Introduction to Data Mining Knowledge Discovery in databases
 Computer Science Department International")
Introduction to Data Mining & Knowledge Discovery in databases (KDD) Computer Science Department International Colleage Burapha University Nuansri Denwattana

Outline 1 Data Mining and Knowledge Discovery in Database : Terms 2 Definition of KDD and Data Mining 3 Mining business database : Applications 4 Data Mining : Database Perspective 5 Mining different kinds of knowledges in databases 6 Conclusion

Data Mining and KDD • Data Mining is sometime known as Knowledge Discovery in Databases (KDD) • KDD is the term mostly used in academic societies • Data Mining is used in business and commercial settings • This is not an agreed upon definition of the terminology • Fayyad et. Al defines Data Mining as a step in the overall Knowledge discovery method
 Nontrivial extraction of implicit • a process of nontrivial")
Knowledge Discovery in Databases (KDD) Nontrivial extraction of implicit • a process of nontrivial extraction of implicit, previously unknown, and potentially useful information from data in databases KDD
 (cont. ) Searching of relationships and global pattern Nontrivial")
Knowledge Discovery in Databases (KDD) (cont. ) Searching of relationships and global pattern Nontrivial extraction of implicit KDD • a process of searching for relationships and global patterns that exist in large databases but are “hidden” among the vast amounts of data
 (cont. ) Searching of relationships and global pattern Nontrivial")
Knowledge Discovery in Databases (KDD) (cont. ) Searching of relationships and global pattern Nontrivial extraction of implicit Discovering useful knowledge from data KDD • The term “KDD” is used to refer to the overall process of discovering useful knowledge from data

Why do we need KDD? • Raw data is rarely of direct benefit – analysis was strictly a manual process – it can help by statistical techniques to provide summaries and generate report • The amount of data is growing so fast – the manual analysis cannot handle • We are drowning in data but starving for knowledge

Mining Large Data Sets - Motivation • There is often information “hidden” in the data that is not readily evident • Human analysts may take weeks to discover useful information • Much of the data is never analyzed at all The Data Gap Total new disk (TB) since 1995 Number of analysts From: R. Grossman, C. Kamath, V. Kumar, “Data Mining for Scientific and Engineering Applications”

Where does KDD come from ? Researchers interested in the problem of automating data analysis has grown under the label knowledge discovery in databases (KDD( KDD workshop The First KDD workshop was held in 1989 , it has involved into an annual international conference: KDD 2002 Occur attention Areas of interested Statistics, pattern recognition, AI, and machine learning

Origins of Data Mining • Draws ideas from machine learning/AI, pattern recognition, statistics, and database systems • Traditional Techniques Machine Learning/ Statistics/ may be unsuitable due to Pattern AI – Enormity of data – High dimensionality of data – Heterogeneous, distributed nature of data Recognition Data Mining Database systems

Data Mining Tasks • Prediction Methods – Use some variables to predict unknown or future values of other variables. • Description Methods – Find human-interpretable patterns that describe the data.
![Data Mining Tasks (cont. ) • • • Classification [Predictive] Clustering [Descriptive] Association Rule](http://slidetodoc.com/presentation_image_h2/53f7169adec461faa17b1cd898f67b29/image-12.jpg "Data Mining Tasks (cont. ) • • • Classification [Predictive] Clustering [Descriptive] Association Rule")
Data Mining Tasks (cont. ) • • • Classification [Predictive] Clustering [Descriptive] Association Rule Discovery [Descriptive] Sequential Pattern Discovery [Descriptive] Regression [Predictive] Deviation Detection [Predictive]

Major Research Issues • Diversity of data mining tasks: Summarization, classification, clustering, association, trend and deviation analysis, pattern analysis, etc. • Interactive mining of knowledge at multiple concept levels • Efficiency and scalability of data mining algorithms • Handling multiple-source, different kinds of databases, such as relational, transactional, object-oriented, spatial, textual, multimedia, etc. • Smooth integration with the existing database and data warehousing systems, etc.

