Introduction to BioStatistics Dr N Srinivasa Murthy Ph

Introduction to Bio-Statistics Dr. N Srinivasa Murthy, Ph. D, FAMS, FSMS. Professor and Research Director, DRP, GEF(M) and Professor and Research Coordinator, MS Ramaiah Medical College and Hospitals, Bangalore-560054 nsmurthymsrmc@gmail. com 1

Lessons to be learnt To understand importance of Bio Statistics in Bio medical studies Steps in the design of bio medical research studies. Sample size estimation Presentation and interpretation of data Books for reference

…. . 11/4/2020 3

What is Statistics? Lay man: Impression about numerical facts. : Scientific worker ?

Science of Statistics deals with: Scientific manner : v Methodology of collection, compilation, analysis and meaningful interpretation of numerical facts. v. Analysis of variability present in the observations (variation is a rule rather than an exception) v. Subjecting the factual descriptions to objective tests to validate their reliability v. Understanding the contribution through model building-risk factor models, prognostic factors, etc. , 11/4/2020 5

Ex. Numerical facts Pulse rate, Haemoglobin percentage Birth weight of a new born child. Creatinine levels, WBC, RBC, Odds ratio, relative risk, Attributable risk, Five year survival rate, Disease prediction models Risk scores for classifying persons likely to develop CVD, Br. Cancer, etc.

Birth weight of new born child Affected Gestation week Nutritional status of a mother Parity, No. ANCs attended, Co morbidities etc. , Affected to a large extent Biological, Social, environmental, genetic factors, How to segregate and assess the importance? Analytical statistical Procedures, Cause and effect

Statistical methods helps in biomedical studies to take care of Control of Bias Evaluating the role of chance factor Evaluating the role of confounding

CONTROL OF BIAS Careful study design Appropriate Choice of study of population Appropriate methods of data analysis Appropriately defining sources of exposure and disease information Meticulous conduct of study.

How to measure the chance factor? Evaluating the role of chance factor Scientific assessment of random variability is predominantly done by tests of statistical significance. p value Deals with the question of whether an observed difference between the sample estimates is due to chance or a real effect

Control of confounding Multivariate statistical analysis

Basic steps in formulation of research protocol i. Definition of a research problem ii. Formulation of objectives & hypothesis iii. Methodology of research & study design Iv. Selection of variables v. Designing tools for data collection vi. Def. study population, sample, controls, inclusion & exclusion criterion, adequate sample size and time coverage vii. Analytical methods of data collection viii. Various sources of error & rectification

Bio-medical research Experimental Observational Provide rates. Defining population is important Prevalence or incidence Crosssectional study: observed at one point in time Longitudinal study: observed over a period of time Provide association between variables. Defining Cause andis population effect not important Casecontrol study Backward in time Prophylactic Therapeutic effectiveness of vaccinee effectiveness of treatment Cohort study Forward in time Effectivenes s intervention s Ethical principles Sequential FIG. . Types of research studies Intervention Non-sequential

Sample size estimation • One of the most frequently asked questions at the time of planning of any research study is: • how large a sample do I need ? • for a specific research study.

Sample size consideration • Constraints on small numbers studied. • Sample size must be decided based on statistical methods. • Adequate statistical power should be present.

• Example • Treatment efficacy once a week versus once every 3 weeks cisplatin chemo radiation for locally advanced head and neck cancer: • Loco regional control (LRC) once a week at the end of 2 year =58. 5%, • (LRC) once every 3 weeks at the end of 2 year : =73. 5%. • Experimental research, to utilise for patient care &publish • To compare the efficacy and safety

NEED Why Sample size calculation The main idea behind the sample size calculations is: i) to have a high chance (Prob. ) of detecting a statistically significant, a worthwhile effect if it exits, _ Power of the study False negative conclusion (beta error) 10 20% i) and thus to be reasonably sure that no such benefit exists if it is not found in the trial. False positive conclusion (Alpha error) <=5%

Types of statistical Errors TRUTH EFFECT No Error NO EFFECT No Error Type II Error False Negatives. STUDY CONCLUSION NO EFFECT Error Type I Error False Positive. No Error

Ø The greater the power of the study, the more sure we can be but greater power requires a larger sample. Ø It is common to require a power of between 80% and 90%. A power of 90% means that the investiga tor has a 10% chance of accepting the null hypoth esis, that there is no difference, when there is really a difference of a specified size between the rates of the two treatments.

