Introduction to Data Mining Date 26 th February

Introduction to Data Mining Date: 26 th February 2016 Special thanks: Han & Kamber

Syllabus Topics �Introduction �Classification of Data Mining System �Data Mining Architecture �Data Mining Functionalities �Major Issues in Data Mining �Importance of Data Mining �Application of Data Mining �Social Impacts of Data Mining

Introduction Data? ? ? � Information? ? ? Database? ? ? DBMS? ? ?

Introduction Data Structured : DBMS Dhaval Gohel 40 50 60 Rishabh Chauhan 60 70 80 Mayur Padiya 70 60 80 Ankit Prajapati 30 40 50 Viral Prajapati 80 90 70 Unstructured: text Dhaval Gohel, 40, 50, 60 Rishabh Chauhan 60, 70, 80 Semi –structured: XML <Name>Dhaval Gohel</Name> <CA>40</CA> <IP>50</IP> <CS>60</CS>

Introduction Information �Dhaval Gohel have 50% in current Sem. �Viral Prajapati have highest marks in Reaserch Skill. �Ankit Prajapti have lowest marks in CA.

Introduction Data base 120160107001 Dhaval Gohel Dakor 120160107002 Rishabh Chauhan Modasa 120160107004 Mayur Padiya Nadiyad 120160107007 Ankit Prajapati Dehgam 120160107008 Viral Prajapati Naroda Dhaval Gohel 40 50 60 Rishabh Chauhan 60 70 80 Mayur Padiya 70 60 80 Ankit Prajapati 30 40 50 Viral Prajapati 80 90 70

Introduction DBM S

Introduction �Data: row facts �Information: �Database: processed data collection of organized related data �DBMS: set of software and tools used manipulate the database

What do you mean by Data Mining? �Data Mining: “ Data Mining is the process of discovering interesting knowledge from large amount of data stored in databases, data warehouses, or other information repositories. “ � Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc.
 in databases (KDD) � knowledge")
Different Names of Data Mining � Knowledge discovery (mining) in databases (KDD) � knowledge extraction � data/pattern analysis � data archeology � data dredging � information harvesting � business intelligence, etc.

Database vs Data Mining � Database: - Find all employee having salary >=50, 000 - Find all the student who have attendance 0% last month - Find all the Student who have Apple Laptop � Data Mining: - Find all employee who is contractual (Classification) - Find all the student who have attending lectures (Clustering) - Find all the Student who have Apple Laptop and Apple Phone (Association Rule)

Classification of Data Mining System �Database technology �Information Science �Statistics �Machine Learning �Visualization �Other disciplines

Integration of Multiple Technolgy Information Science Machine Learning Database Technology Statistics Visualization Algorithms Data Mining

Classification of Data Mining System �Classification is based on �Kind of database Mined: • Data model like relational, transactional, object- relational, or data warehouse. • Special types of data handled like spatial, time series, text, stream data, multimedia data mining system, or a World Wide Web mining system.

Classification of Data Mining System �Kind of knowledge Mined • Data Mining functionalities like Characterization and Discrimination, Mining Frequent Patterns, Classification and Prediction, Cluster Analysis, Outlier Analysis, Evolution Analysis • Data regularities vs data irregularities

Classification of Data Mining System �Kinds of techniques utilized • Degree of user iteration involved e. g. , autonomous systems, interactive exploratory systems, querydriven system • Method of data analysis employed e. g. , databaseoriented or data warehouse oriented techniques, machine learning, statistics, visualization, pattern recongnization, neural networks, and so on.

Classification of Data Mining System �Application adapted • Finance, telecommunication, DNA, stock markets, e-mail and so on.