The KDD Process
 1. Learning the application domain 2. Creating a target")
The KDD Process (cont. ) 1. Learning the application domain 2. Creating a target dataset 3. Data cleaning and preprocessing 4. Data reduction and projection 5. Choosing the function of data mining 9 8 7 6 5 4 3 2 1 6. Choosing the data mining algorithm(s) 7. Data Mining 8. Interpretation 9. Using discovered knowledge

Data Mining • Involved fitting models to or determining patterns from observed data • The model plays the role of inferred knowledge • A wide variety and number of data mining algorithms have been proposed from the area of statistics, pattern recognition, machine learning, and databases

Mining Business Databases: Applications Marketing finance Telecom Banking Menufacturing

Data Mining/KDD: A Database Perspective

Classification of Data Mining Techniques • Different views: different classifications: – the kinds of knowledge to be discovered – the kinds of databases to work on – the kinds of techniques to be adopted • Knowledge to be mined: Summarization, association, classification, clustering, etc. • Databases to be mined: relational, transactional, object-oriented, textual, etc. • Techniques adopted: database-oriented, machine learning, neural network, statistics, etc.
 -->")
Mining different kinds of knowledge in large databases 1 Mining Association Rules buy(milk) --> buy(bread) 2 Data Classification classify data based on the values in a classifying attribute, e. g. classify cars based on model 3 Clustering cluster data to form new classes, e. g. cluster houses to find distribution patterns 4 Multi-Level Data Charcacterization Generalize, and Summarize

Mining Association Rules • The association task for data mining is the job of finding which attributes “go together”. Most prevalent in the business world , example for Basket dataset or Transaction dataset in grocer’s shop or departmentstore. • Example bread & butter ==> milk [support=5%, confidence=60%] beer ==> diapers [support=10%, confidence=80%]
 • A supermarket with a large collection of items,")
Mining Association Rules (cont. ) • A supermarket with a large collection of items, typical business decisions: – what to put on sale – how to design coupons, – how to place merchandise on shelves to – maximize the profit, etc. • Mining a large collection of basket data type transactions for association rules between sets of items with some minimum specified thresholds can improve the quality of business decisions

Mining Association Rules: Procedures There are two main steps in mining association rules 1. Find all sets of items (itemsets) that have transaction support above a threshold, called minimum support. Itemsets with minimum support are called frequent itemsets. 2. Use the frequent itemsets to generate association rules Most existing algorithms focused on the first step because it requires a great deal of computation, memory, and I/O, and has a significant impact on the overall performance

Finding the Frequent Itemset null Found to be Infrequent AB ABC Pruned supersets A AC ABD AD ABE ABCD Step 1 B C AE ACD BC BD D BE Why we find the Frequent Itemsets ABCE ADE ABCDE BCD ACDE E CD CE DE BCE BDE CDE BCDE

Finding the Association Rule • step 2 Form Association Rule is X Y By condition : X , Y I and X Y = • use the frequent itemsets from first step to fine association rule Bring the minimum support and confidence value of itemset to consider and find the interesting rule • Example of finding association rule : {Diaper} {Beer} Support value = 20% , Confidence value = 25%

Definition of Association Rules • I = {i 1, i 2, i 3} is set of alphabet or number in database, called ‘item’ • TID : index of each transaction • Itemset : a collection of one or more items • k-itemset : an itemset that contains k items • I = {Break, Milk, Diaper, Beer, Coke} • Support count ( ) : frequency of • E. g. ({Milk, Bread, Diaper}) = 2 • {AB, BC, CD} 2 -itemset occurrence of an itemset {ABC, BCD} 3 -itemset • Support : fraction of transactions that contain an itemset • E. g. S ({Milk, Bread, Diaper}) = 2/5
 • Minmum Support : user define this value")
Definition of Association Rules (cont. ) • Minmum Support : user define this value • Candidate k-itemsets : k-itemsets that have a interesting frequent for check them could be Frequent k-itemsets • Confidence : confidence of any rule have a value (percentage) or 0 -1 • Minimum Confidence : user define this value • Association Rules : an implication expression of the form X Y, where X and Y are itemsets

Support and Confidence • Measurement of rule strength in a transaction database A ==> B [support, confidence] support (AB) = confidence (A ==> B) = • We are interested in strong associations, i. e. , support minsup & confidence minconf