Sample SIZE Too small? Ø If the number of observations is too few, the investigator may not have enough to test the hypothesis Ø A study with a sample that is too small will be unable to detect clinically relevant treatment differences.

Requirements for estimation of Size of the sample Approximate idea of the estimate of the parameter under observation. Variability of this parameter from unit to unit in the population. Desired accuracy of the estimate of the parameter Prob. level within which the desired precision of estimates Availability of the experimental material, resources and other practical considerations

Presentation and interpretation of data

Basic methods of Presentation & analysis of data Presenting through tables Graphical presentation Measures of central tendency Measures of dispersion Probability and standard distributions Normal distribution Sampling methods, Sampling variation and tests of significance Correlation and regression, Multivariate methods, etc.

Tabulation of data Descriptive Statistics: Central tendency and dispersion Probability distributions: Normal Distribution Sampling Variation Analytical Statistics: Tests of significance 1. Comparison of Means 2. Comparison of Proportions

How to summarize my results through descriptive tables Raw data as recoded in a proforma/records will not be of any much help in understanding their meaning. A preliminary and convenient way of presentation of data is to arrange them in the form of tables.

• A study was carried out to test the hypothesis that intramuscular and iron therapies during pregnancy are equally effective in improving various iron variables. • The objective was (i) to compare the efficacy of 3 intramuscular doses (250 mg each) of iron dextran with that of 100 consecutive days of 100 mg Fe given orally in treating pregnancy anemia. • (ii) the study also attempted to asses the safety and complications of the 2 treatments. • Am J Clin Nutr 2004, 116 -22, A Prospective , partially Randomized study…. . pregnant women. Sharma JB, …. Murthy NS.

Sample of pregnant mothers Hb term Oral recruit Oral Term Parenteral recruit Parenteral 70 64 measurements 99 65 72 65 90 84 65 84 108 86 76 86 102 87 56 87 104 78 54 78 104 86 76 86 98 90 77 90 99 98 67 98 97 87 66 87 98 99 70 64 99 65 72 65 90 84 65 84 108 86

Distribution of hemoglobin concentration in the 2 groups before and after treatment Haemoglo Oral iron group bin(g/L) (N=100) Recruit. Term ment % <90 23 10 90 -99 35 23 100 -109 42 40 ≥ 110 27 Parenteral iron group (N=100) Recruit- Term ment % 33 7 26 18 41 45 30
")
Birth outcomes in the 2 groups Variable Term delivery Oral iron Parenteral group (N=100) iron group (%) (N=100) (%) 86 87 Preterm delivery 14 13 Normal vaginal delivery 87 85 Instrumental delivery 3 4 Cesarean section 10 11

Statistical Methods Estimation Point Estimation Interval Estimation Testing of Hypothesis Parametric Non-parametric

Point and interval estimates

Measures of Central Tendency For Quantitative data: Mean which is mostly arithmetic average Even though there are other averages Median which is the central value of observations when they are arranged in ascending or descending order, Used when there are extreme values of observations Mode is the value of the variable most commonly occurring in the data

For Qualitative, categorical, nominal data: Proportions or percentages Odds ratios Relative risk

Common measures of Dispersion Range to indicate the Minimum & Maximum values of data Percentile to indicate the value of the variable covering certain percent of observations If we say 75 th Percentile, it is the value of the variable which covers first 75 % of the observations
 Best measure of variability of observations Calculated as")
Standard deviation ( S. D. ) Best measure of variability of observations Calculated as the square root of Variance, which is the average of squared differences of each observation from the mean S. D. is used in almost all other statistical calculations


Blood index values at recruitment and at term in the 2 groups Oral iron group (100) Parental iron group (100) Recruitment Term Hemoglobin (g/L) 96. 3 ± 8. 79 102. 9 ± 10. 84 94. 3 ± 9. 47 104. 2 ± 10. 98 Hematocrit PCV (%) 31. 0 ± 3. 51 36. 3 ± 4. 88 30. 2 ± 3. 11 35. 5 ± 5. 47 MCV (f. L) 84. 3 ± 7. 24 100. 9 ± 11. 23 82. 3 ± 7. 44 98. 9 ± 13. 77 MCH (pg) 27. 5 ± 3. 36 28. 6 ± 3. 37 27. 3 ± 3. 86 28. 8 ± 3. 68 MCHC (g/L) 309. 2 ± 32. 96 282. 6 ± 29. 17 309. 9 ± 33. 29 291. 8 ± 30. 87 Serum iron (μmol/L) 34. 3 ± 1. 50 36. 5 ± 1. 60 25. 0 ± 1. 90 27. 8 ± 1. 71 Serum iron (μmol/L) 113. 0 ± 1. 52 115. 4 ± 1. 81 105. 7 ± 1. 88 98. 8 ± 1. 68 Serum iron (μmol/L) 7. 5 ± 1. 84 12. 4 ± 2. 02 7. 0 ± 1. 67 23. 1 ± 2. 27 Variable
 Used to compare the variability between different")
Co-efficient of Variation ( C. V. ) Used to compare the variability between different groups measured in different units Calculated as C. V. = (Standard Deviation x 100 ) / Mean

