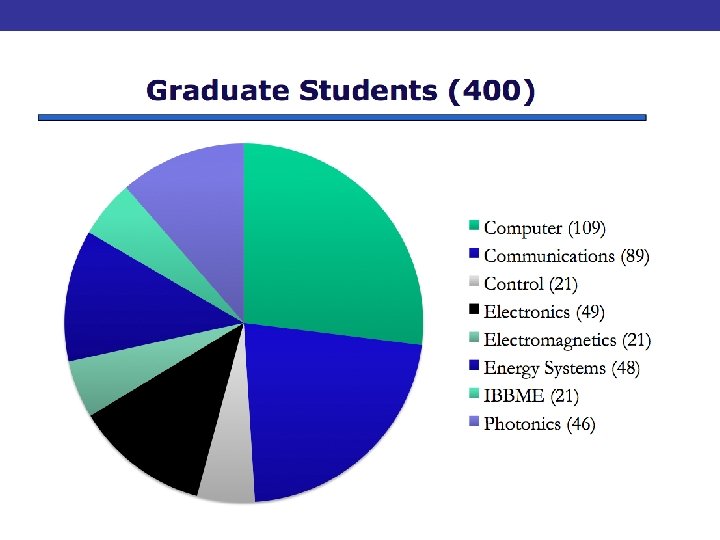
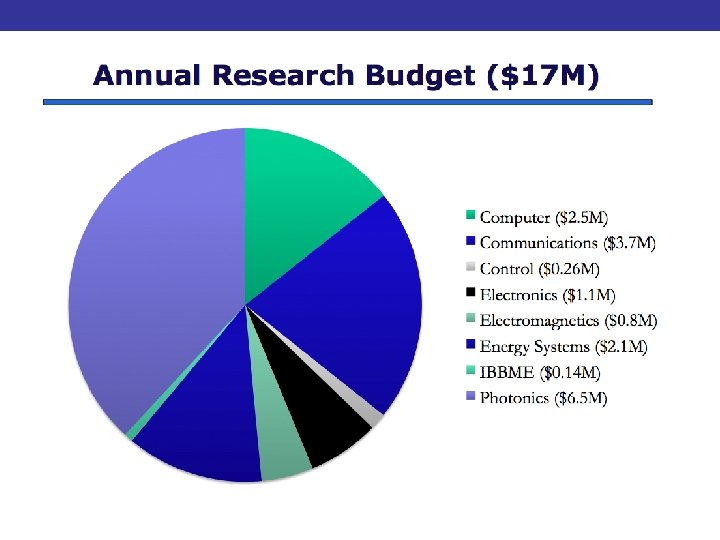
Eight Research Groups 1. Biomedical Engineering 2. Communications 3. Computer Engineering 4. Electromagnetic s 5. Electronics 6. Energy Systems 7. Photonics 8. Systems Control 63 ECE
Computer Engineering Group • Human-Computer Interaction – Willy Wong, Steve Mann • Multi-sensor information systems – Parham Aarabi • Computer Hardware – Jonathan Rose, Steve Brown, Paul Chow, Jason Anderson • Computer Architecture – Greg Steffan, Andreas Moshovos, Tarek Abdelrahman, Natalie Enright Jerger • Computer Security – Davie Lie, Ashvin Goel
Biomedical Engineering • Neurosystems – Berj L. Bardakjian, Roman Genov. – Willy Wong, Hans Kunov – Moshe Eizenman • Rehabilitation – Milos Popovic, Tom Chau. • Medical Imaging – Michael Joy, Adrian Nachman. – Richard Cobbold – Ofer Levi • Proteomics – Brendan Frey. – Kevin Truong. Ca 2+ 65
Communications Group • Study of the principles, mathematics and algorithms that underpin how information is encoded, exchanged and processed • Three Sub-Groups: 1. Networks 2. Signal Processing 3. Information Theory
Sequence Analysis
Image Analysis and Computer Vision Pattern recognition and detection Embedded computer vision Computer vision and graphics
Networks
Quantum Cryptography and Computing
Computer Engineering • System Software – Michael Stumm, H-A. Jacobsen, Cristiana Amza, Baochun Li • Computer-Aided Design of Circuits – Farid Najm, Andreas Veneris, Jianwen Zhu, Jonathan Rose
Electronics Group n n 14 active professors; largest electronics group in Canada. Breadth of research topics: l l l l n Electronic device modelling Semiconductor technology VLSI CAD and Systems FPGAs DSP and Mixed-mode ICs Biomedical microsystems High-speed and mm-wave ICs and So. Cs Lab for (on-wafer) So. C and IC testing through 220 GHz 72 Uof. T-IBM Partnership 72
Intelligent Sensory Microsystems n Mixed-signal VLSI circuits l n On-chip micro-sensors l n Low-power, low-noise signal processing, computing and ADCs Electrical, chemical, optical Project examples l l l Brain-chip interfaces On-chip biochemical sensors CMOS imagers 73
mm-Wave and 100+GHz systems on chip n n Modelling mm-wave and noise performance of active and passive devices past 300 GHz. 60 -120 GHz multi-gigabit data rate phased-array radios Single-chip 76 -79 GHz automotive radar 170 GHz transceiver with on-die antennas 74
Electromagnetics Group • Metamaterials: From microwaves to optics – – • Super-resolving lenses for imaging and sensing Small antennas Multiband RF components CMOS phase shifters Electromagnetics of High-Speed Circuits – Signal integrity in high-speed digital systems • Microwave integrated circuit design, modeling and characterization • Computational Electromagnetics – Interaction of Electromagnetic Fields with Living Tissue • Antennas – – – Telecom and Wireless Systems Reflectarrays Wave electronics Integrated antennas Controlled-beam antennas Adaptive and diversity antennas
METAMATERIALS (MTMs) Super-lens capable of resolving details down to l/6 Small and broadband antennas Scanning antennas with CMOS MTM chips
Computational Electromagnetics Fast CAD for RF/ optical structures Microstrip spiral inductor Modeling of Metamaterials Plasmonic Left-Handed Media Optical power splitter Leaky-Wave Antennas
Energy Systems Group Power Electronics – High power (> 1. 2 MW) converters • modeling, control, and digital control realization – Micro-Power Grids • converters for distributed resources, • dc distribution systems, and HVdc systems – Low-Power Electronics • Integrated power supplies and power management • systems-on-chip for low-power electronics – computers, cell phones, PDA-s, MP 3 players, body implants – Harvesting Energy from humans 78
79 Energy Systems Research Matrix Converter for Micro-Turbine Generator Uof. T IC for cell phone power supplies Voltage Control System for Wind Power Generators
Photonics Group
Photonics Group
Photonics Group
Photonics Group: Bio-Photonics
Systems Control Group • Basic & applied research in control engineering • World-leading group in Control theory ____________________ • Optical Signal-to-Noise Ratio opt. with game theory • Erbium-doped fibre amplifier design • Analysis and design of digital watermarks for authentication • Nonlinear control theory – application to magnetic levitation, micro positioning system