Efficient Methods for Mining Association Rules. 1 The Apriori algorithm (Agrawal & Skikant’ 94( • At the first iteration, scan all the transactions and count the number of occurrences for each items. This derives the frequent itemsets, L 1 • At the k-th iteration, the candidate set Ck are those whose every (k 1)-item subset is in Lk-1 is formed, scan a database and count the number of occurrences for each candidate k-itemset • Rule extraction: confidence derived from support Totally, it needs n database scans for n levels
 Apriori( through an itemset lattice Level x …")
Moving 1 level at a time) Apriori( through an itemset lattice Level x … Level )k(1+ Level k … Level 3 Level 2 Level l
 Item Bread Coke Milk Beer Diaper Eggs Minimum")
Example Small-Transaction Dataset Items (1 -itemsets) Item Bread Coke Milk Beer Diaper Eggs Minimum Support = 3 Count 4 2 4 3 4 1 Itemset {Bread, Milk} {Bread, Beer} {Bread, Diaper} {Milk, Beer} {Milk, Diaper} {Beer, Diaper} Count 3 2 3 3 Pairs (2 -itemsets) (No need to generate candidates involving Coke or Eggs) Itemset }Bread, Milk, Diaper{ Count 2
 Itemset }Bread, Milk, Diaper{ Count 2 Association Rule 1.")
Example Small-Transaction Dataset (cont. ) Itemset }Bread, Milk, Diaper{ Count 2 Association Rule 1. {Bread, Milk} {Diaper} 2. {Milk, Diaper} {Bread} 3. {Diaper, Bread} 4. {Bread} 5. {Milk} 6. {Diaper} E. g. {Milk} {Milk, Diaper} {Diaper, Bread} {Bread, Milk} confidence of {Bread, Milk} {Diaper} = support{Bread, Milk, Diaper} / support{Bread, Milk} = 2 / 3 = 0. 67
Savasere, et al. ’ 95( Divide a database")
Variations/extensions of Apriori • Partition algorithm )Savasere, et al. ’ 95( Divide a database into several partitions and then transform the database from horizontal layout to vertical layout which has an itemset along with a list of TIDs. The frequent itemsets are generated by intersection of two TID lists • Bitmap based algorithms) Gardarin, et al. ’ 98) Bitmap indexes are used to characterize itemsets in a database. Considering as the partition algorithm over the bitmap, a set of tidbits is constructed and then by using logical AND operation between two tidbits, frequent itemsets are generated
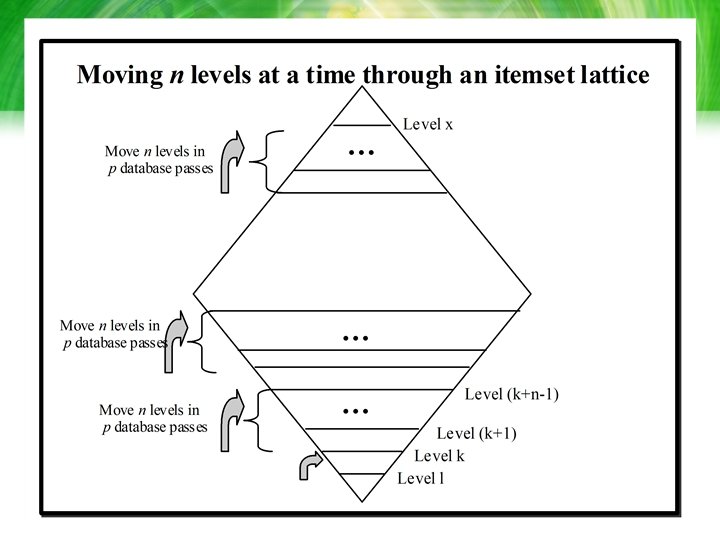
 Instead")
Variations/extensions of Apriori (cont(. • A parameterized algorithm (Denwattana, et al. ’ 01) Instead of moving one level of itemset lattice at a time, the (n, p) algorithm analyses n levels in p scans through an input data set, where p is less than n by using statistical information from input data set

Data Classification • A process which finds the common properties among a set of objects in a database and classified them into different classes, according to a classification model • To construct the classification model, a database is treated as the training set, in which each tuple consists of the same set of multiple attributes as the tuples in a large database and each tuple has a known class identity associated with it

Data Classification Task induction Training Set induction Test Set

Objective • To analyze the training data • To develop an accurate description or model for each class using the features available in the data • To classify future test data in the database by using the class descriptions • To develop a better description, called classification rules, for each class in the database

Classification based on decision trees • Decision tree learning is a method for approximating discrete-valued target functions, in which the learned function is represented by a decision tree • Decision trees can also be re-represented as sets of ifthen rules to improve human readability • Examples: ID 3, ASISTANT, C 4. 5 (used in machine learning( • Applications: medical diagnosis, performance prediction, etc.

