INTRODUCTION TO HIGH PERFORMANCE COMPUTING AND TERMINOLOGY INTRODUCTION

 § “most advanced, powerful, and")


 that function in some way as a single")







 § In distributed memory programming, the typical way of communicating")





- Slides: 19
INTRODUCTION TO HIGH PERFORMANCE COMPUTING AND TERMINOLOGY
INTRODUCTION § Extreme Science and Engineering Discovery Environment (XSEDE) § “most advanced, powerful, and robust collection of integrated advanced digital resources and services in the world” § Five-year, $121 -million project is supported by the National Science Foundation
HIGH PERFORMANCE COMPUTING § The practice of aggregating computing power in a way that delivers much higher performance than one could get out of a typical desktop computer or workstation in order to solve large problems in science, engineering, or business. Practical applications § Airline ticket purchasing systems § Finance companies calculating recommendations for client portfolios
NODE § Discrete unit of computer system, runs its own instance of OS (Ex. Laptop is one node) § Computing units Cores: can process separate streams of instructions § Number of cores in a node = (number of processing chips) x (number of cores on a chip) § Note: Modern nodes contain processor chips sharing memory, disk
CLUSTER § Collection of machines (nodes) that function in some way as a single resource (e. g. Stampede) § Nodes of cluster are assigned by a “scheduler” § Job: Assignment of nodes for a certain user, certain amount of time
GRID § Software stack facilitating shared resources across networks, institutions; § Deals with heterogeneous clusters § Most grids are cross-institutional groups of clusters, common software, common user authentication
Major grids in the U. S. § OSG: Institutions organize themselves into virtual organizations (VOs) with similar computing interests. They all install OSG software § XSEDE: Similar to OSG, limits usage to dedicated high-performance network
PARALLEL CODE § Single thread of execution, multiple data items simultaneously § Multiple threads of execution in single thread § Multiple executables working on same problem § Any combination of above
TAXONOMY OF PARALLEL COMPUTERS
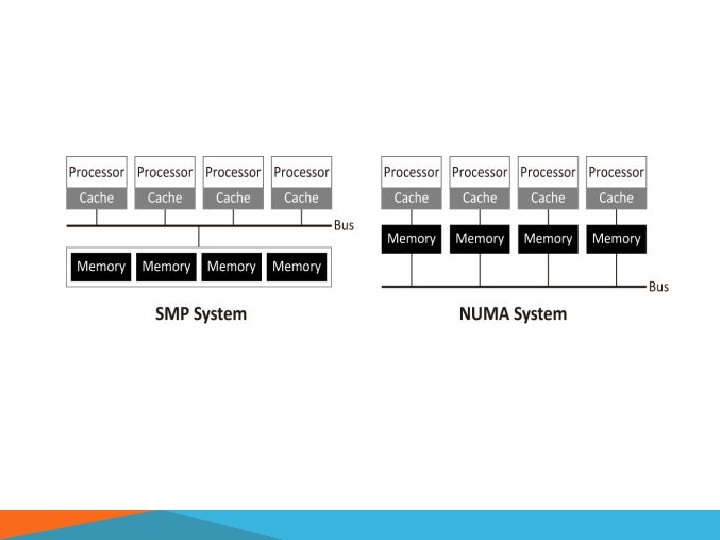
SHARED MEMORY § Multiple cores that have access to the same physical memory. § The cores may be part of multicore processor chips, or they may be on discrete chips § Symmetric multiprocessor (SMP): access to memory locations is equally fast from all cores, or uniform memory access (UMA) § Non-uniform memory access (NUMA): If multiple chips are involved but access is not necessarily uniform § Programs for shared memory computers typically use multiple threads in the same process
DISTRIBUTED MEMORY § In a distributed memory system, the memory is associated with individual processors and a processor is only able to address its own memory. § In a distributed memory program, each task has a different virtual address space. § Programming using distributed arrays is called data parallel programming, because each task is working on a different section of an array of data
DISTRIBUTED MEMORY
MESSAGE PASSING INTERFACE (MPI) § In distributed memory programming, the typical way of communicating between tasks and coordinating their activities is through message passing. § The Message Passing Interface (MPI) is a communication system that was designed with a standard for distributed-memory parallel programming.
MESSAGE-PASSING VS SHARED MEMORY § The message-passing programming model § Is widely used because of its portability § Some applications are too complex to code while trying to balance computation load and avoid redundant computations § The shared-memory programming model § Simplifies coding § Not portable and often provides little control over interprocessor data transfer costs
PERFORMANCE EVALUATION § Parallel efficiency is defined by how effectively you're making use of your multiple processors. § 100% efficiency would mean that you're getting a factor of p speedup from using p processors. § Efficiency is defined in terms of speedup per processor:
PERFECT SPEEDUP
§ Parallel applications tend not to exhibit perfect speedup because: § There are inherently serial parts of a calculation § Parallelization introduces overhead into the calculation to copy and transfer data § The individual tasks compete for resources like memory or disk.
REFERENCES Introduction to Parallel Computing https: //computing. llnl. gov/tutorials/parallel_comp Parallel Programming Concepts and High-Performance Computing https: //www. cac. cornell. edu/VW/Parallel/shared. aspx