Knowledge Discovering form Data Pattern Evaluation Data Mining Pattern Task-relevant Data transformations Preprocessed Data Cleaning Data Integration Databases Selection and Transformation

KDD Process steps � � � Cleaning: remove noise and inconsistent data Integration: where multiple data sources may be combine Selection: Data relevant to the analysis task are retrieved from the database � Transformation: Data are transformed into appropriate form for mining. Summary or aggregation operations � Data Mining: Various techniques like Association rule mining, Classification, Clustering are apply to Identify and count patterns � Pattern Evaluation: Identify truly interesting patterns representing knowledge base on some interestingness measure. • For example Support and Count for Association Rule Mining � Knowledge Presentation: Visualization and knowledge representation techniques are used to present the mined knowledge to the user

KDD Process on Web Log Data
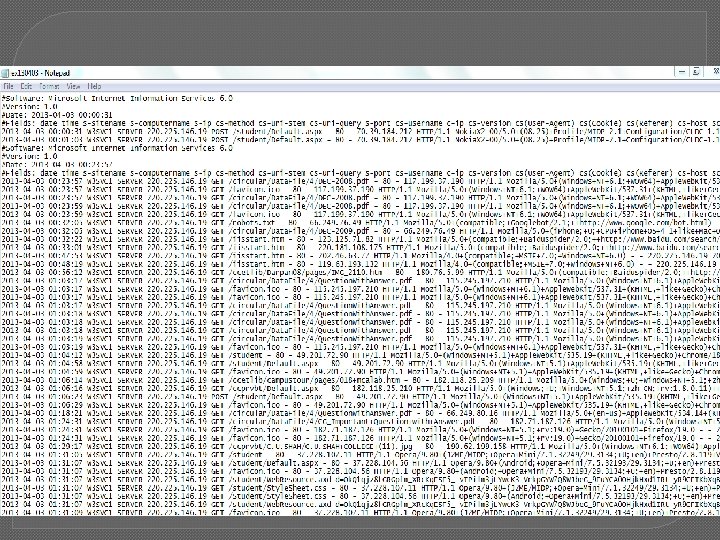

KDD Process on Web Log Data � � � � Cleaning: remove error logs Integration: multiple logs may be combine Selection: Data having valid Status and Media type is selected Transformation: Transfer data to day wise, week wise Data Mining: Identify Pattern and count frequent access Pattern Evaluation: Display frequently access sequences Knowledge Presentation: url page wise user count graph, IP address wise number of page visited count graph

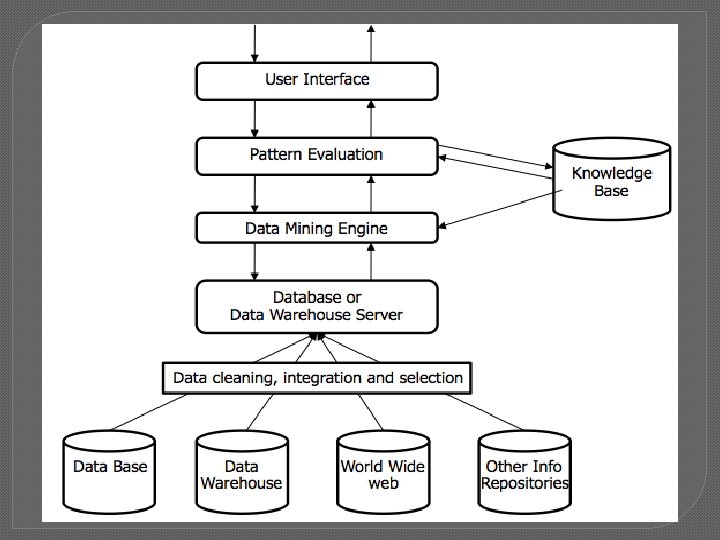
Data Mining Architecture �Components 1. Databases, Data warehouse, World Wide Web or other Information repository 2. Database or Data warehouse server 3. Knowledge base 4. Data mining engine 5. Pattern Evaluation Module 6. User Interface

Data Mining Functionalities �Data Mining functionalities are used to specify the kind of patterns to be found in data mining tasks. �Task: Descriptive and Predictive �Descriptive: General Properties of data and database �Predictive: Perform inference (Conclusion) on the current data