An example of Decision tree

An example of Decision tree FIGURE A decision tree for the concept Play Tennis. An example is classification by sorting it through the tree to the appropriate leaf node, then returning the classification associated with this leaf (in this case, Yes or No). This tree classification Saturday mornings according to whether or not they are suitable for playing tennis.

An example of Decision tree

An example of Decision tree Outlook sunny overcast rain

An example of Decision tree

An example of Decision tree Outlook sunny humidity overcast Yes rain windy

An example of Decision tree

An example of Decision tree Outlook sunny humidity high normal No Yes overcast Yes rain windy

An example of Decision tree

An example of Decision tree Outlook sunny humidity overcast rain windy Yes high normal strong weak No Yes

Clustering Analysis Clustering or unsupervised classification is a process of grouping physical or abstract objects into classes of similar objects based on their features, which maximize intraclass similarity and minimize interclass simlarity Intra-cluster distances are minimized Inter-cluster distances are maximized

Possible Applications Marketing City-planning Applications Libraries Group genes and proteins

Types of Clusters Well-separated clusters Center-based clusters Contiguous clusters Density-based clusters Property or Conceptual Described by an Objective Function

Clustering Algorithm K-means Clustering 1 Partitioning algorithms 2 Hierarchical algorithms 3 Density-based algorithms 4 Grid-based algorithms
 Each point is")
K-means Clustering Each cluster is associated with a centroid (center point) Each point is assigned to the cluster with the closest centroid Number of clusters, K, must be specified K – Means Algorithm 1 Select K points as the initial centroid 2 repeat 3 Form K clusters by assigning all points to the closest centroid 4 Recompute the centroid of each cluster 5 until The centroids don't change

Choosing Initial Centroids

Clustering VS Classification Clustering maps a data item into one of several categorical classes (clusters) in which the classes must be determined from the data Classification maps (classifies) a data item into one of several categorical classes in which the classes are predefined

Multi-Level Data Characterization • Generalizing, summarizing, and browsing data at high or multiple abstraction levels and from different angles – Data in databases are often expressed at primitive levels – Knowledge is usually expressed at high level – Data may imply concepts at multiple levels: Narongsak CS grad student person

Multi-Level Data Characterization (cont(. • Mining knowledge just at a single abstraction level – Too low level -> Raw data or weak rules – Too high level -> Not novel, common sense • Mining knowledge at multiple levels: – provides different views and abstractions – progressively focuses on “interesting” spots and deepens the data mining process

Conclusion • Data Mining/KDD: a fast expanding filed with many new research results/systems/prototypes developed • The KDD field: a rich and promising with broad applications and many challenging research issues • Tasks: association, classification, clustering, characterization, etc. • Domains: relation, transaction, object-oriented, spatial, document, multimedia, WWW • Technology integration : – database, data mining, data warehousing technologies – other fields: machine learning, statistic, neural network, ect.

References 1. W. Frawley and G. Piatetsky-shapiro and C. Matheus, Knowledge Discovery in Databases: An Overview. AI Magazine, Fall 1992, pages 213 -228 2. M. Chen, J. Han, P. Yu. Data Mining: An Overview from Database Perspective, IEEE Transactions on Knowledge and Data Engineering, 1997 3. R. Agrawal, T. Imielinski, A. Swami. Database Mining: A Performance Perspective, IEEE Transactions on Knowledge and Data Engineering, Special issue on Learning and Discovery in Knowledge-Based Databases, Vol 5, No. 6, 1993 4. R. Agrawal and R. Srikant. Fast Algorithms for Mining Association Rules in Large Databases, Proceedings of the 20 th International Conference on Very Large Data Bases, Sep 1994
 5. Communication of The ACM. Vol. 39, No. 11, Nov 1996")
References (cont. ) 5. Communication of The ACM. Vol. 39, No. 11, Nov 1996 6. T. M. Mitchell. Machine Learning: Decision Tree Learning, Mc. Graw-Hill, 1997 7. A. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for mining association rules in large databases, In Proceedings of the 21 st VLDB Conference, Zurich, Swizerland, 1995 8. F. Fardarin, P. Pucheral, F. Wu. Bitmap based algorithms for mining association rules, In Actes des journes Bases de Donnes Avances (BDB 98), Hammamet, Tunisie, Oct 1998
- Slides: 61