Interval Estimates Confidence intervals gives a range for the statistical parameter, indicating that the true value of the parameter is contained in the range with a certain confidence 95% confidence interval of mean gives a range which indicates the true value of the mean is within the range with 95%

SAMPLING VARIATION Variation in Sample estimates, even if the samples drawn are from the same population -Chance factor - Random Variability
 of a sample of 25 individuals are as")
Question? ? The clotting time (seconds) of a sample of 25 individuals are as follows: 20, 21, 31, 42, 32, 10, 22, 23 26 19, 18, 21, 38, 27, 24, 27, 44, 59, 62, 45, 37, 44, 54, 29, 50

Sample No. 1 2 3 4 5 Overall Sample size 15 17 16 11 10 25 Mean SD 33. 40 29. 29 27. 06 36. 73 41. 60 32. 04 14. 07 13. 10 11. 59 12. 49 15. 33 15. 13

Thus we observe variation in sample estimates even if samples are from the same population This variation in sample estimates is known as Sampling variation Measure of this Sampling variation is known as Standard Error can be estimated from standard deviation obtained by a single sample

Whenever observations are made on two or more samples it is necessary to understand whether the differences observed between the sample estimates are due to sampling variation or not Procedure adopted for this purpose is known as Tests of significance

First we assume that the difference observed is because of sampling variation For this we formulate a hypothesis known as Null Hypothesis Null hypothesis is stated as the difference between the sample estimates is due to sampling variation

n Certain tests are applied to prove or disprove this null hypothesis n These tests provide an estimate of the probability of sampling variation causing the difference between the sample estimates i. e. Accepting the null hypothesis n P value-Probability level of accepting a null hypothesis is known as Level of significance

How to measure the chance factor?

Scientific assessment of random variability is predominantly done by tests of statistical significance. p value Deals with the question of whether an observed difference between the sample estimates is due to chance or a real effect

Tests of Significance provide an estimate of the Probability, P, Which helps us to conclude whether differences observed between the samples are attributable to sampling variation or otherwise If this Probability is P < 0. 05, then we conclude that the difference between sample estimates not due to random variability

General procedure for testing of a hypothesis Set up a null hypothesis suitable to the problem either in qualitative or quantitative terms. Define the alternate hypothesis, if necessary Calculate the suitable test statistics, t, 2, F etc using the relevant formula. Determine the degrees of freedom for the test statistics. Find out the probability level, P, from relevant tables corresponding to the calculated value of the test statistics and its degrees of freedom. Generally, reject the null hypothesis, if P is less than or equal to 0. 05

Which are the Tests of Significance available ? Tests which can be applied depends on the Type of data, size of sample, Type of distribution,