Data Mining task

Data Mining Functionalities 1. 2. 3. 4. 5. 6. Characterization and Discrimination Mining Frequent Patterns Classification and Prediction Cluster Analysis Outlier Analysis Evolution Analysis

Characterization and Discrimination � Data Characterization is a summarization of the general characteristics or features of a target class of data. � For example: to analyze the improvements of the students who study in 2 nd Semester ME in GECM and whose marks increased 5% in the current semester. � Display forms: pie charts, bar multidimensional data cubes etc. . charts,

Characterization and Discrimination � Data Discrimination is a comparison of the general features of target class data objects with the general features of objects from one or a set of contrasting classes. � For example: faculties may like to compare the results of students who study in 2 nd Semester ME in GECM and whose marks increased 5% and decreased 5% in the current semester. � Display forms: pie charts, multidimensional data cubes etc. . bar charts,

Mining Frequent Patterns, Association Rule Mining �Frequent patterns are patterns that occur frequently in data set. �Forms: Frequent itemsets, subsequences, and substructures. �Frequent itemsets: ex. milk and bread. �Subsequence: ex. PC followed by Soft. �Substructure: sub graph, tress, or lattices

Mining Frequent Patterns, Association Rule Mining � Association Rule Mining is method use to find the interesting frequent pattern from large set of data items. � computer antivirus [support=2%, Confidence=60%] � Support means that 2% of all the transactions in which computer and antivirus purchased together. � Confidence 60% means 60% of customers who purchased a computer also purchased antivirus together
")
Classification and Prediction � Classification is the process of finding a model (or function) that describes and distinguishes data classes or concepts. The model is derived based on the analysis of a set of training data and is used to predict the class label of objects for which the class label is unknown. � Classification is a two phase process 1) Lerning: Training data are analyzed by classification algorithm. 2) Classification: Classify data into the class lable. � �

Classification and Prediction values continuous valued functions, i. e. it is used to predict missing or unavailable numeric data values rather than class labels. Regression analysis is a statistical method used numeric prediction. Dhaval Gohel 40 50 60 Pass Rishabh Chauhan 60 70 80 Pass Mayur Padiya 70 30 80 Fail Ankit Prajapati 30 40 50 70 80 Rishabh Chauhan Prediction Pass Classification

Classification and Prediction

Cluster Analysis Clustering analyzes data objects without consulting class labels. Clustering can be used to generate class labels for a group of data which did not exist at the beginning. The objects are clustered or grouped based on the principle of maximizing the intra-class similarity and minimizing the inter-class similarity.

Outlier Analysis Outliers are data objects that do not comply with the general behavior or model of data. The analysis of outlier data is referred to as outlier mining. Many data mining techniques discard outliers or exceptions as noise. However, in some events these kind of events are more interesting. This analysis of outlier data is referred to as outlier analysis ex: fraud detection.

Evolution Analysis Data evolution analysis describes and models regularities or trends for objects whose behavior changes over time. This may include characterization, discrimination, association and correlation analysis, classification, prediction or clustering of time related data. Distinct features of such data include time series data analysis, sequence or periodicity pattern matching and similarity based data analysis.

Importance of Data Mining �Data collected in large data repositories become “data tombs”. �Data Mining tools perform data analysis and my uncover important data patterns, contributing greatly to business strategies, knowledge bases, and scientific and medical research. �Data Mining tools turns data tombs into “Golden nuggets” of knowledge.

Application of Data Mining �Market analysis �Fraud detection �Customer retention �Production control �Science exploration

Major Issues in Data Mining 1. Mining different kinds of data 2. Handling multiple levels of abstraction 3. Incorporation of background knowledge 4. Visualization of mining results 5. Handling of incomplete or noisy data 6. Scalability of algorithms

Social Impacts of Data Mining �Privacy �Profiling �Unauthorized use
- Slides: 41