Introduction lconomtrie Septembre octobre 2019 Malys de la

Introduction à l’économétrie Septembre- octobre 2019 Maëlys de la Rupelle

Plan du cours • • Rappels de probabilité Rappels de statistiques Introduction à l’économétrie et aux données Régression linéaire simple : estimation Régression linéaire simple : inférence Régression linéaire multiple: définition Régression linéaire multiple: inférence

Trois outils • Estimation • Intervalles de confiance • Tests d’hypothèses

Intervalles de confiance. • Si suit une loi normale de moyenne m et de variance s 2/n, alors : P(-1. 96 < ( -m ) / ( s/ ) < 1. 96)=0. 95 P( < m < )=0. 95

Intervalles de confiance • On obtient ainsi un intervalle de confiance à 95 % de m • Un intervalle de confiance à 95 % de m est un intervalle aléatoire qui contient m avec une probabilité de 95% avant de tirer l’échantillon.

Quand la variance n’est pas connue • On doit utiliser une estimation de s. • On utilise s, l’écart-type empirique. s=[S(Yi- )2/(n-1)]^0. 5

Quand la variance n’est pas connue • Si on utilise s, on ne conserve plus les mêmes seuils. Si on remplace s par s dans l’expression de la moyenne empirique centrée réduite, on obtient une statistique qui suit une loi de Student à n-1 degrés de liberté, et non plus une loi normale centrée réduite.

Intervalles de confiance • Pour construite l’intervalle de confiance, on a besoin du 97. 5 e centile de la distribution tn-1, que l’on appelle c. • On obtient alors l’intervalle suivant:

Intervalles de confiance

Intervalles de confiance •

Tests d’hypothèse • Exemple : la taille des classes influence-t-elle les résultats scolaires? • On compare deux groupes d’écoles, petites classes vs grandes classes. On calcule la moyenne des résultats scolaires pour chacun de ces groupes les moyennes sont-elles différentes?

Un exemple pour commencer… • Une société d’autoroutes gère ses bornes à péage par ordinateur. Il y a 11 couloirs, numérotés de 0 à 10. • L’ordinateur enregistre le nombre de voitures qui passent dans chaque couloir. • En l’absence de problème technique, elle connaît la distribution des couloirs choisis par les automobilistes.

A quoi ressemble la distribution?
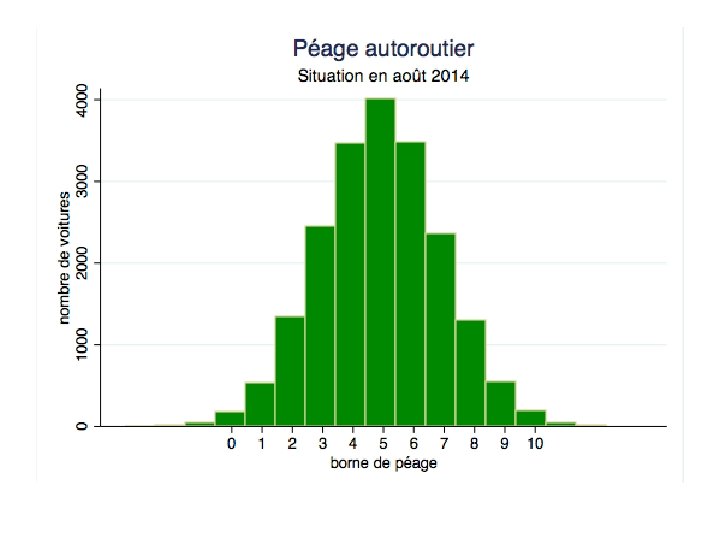

Densité de probabilité

Ce qu’on observe en septembre 2016 • Soit X le numéro de couloir choisi par la voiture. • A la fin de la journée, on observe la moyenne empirique de X. • Habituellement, quand aucune borne n’a de problème, la moyenne est égale à 5. • Moyenne de 6 lors de la dernière mesure qu’en conclure?