Tests of statistical significance. Several tests such as t, z, x 2, analysis of variance etc. to know the extent of the chance in terms of p value. Choice of appropriate test depends on the sample size, type of data and the hypothesis being considered
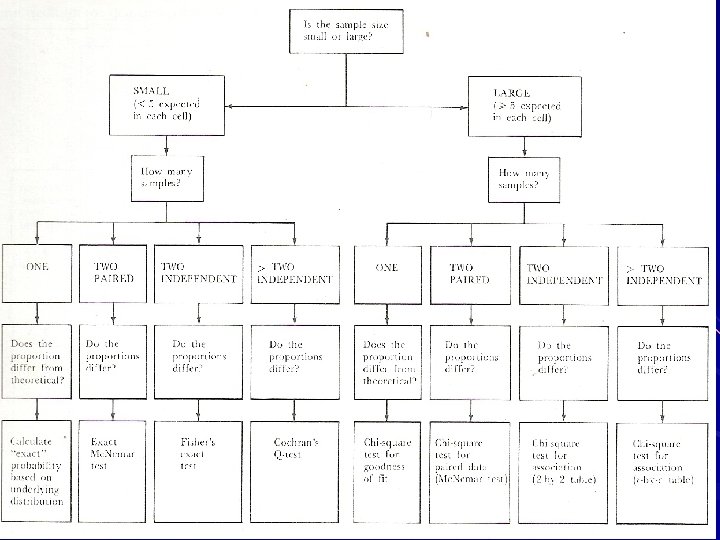
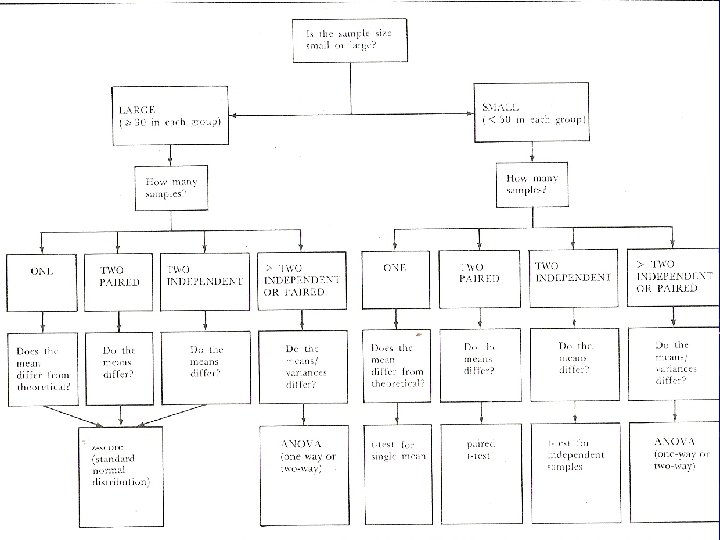

TYPES OF TESTS PARAMETRIC TESTS Tests based on certain parameters like Mean, S. D. or Proportions Assumption to apply these tests: Observations follow a particular type of Probability distributioin

LARGE SAMPLE TESTS When the number of Observations is over 30 Z-TEST Applied either for Means or Proportions Assumption data follows a Normal distribution

SMALL SAMPLE TESTS Students t-test Paired t-test When the experiment is conducted as Before and After trial on the sample Independent sample t-test When the experiment is conducted on two independent samples In both the cases assumption is that the observations are distributed Normally
")
F-test To test the differences in variances between two groups Analysis of variance (ANOVA) To compare means between more than two groups simultaneously Tested using F-test After applying ANOVA, if the means are significantly different, Post-hoc tests to compare between two groups can be done

NON-PARAMETRIC TESTS Tests carried out when no parameters are involved When no assumption can be made about the distribution pattern of observations Chi-Square test To test the association between variables

Fisher’s exact probability When the number of observations are small in different groups, to find the exact probability of a certain number of observations in a particular cell in 2 X 2 table

Mann-Whitney U-test To compare observations when they are made before and after treatment on the sample Wilcoxon test To compare observations when they are made on two independent samples Kruskal Wallis test To compare observations when they are made on more than two independent samples

CORRELATION AND REGRESSION TECHNIQIES CORRELATION TECHNIQUE Methodology to understand the relationship between two variables measured on the same unit Relationship measured as Correlation Co-efficient represented by letter ‘r’

REGRESSION TECHNIQUE If Correlation Co-efficient is Significant and not spurious, Dependent variable can be estimated in terms of Independent variable Rate of change of dependent variable for unit change in independent variable Is known as Regression Co-efficient Represented by ‘b’ Univariate Linear Regression equation

Control of confounding Multivariate statistical analysis

COMMONLY USED MODELS IN MEDICAL FIELD – 1. Multiple Linear regression models – 2. Logistic regression models – 3. Cox proportional hazards models – 4. Discriminant analysis

Regression equations will be in terms of multiple independent variables Multiple Regression equation Multivariate Linear Regression Equation Y= a + b 1 x 1 + b 2 x 2 + b 3 x 3 +……….

Suggested book on Statistics Applied Statistics in Health Sciences, JAYPEE Brothers, New Delhi, Bangalore. Epidemiology in Medicine. Hennekens CH, et al. , Little, Brown and Co. Boston/Toronto.

It is not enough if you learn swimming staying on the banks; one needs to get into the pool to actually swim

- Slides: 69