Quelle conclusion en tirer? • En août 2015, il y avait deux bornes en panne, la moyenne observée était de 6.
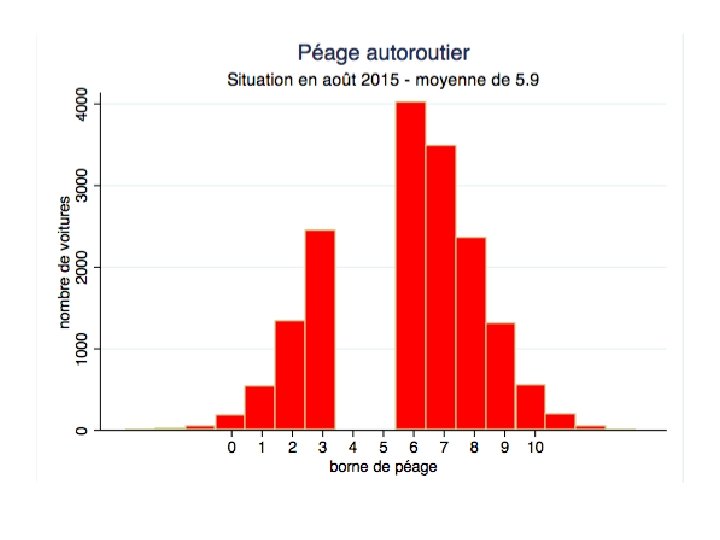

Quelle conclusion en tirer? • En août 2015, il y avait deux bornes en panne, la moyenne observée était de 6. • Mais la mesure qui a été faite se base sur un petit nombre d’observations (20). • Plusieurs scénarios sont possibles
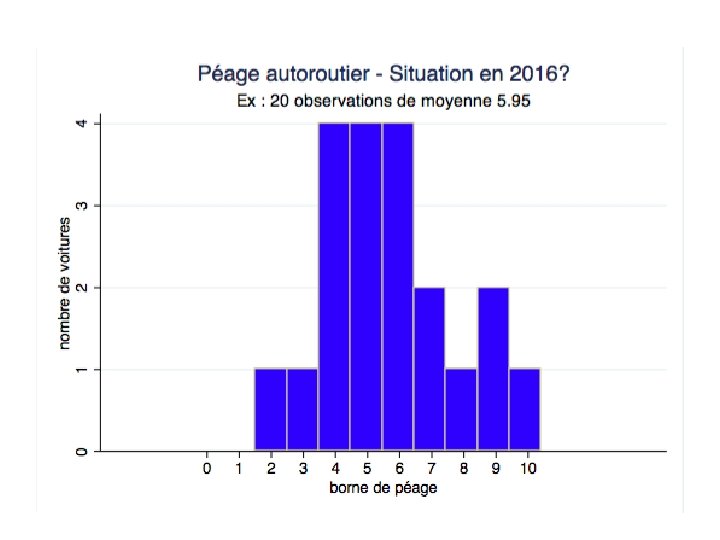
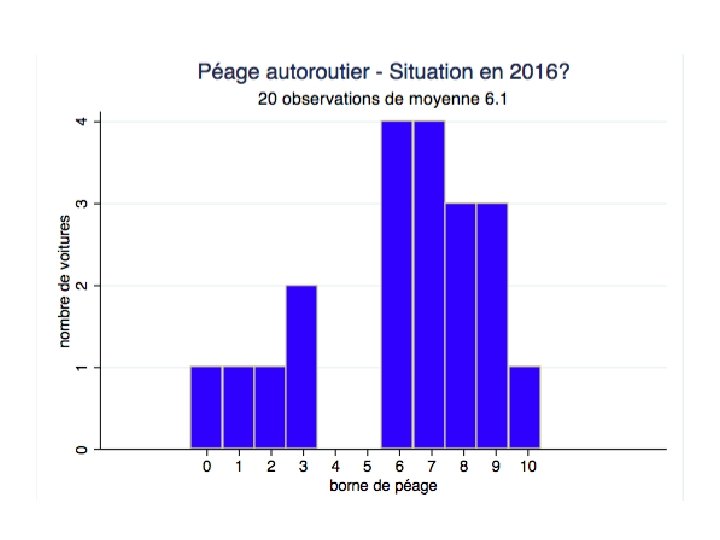

De l’observation au test • Quelle est la « vraie » distribution? • Sous certaines hypothèses (=Ho), on connaît la distribution empirique Si toutes les bornes fonctionnent, la distribution du numéro de la borne choisie suit une loi normale de moyenne 5 (qu’est-ce que cela implique? ) • L’observation est-elle compatible avec cette distribution?

Procédure de test • Comment choisir Ho L’hypothèse nulle est présumée vraie jusqu’à ce que les données indiquent clairement le contraire Un test fait pour rejeter Ho. Quand connaît-on la distribution de X? • Ici, Ho: Aucune borne n’a de problème. m. X=5 Ha : m. X≠ 5

De l’observation au test • Quelle chance a-t-on d’observer une moyenne de 6 alors qu’aucune borne n’a de problème? • D’observer un écart de 1 ou plus à la moyenne si la moyenne de la population est 5? (ie d’observer une moyenne ≥ 6 ou ≤ 4)? p-valeur • Quelle erreur est-on susceptible de faire en concluant qu’il y a panne alors qu’il n’y en a pas? Risque de première espèce
:")
Erreurs de type I et de type II • Erreur de type I (a): On rejette Ho alors qu’elle est vraie • Erreur de type II (b): On ne rejette pas Ho alors qu’elle est fausse. • Quelle chance a-t-on de commettre une erreur de type I? • Le test est-il puissant?

Un autre exemple Etonnée par les remarques désobligeantes de ses collègues sur son tour de taille, une personne cherche à en comprendre l’origine. Elle fait le test suivant : Ho : cette personne n’est pas enceinte. Ha : cette personne est enceinte

Un autre exemple Ho : la personne n’est pas enceinte. Ha : la personne est enceinte • Erreur de type I : On rejette Ho alors qu’elle est vraie On conclut à la grossesse alors qu’il n’y en a pas • Erreur de type II : On ne rejette pas Ho alors qu’elle est fausse. On conclut à l’absence de grossesse alors qu’il y en a une.

Ho : absence de grossesse

Puissance : 1 -b • Le test est-il puissant? Le test fait pour rejeter Ho; plus il est puissant, plus on rejette Ho quand elle est fausse plus on conclura qu’il y a grossesse en présence de grossesse / plus on conclura qu’une borne a un problème lorsqu’il y a un problème. • La puissance = 1 - l’erreur de type II
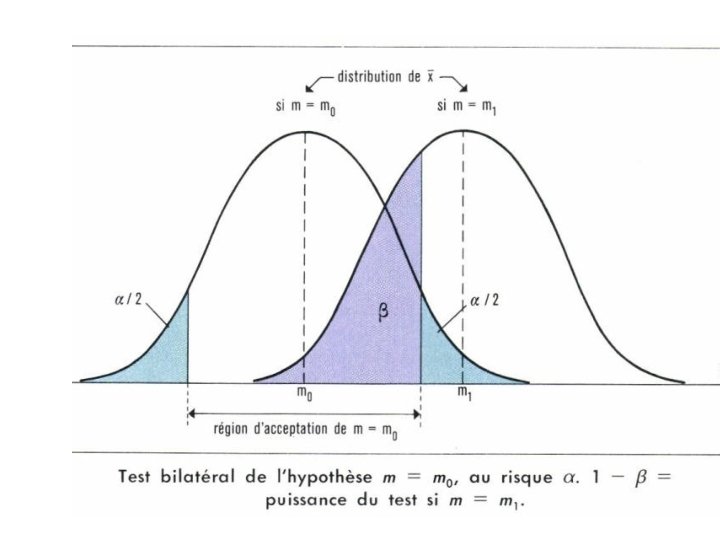

Risque de première espèce: a Quand on définit un test, on définit souvent a priori l’erreur de première espèce maximale qu’on tolère. On appelle cela le seuil de significativité, ou encore le seuil de confiance. Les règles des test d’hypothèses sont établies de façon à ce que la probabilité de commettre une erreur de type I soit plutôt faible. Tester au seuil de confiance de 5%, c’est faire un test où la probabilité de rejeter Ho alors qu’elle est vraie est de 5%.

Test d’hypothèse sur la moyenne dans une population normale • t, la statistique de test, qui vaut tobs pour un échantillon particulier • Règles qui précisent les conditions de rejet de H 0 comparaison de la statistique de test à une valeur critique, c • Région de rejet : l’ensemble des valeurs de tobs qui conduisent à rejeter l’hypothèse nulle

La p-valeur • Si on choisit un seuil de significativité différent, la conclusion peut être différente • Quel est le seuil de significativité le plus petit auquel H 0 est encore rejetée? • Quel est le seuil de significativité le plus grand auquel H 0 n’est toujours pas rejetée? • Le seuil de significativité auquel nous sommes indifférents entre rejet et non rejet est appelée la « p-valeur » du test.

La p-valeur • Une petite p-valeur est une preuve en défaveur de H 0. Si H 0 est vraie, la p-valeur mesure la probabilité d’observer un tel résultat à partir des données disponibles. • Ainsi, plus la p-valeur est proche de 0, moins l’hypothèse nulle est plausible. • Au contraire, une p-valeur élevée est une preuve en faveur de H 0.
- Slides: 35